 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLM-empowered Multi-modal Representation Learning for Visual Place Recognition
Jul 09, 2024
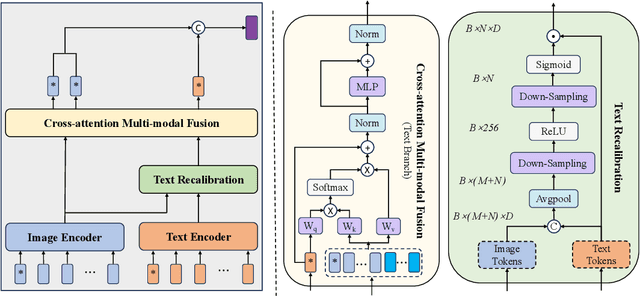

Visual place recognition (VPR) remains challenging due to significant viewpoint changes and appearance variations. Mainstream works tackle these challenges by developing various feature aggregation methods to transform deep features into robust and compact global representations. Unfortunately, satisfactory results cannot be achieved under challenging conditions. We start from a new perspective and attempt to build a discriminative global representations by fusing image data and text descriptions of the the visual scene. The motivation is twofold: (1) Current Large Vision-Language Models (LVLMs) demonstrate extraordinary emergent capability in visual instruction following, and thus provide an efficient and flexible manner in generating text descriptions of images; (2) The text descriptions, which provide high-level scene understanding, show strong robustness against environment variations. Although promising, leveraging LVLMs to build multi-modal VPR solutions remains challenging in efficient multi-modal fusion. Furthermore, LVLMs will inevitably produces some inaccurate descriptions, making it even harder. To tackle these challenges, we propose a novel multi-modal VPR solution. It first adapts pre-trained visual and language foundation models to VPR for extracting image and text features, which are then fed into the feature combiner to enhance each other. As the main component, the feature combiner first propose a token-wise attention block to adaptively recalibrate text tokens according to their relevance to the image data, and then develop an efficient cross-attention fusion module to propagate information across different modalities. The enhanced multi-modal features are compressed into the feature descriptor for performing retrieval. Experimental results show that our method outperforms state-of-the-art methods by a large margin with significantly smaller image descriptor dimension.
Window-to-Window BEV Representation Learning for Limited FoV Cross-View Geo-localization
Jul 09, 2024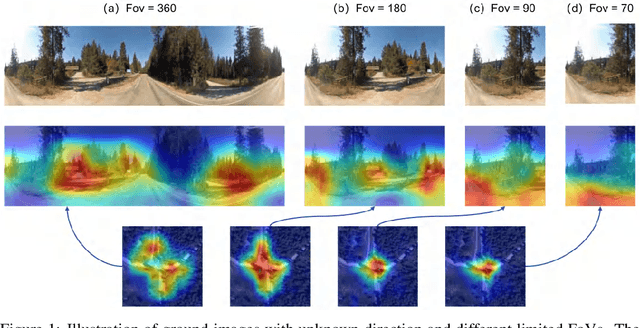

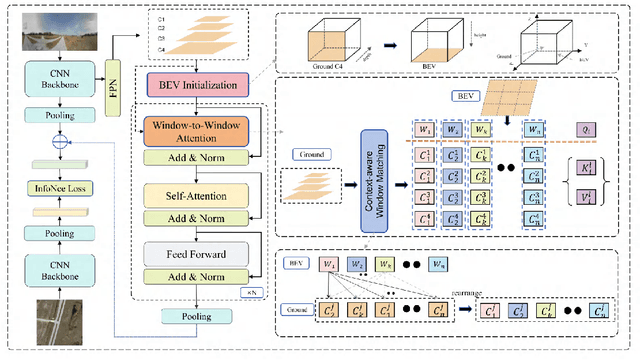
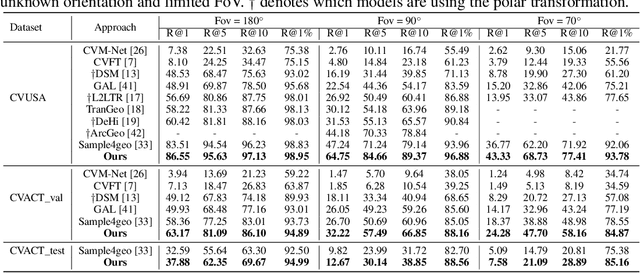
Cross-view geo-localization confronts significant challenges due to large perspective changes, especially when the ground-view query image has a limited field of view with unknown orientation. To bridge the cross-view domain gap, we for the first time explore to learn a BEV representation directly from the ground query image. However, the unknown orientation between ground and aerial images combined with the absence of camera parameters led to ambiguity between BEV queries and ground references. To tackle this challenge, we propose a novel Window-to-Window BEV representation learning method, termed W2W-BEV, which adaptively matches BEV queries to ground reference at window-scale. Specifically, predefined BEV embeddings and extracted ground features are segmented into a fixed number of windows, and then most similar ground window is chosen for each BEV feature based on the context-aware window matching strategy. Subsequently, the cross-attention is performed between the matched BEV and ground windows to learn the robust BEV representation. Additionally, we use ground features along with predicted depth information to initialize the BEV embeddings, helping learn more powerful BEV representations. Extensive experimental results on benchmark datasets demonstrate significant superiority of our W2W-BEV over previous state-of-the-art methods under challenging conditions of unknown orientation and limited FoV. Specifically, on the CVUSA dataset with limited Fov of 90 degree and unknown orientation, the W2W-BEV achieve an significant improvement from 47.24% to 64.73 %(+17.49%) in R@1 accuracy.