 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraDE: A Graph Diffusion Estimator for Frequent Subgraph Discovery in Neural Architectures
Feb 03, 2026Finding frequently occurring subgraph patterns or network motifs in neural architectures is crucial for optimizing efficiency, accelerating design, and uncovering structural insights. However, as the subgraph size increases, enumeration-based methods are perfectly accurate but computationally prohibitive, while sampling-based methods are computationally tractable but suffer from a severe decline in discovery capability. To address these challenges, this paper proposes GraDE, a diffusion-guided search framework that ensures both computational feasibility and discovery capability. The key innovation is the Graph Diffusion Estimator (GraDE), which is the first to introduce graph diffusion models to identify frequent subgraphs by scoring their typicality within the learned distribution. Comprehensive experiments demonstrate that the estimator achieves superior ranking accuracy, with up to 114\% improvement compared to sampling-based baselines. Benefiting from this, the proposed framework successfully discovers large-scale frequent patterns, achieving up to 30$\times$ higher median frequency than sampling-based methods.
Younger: The First Dataset for Artificial Intelligence-Generated Neural Network Architecture
Jun 20, 2024



Designing and optimizing neural network architectures typically requires extensive expertise, starting with handcrafted designs and then manual or automated refinement. This dependency presents a significant barrier to rapid innovation. Recognizing the complexity of automatically generating neural network architecture from scratch, we introduce Younger, a pioneering dataset to advance this ambitious goal. Derived from over 174K real-world models across more than 30 tasks from various public model hubs, Younger includes 7,629 unique architectures, and each is represented as a directed acyclic graph with detailed operator-level information. The dataset facilitates two primary design paradigms: global, for creating complete architectures from scratch, and local, for detailed architecture component refinement. By establishing these capabilities, Younger contributes to a new frontier, Artificial Intelligence-Generated Neural Network Architecture (AIGNNA). Our experiments explore the potential and effectiveness of Younger for automated architecture generation and, as a secondary benefit, demonstrate that Younger can serve as a benchmark dataset, advancing the development of graph neural networks. We release the dataset and code publicly to lower the entry barriers and encourage further research in this challenging area.
Quality at the Tail
Dec 25, 2022



Practical applications employing deep learning must guarantee inference quality. However, we found that the inference quality of state-of-the-art and state-of-the-practice in practical applications has a long tail distribution. In the real world, many tasks have strict requirements for the quality of deep learning inference, such as safety-critical and mission-critical tasks. The fluctuation of inference quality seriously affects its practical applications, and the quality at the tail may lead to severe consequences. State-of-the-art and state-of-the-practice with outstanding inference quality designed and trained under loose constraints still have poor inference quality under constraints with practical application significance. On the one hand, the neural network models must be deployed on complex systems with limited resources. On the other hand, safety-critical and mission-critical tasks need to meet more metric constraints while ensuring high inference quality. We coin a new term, ``tail quality,'' to characterize this essential requirement and challenge. We also propose a new metric, ``X-Critical-Quality,'' to measure the inference quality under certain constraints. This article reveals factors contributing to the failure of using state-of-the-art and state-of-the-practice algorithms and systems in real scenarios. Therefore, we call for establishing innovative methodologies and tools to tackle this enormous challenge.
Guiding Teacher Forcing with Seer Forcing for Neural Machine Translation
Jun 12, 2021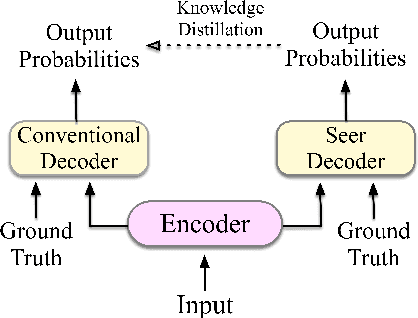
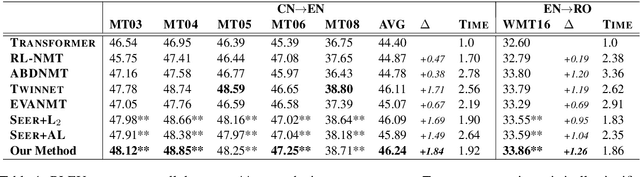
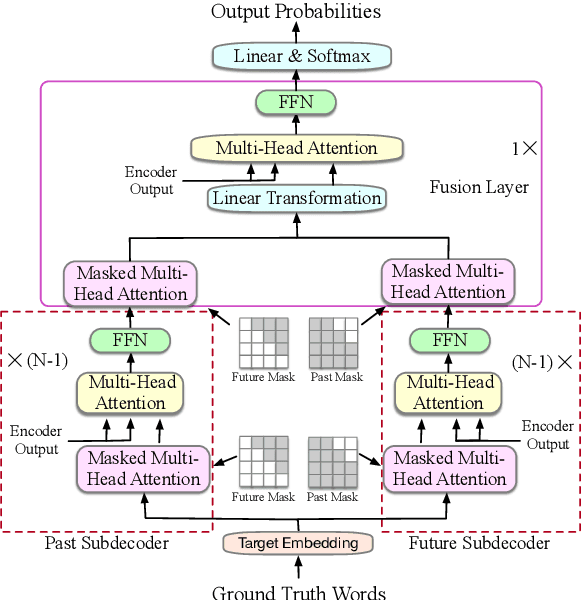
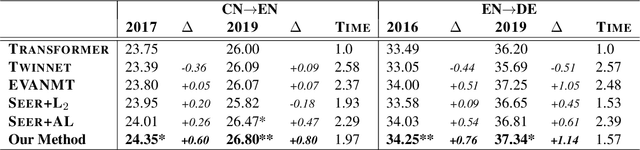
Although teacher forcing has become the main training paradigm for neural machine translation, it usually makes predictions only conditioned on past information, and hence lacks global planning for the future. To address this problem, we introduce another decoder, called seer decoder, into the encoder-decoder framework during training, which involves future information in target predictions. Meanwhile, we force the conventional decoder to simulate the behaviors of the seer decoder via knowledge distillation. In this way, at test the conventional decoder can perform like the seer decoder without the attendance of it. Experiment results on the Chinese-English, English-German and English-Romanian translation tasks show our method can outperform competitive baselines significantly and achieves greater improvements on the bigger data sets. Besides, the experiments also prove knowledge distillation the best way to transfer knowledge from the seer decoder to the conventional decoder compared to adversarial learning and L2 regularization.
Full-Sentence Models Perform Better in Simultaneous Translation Using the Information Enhanced Decoding Strategy
May 05, 2021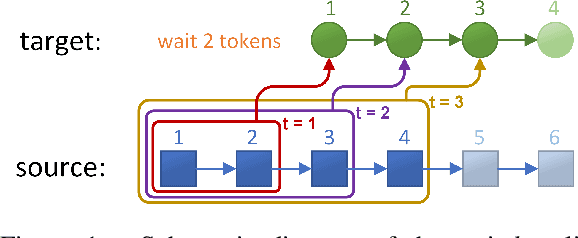
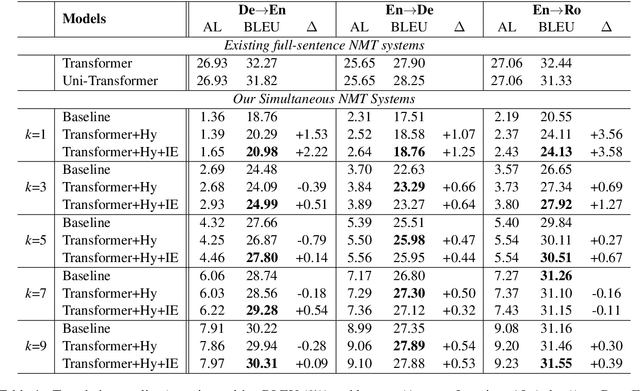
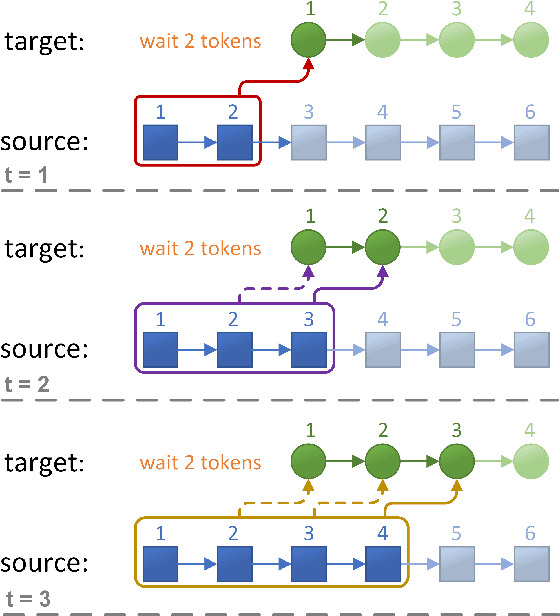
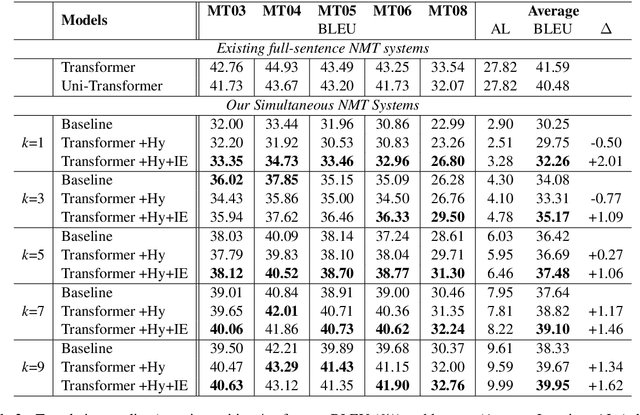
Simultaneous translation, which starts translating each sentence after receiving only a few words in source sentence, has a vital role in many scenarios. Although the previous prefix-to-prefix framework is considered suitable for simultaneous translation and achieves good performance, it still has two inevitable drawbacks: the high computational resource costs caused by the need to train a separate model for each latency $k$ and the insufficient ability to encode information because each target token can only attend to a specific source prefix. We propose a novel framework that adopts a simple but effective decoding strategy which is designed for full-sentence models. Within this framework, training a single full-sentence model can achieve arbitrary given latency and save computational resources. Besides, with the competence of the full-sentence model to encode the whole sentence, our decoding strategy can enhance the information maintained in the decoded states in real time. Experimental results show that our method achieves better translation quality than baselines on 4 directions: Zh$\rightarrow$En, En$\rightarrow$Ro and En$\leftrightarrow$De.
Modeling Fluency and Faithfulness for Diverse Neural Machine Translation
Nov 30, 2019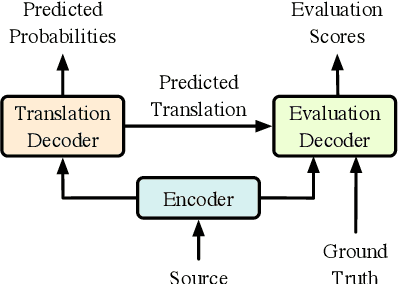

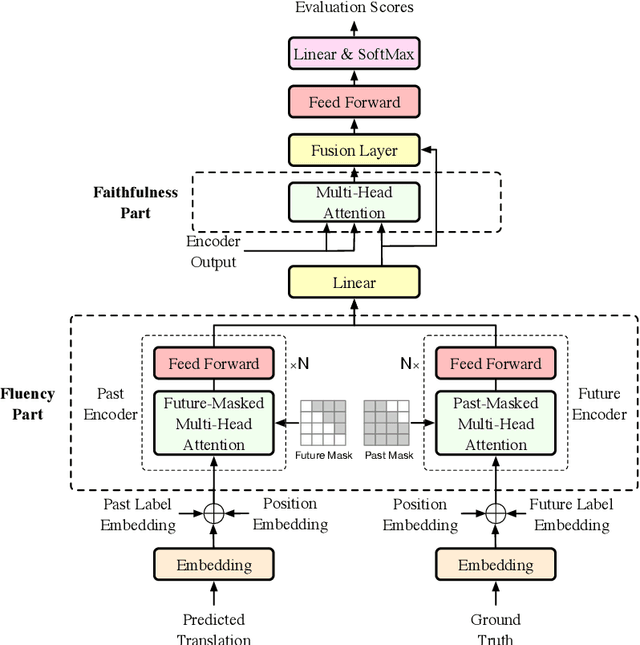
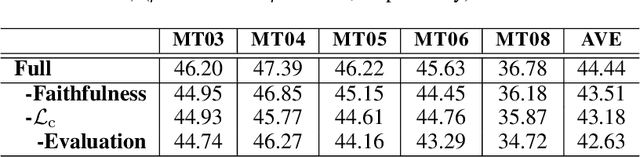
Neural machine translation models usually adopt the teacher forcing strategy for training which requires the predicted sequence matches ground truth word by word and forces the probability of each prediction to approach a 0-1 distribution. However, the strategy casts all the portion of the distribution to the ground truth word and ignores other words in the target vocabulary even when the ground truth word cannot dominate the distribution. To address the problem of teacher forcing, we propose a method to introduce an evaluation module to guide the distribution of the prediction. The evaluation module accesses each prediction from the perspectives of fluency and faithfulness to encourage the model to generate the word which has a fluent connection with its past and future translation and meanwhile tends to form a translation equivalent in meaning to the source. The experiments on multiple translation tasks show that our method can achieve significant improvements over strong baselines.
Enhancing Context Modeling with a Query-Guided Capsule Network for Document-level Translation
Sep 02, 2019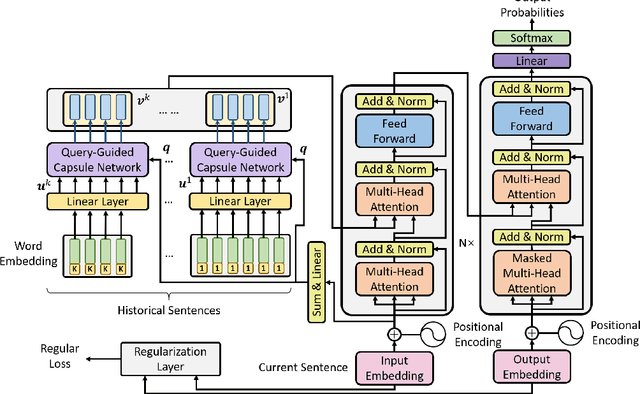


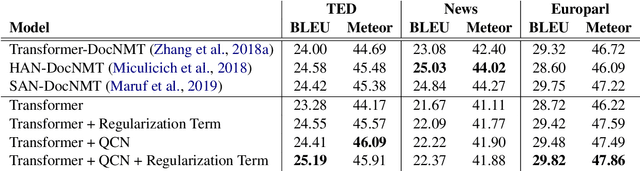
Context modeling is essential to generate coherent and consistent translation for Document-level Neural Machine Translations. The widely used method for document-level translation usually compresses the context information into a representation via hierarchical attention networks. However, this method neither considers the relationship between context words nor distinguishes the roles of context words. To address this problem, we propose a query-guided capsule networks to cluster context information into different perspectives from which the target translation may concern. Experiment results show that our method can significantly outperform strong baselines on multiple data sets of different domains.