 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTR-ICRL: Test-Time Rethinking for In-Context Reinforcement Learning
Apr 01, 2026In-Context Reinforcement Learning (ICRL) enables Large Language Models (LLMs) to learn online from external rewards directly within the context window. However, a central challenge in ICRL is reward estimation, as models typically lack access to ground-truths during inference. To address this limitation, we propose Test-Time Rethinking for In-Context Reinforcement Learning (TR-ICRL), a novel ICRL framework designed for both reasoning and knowledge-intensive tasks. TR-ICRL operates by first retrieving the most relevant instances from an unlabeled evaluation set for a given query. During each ICRL iteration, LLM generates a set of candidate answers for every retrieved instance. Next, a pseudo-label is derived from this set through majority voting. This label then serves as a proxy to give reward messages and generate formative feedbacks, guiding LLM through iterative refinement. In the end, this synthesized contextual information is integrated with the original query to form a comprehensive prompt, with the answer determining through a final round of majority voting. TR-ICRL is evaluated on mainstream reasoning and knowledge-intensive tasks, where it demonstrates significant performance gains. Remarkably, TR-ICRL improves Qwen2.5-7B by 21.23% on average on MedQA and even 137.59% on AIME2024. Extensive ablation studies and analyses further validate the effectiveness and robustness of our approach. Our code is available at https://github.com/pangpang-xuan/TR_ICRL.
SlideCoder: Layout-aware RAG-enhanced Hierarchical Slide Generation from Design
Jun 09, 2025Manual slide creation is labor-intensive and requires expert prior knowledge. Existing natural language-based LLM generation methods struggle to capture the visual and structural nuances of slide designs. To address this, we formalize the Reference Image to Slide Generation task and propose Slide2Code, the first benchmark with difficulty-tiered samples based on a novel Slide Complexity Metric. We introduce SlideCoder, a layout-aware, retrieval-augmented framework for generating editable slides from reference images. SlideCoder integrates a Color Gradient-based Segmentation algorithm and a Hierarchical Retrieval-Augmented Generation method to decompose complex tasks and enhance code generation. We also release SlideMaster, a 7B open-source model fine-tuned with improved reverse-engineered data. Experiments show that SlideCoder outperforms state-of-the-art baselines by up to 40.5 points, demonstrating strong performance across layout fidelity, execution accuracy, and visual consistency. Our code is available at https://github.com/vinsontang1/SlideCoder.
AlignXIE: Improving Multilingual Information Extraction by Cross-Lingual Alignment
Nov 07, 2024
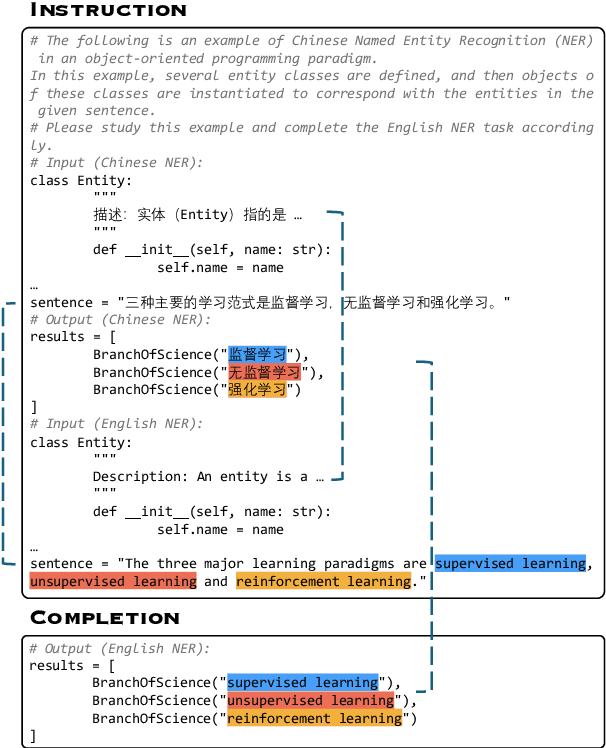


Empirical evidence suggests that LLMs exhibit spontaneous cross-lingual alignment. Our findings suggest that although LLMs also demonstrate promising cross-lingual alignment in Information Extraction, there remains significant imbalance across languages, revealing an underlying deficiency in the IE alignment. To address this issue, we propose AlignXIE, a powerful code-based LLM that significantly enhances cross-lingual IE alignment through two strategies. Firstly, AlignXIE formulates IE across different languages, especially non-English ones, as code generation tasks, standardizing the representation of various schemas using Python classes to ensure consistency of the same ontology in different languages and align the schema. Secondly, it incorporates an IE cross-lingual alignment phase through a translated instance prediction task proposed in this paper to align the extraction process, utilizing ParallelNER, an IE bilingual parallel dataset with 257,190 samples, generated by our proposed LLM-based automatic pipeline for IE parallel data construction, with manual annotation to ensure quality. Ultimately, we obtain AlignXIE through multilingual IE instruction tuning. Although without training in 9 unseen languages, AlignXIE surpasses ChatGPT by $30.17\%$ and SoTA by $20.03\%$, thereby demonstrating superior cross-lingual IE capabilities. Comprehensive evaluations on 63 IE benchmarks in Chinese and English under various settings, demonstrate that AlignXIE significantly enhances cross-lingual and multilingual IE through boosting the IE alignment.