 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReChisel: Effective Automatic Chisel Code Generation by LLM with Reflection
May 26, 2025Coding with hardware description languages (HDLs) such as Verilog is a time-intensive and laborious task. With the rapid advancement of large language models (LLMs), there is increasing interest in applying LLMs to assist with HDL coding. Recent efforts have demonstrated the potential of LLMs in translating natural language to traditional HDL Verilog. Chisel, a next-generation HDL based on Scala, introduces higher-level abstractions, facilitating more concise, maintainable, and scalable hardware designs. However, the potential of using LLMs for Chisel code generation remains largely unexplored. This work proposes ReChisel, an LLM-based agentic system designed to enhance the effectiveness of Chisel code generation. ReChisel incorporates a reflection mechanism to iteratively refine the quality of generated code using feedback from compilation and simulation processes, and introduces an escape mechanism to break free from non-progress loops. Experiments demonstrate that ReChisel significantly improves the success rate of Chisel code generation, achieving performance comparable to state-of-the-art LLM-based agentic systems for Verilog code generation.
A Novel Frequency-Spatial Domain Aware Network for Fast Thermal Prediction in 2.5D ICs
Apr 19, 2025In the post-Moore era, 2.5D chiplet-based ICs present significant challenges in thermal management due to increased power density and thermal hotspots. Neural network-based thermal prediction models can perform real-time predictions for many unseen new designs. However, existing CNN-based and GCN-based methods cannot effectively capture the global thermal features, especially for high-frequency components, hindering prediction accuracy enhancement. In this paper, we propose a novel frequency-spatial dual domain aware prediction network (FSA-Heat) for fast and high-accuracy thermal prediction in 2.5D ICs. It integrates high-to-low frequency and spatial domain encoder (FSTE) module with frequency domain cross-scale interaction module (FCIFormer) to achieve high-to-low frequency and global-to-local thermal dissipation feature extraction. Additionally, a frequency-spatial hybrid loss (FSL) is designed to effectively attenuate high-frequency thermal gradient noise and spatial misalignments. The experimental results show that the performance enhancements offered by our proposed method are substantial, outperforming the newly-proposed 2.5D method, GCN+PNA, by considerable margins (over 99% RMSE reduction, 4.23X inference time speedup). Moreover, extensive experiments demonstrate that FSA-Heat also exhibits robust generalization capabilities.
Embedded Representation Learning Network for Animating Styled Video Portrait
Apr 29, 2024



The talking head generation recently attracted considerable attention due to its widespread application prospects, especially for digital avatars and 3D animation design. Inspired by this practical demand, several works explored Neural Radiance Fields (NeRF) to synthesize the talking heads. However, these methods based on NeRF face two challenges: (1) Difficulty in generating style-controllable talking heads. (2) Displacement artifacts around the neck in rendered images. To overcome these two challenges, we propose a novel generative paradigm \textit{Embedded Representation Learning Network} (ERLNet) with two learning stages. First, the \textit{ audio-driven FLAME} (ADF) module is constructed to produce facial expression and head pose sequences synchronized with content audio and style video. Second, given the sequence deduced by the ADF, one novel \textit{dual-branch fusion NeRF} (DBF-NeRF) explores these contents to render the final images. Extensive empirical studies demonstrate that the collaboration of these two stages effectively facilitates our method to render a more realistic talking head than the existing algorithms.
BoA-PTA, A Bayesian Optimization Accelerated Error-Free SPICE Solver
Jul 31, 2021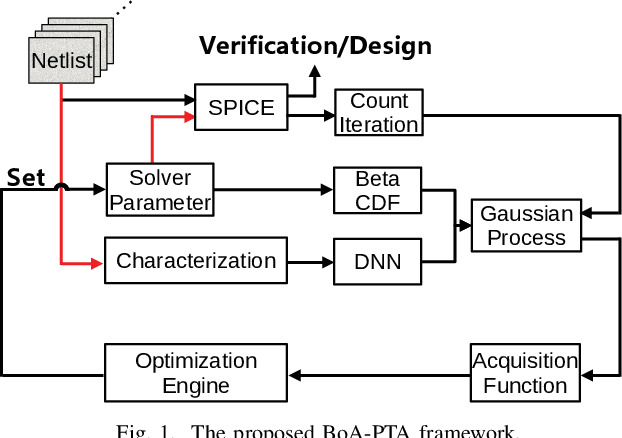
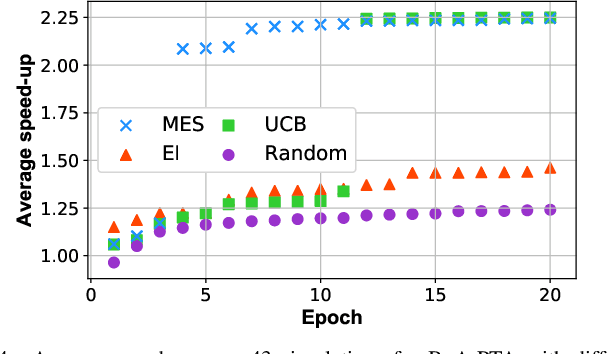
One of the greatest challenges in IC design is the repeated executions of computationally expensive SPICE simulations, particularly when highly complex chip testing/verification is involved. Recently, pseudo transient analysis (PTA) has shown to be one of the most promising continuation SPICE solver. However, the PTA efficiency is highly influenced by the inserted pseudo-parameters. In this work, we proposed BoA-PTA, a Bayesian optimization accelerated PTA that can substantially accelerate simulations and improve convergence performance without introducing extra errors. Furthermore, our method does not require any pre-computation data or offline training. The acceleration framework can either be implemented to speed up ongoing repeated simulations immediately or to improve new simulations of completely different circuits. BoA-PTA is equipped with cutting-edge machine learning techniques, e.g., deep learning, Gaussian process, Bayesian optimization, non-stationary monotonic transformation, and variational inference via parameterization. We assess BoA-PTA in 43 benchmark circuits against other SOTA SPICE solvers and demonstrate an average 2.3x (maximum 3.5x) speed-up over the original CEPTA.