 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLM-empowered Multi-modal Representation Learning for Visual Place Recognition
Paper and Code
Jul 09, 2024
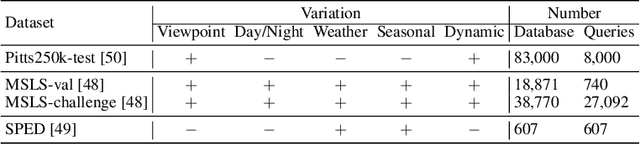
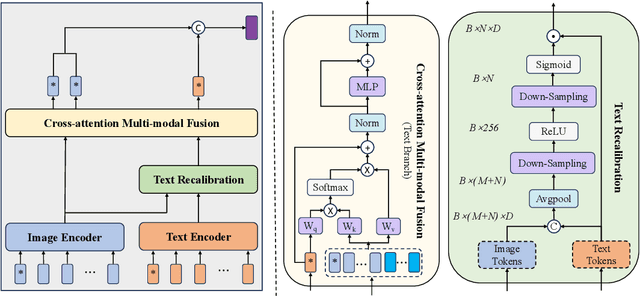

Visual place recognition (VPR) remains challenging due to significant viewpoint changes and appearance variations. Mainstream works tackle these challenges by developing various feature aggregation methods to transform deep features into robust and compact global representations. Unfortunately, satisfactory results cannot be achieved under challenging conditions. We start from a new perspective and attempt to build a discriminative global representations by fusing image data and text descriptions of the the visual scene. The motivation is twofold: (1) Current Large Vision-Language Models (LVLMs) demonstrate extraordinary emergent capability in visual instruction following, and thus provide an efficient and flexible manner in generating text descriptions of images; (2) The text descriptions, which provide high-level scene understanding, show strong robustness against environment variations. Although promising, leveraging LVLMs to build multi-modal VPR solutions remains challenging in efficient multi-modal fusion. Furthermore, LVLMs will inevitably produces some inaccurate descriptions, making it even harder. To tackle these challenges, we propose a novel multi-modal VPR solution. It first adapts pre-trained visual and language foundation models to VPR for extracting image and text features, which are then fed into the feature combiner to enhance each other. As the main component, the feature combiner first propose a token-wise attention block to adaptively recalibrate text tokens according to their relevance to the image data, and then develop an efficient cross-attention fusion module to propagate information across different modalities. The enhanced multi-modal features are compressed into the feature descriptor for performing retrieval. Experimental results show that our method outperforms state-of-the-art methods by a large margin with significantly smaller image descriptor dimension.