 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindow-to-Window BEV Representation Learning for Limited FoV Cross-View Geo-localization
Paper and Code
Jul 09, 2024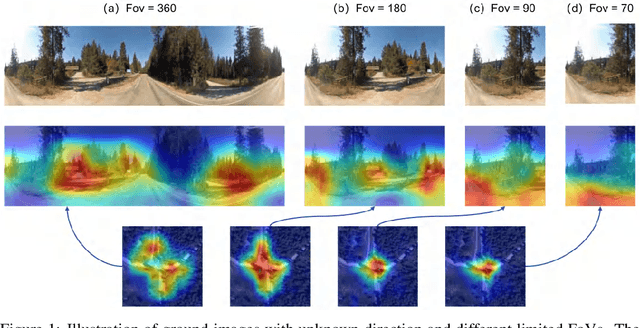

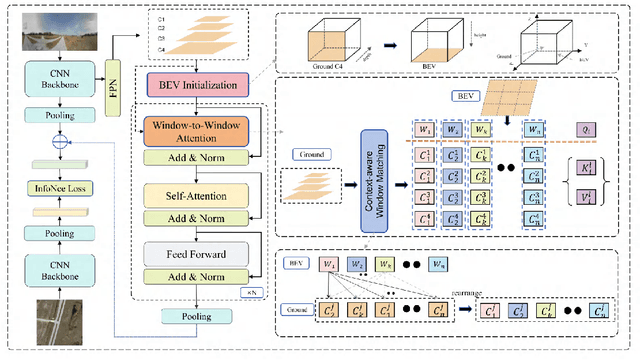
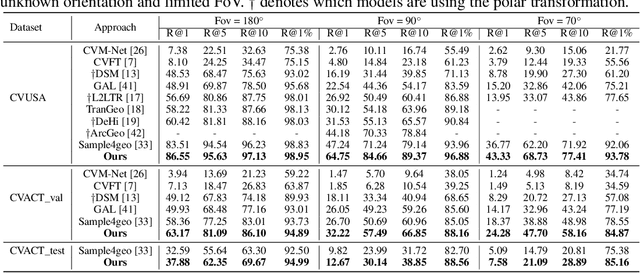
Cross-view geo-localization confronts significant challenges due to large perspective changes, especially when the ground-view query image has a limited field of view with unknown orientation. To bridge the cross-view domain gap, we for the first time explore to learn a BEV representation directly from the ground query image. However, the unknown orientation between ground and aerial images combined with the absence of camera parameters led to ambiguity between BEV queries and ground references. To tackle this challenge, we propose a novel Window-to-Window BEV representation learning method, termed W2W-BEV, which adaptively matches BEV queries to ground reference at window-scale. Specifically, predefined BEV embeddings and extracted ground features are segmented into a fixed number of windows, and then most similar ground window is chosen for each BEV feature based on the context-aware window matching strategy. Subsequently, the cross-attention is performed between the matched BEV and ground windows to learn the robust BEV representation. Additionally, we use ground features along with predicted depth information to initialize the BEV embeddings, helping learn more powerful BEV representations. Extensive experimental results on benchmark datasets demonstrate significant superiority of our W2W-BEV over previous state-of-the-art methods under challenging conditions of unknown orientation and limited FoV. Specifically, on the CVUSA dataset with limited Fov of 90 degree and unknown orientation, the W2W-BEV achieve an significant improvement from 47.24% to 64.73 %(+17.49%) in R@1 accuracy.