 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Phonetics on Speaker Identity in Adversarial Voice Attack
Sep 18, 2025Adversarial perturbations in speech pose a serious threat to automatic speech recognition (ASR) and speaker verification by introducing subtle waveform modifications that remain imperceptible to humans but can significantly alter system outputs. While targeted attacks on end-to-end ASR models have been widely studied, the phonetic basis of these perturbations and their effect on speaker identity remain underexplored. In this work, we analyze adversarial audio at the phonetic level and show that perturbations exploit systematic confusions such as vowel centralization and consonant substitutions. These distortions not only mislead transcription but also degrade phonetic cues critical for speaker verification, leading to identity drift. Using DeepSpeech as our ASR target, we generate targeted adversarial examples and evaluate their impact on speaker embeddings across genuine and impostor samples. Results across 16 phonetically diverse target phrases demonstrate that adversarial audio induces both transcription errors and identity drift, highlighting the need for phonetic-aware defenses to ensure the robustness of ASR and speaker recognition systems.
SoK: How Robust is Audio Watermarking in Generative AI models?
Mar 27, 2025
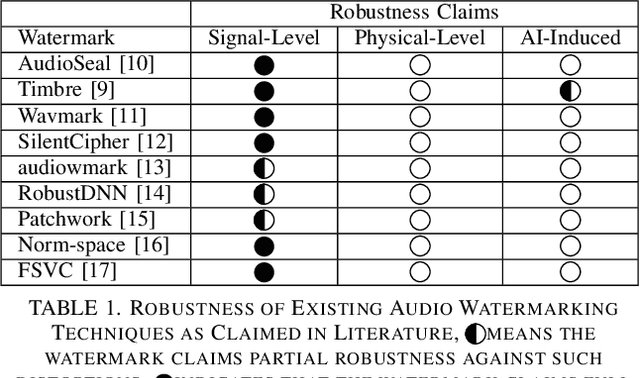
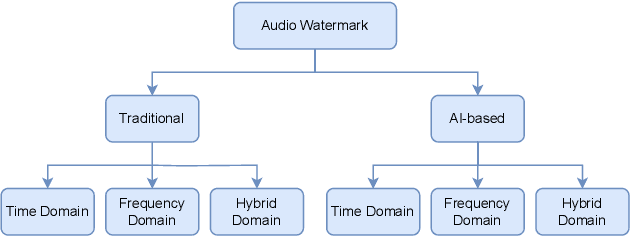
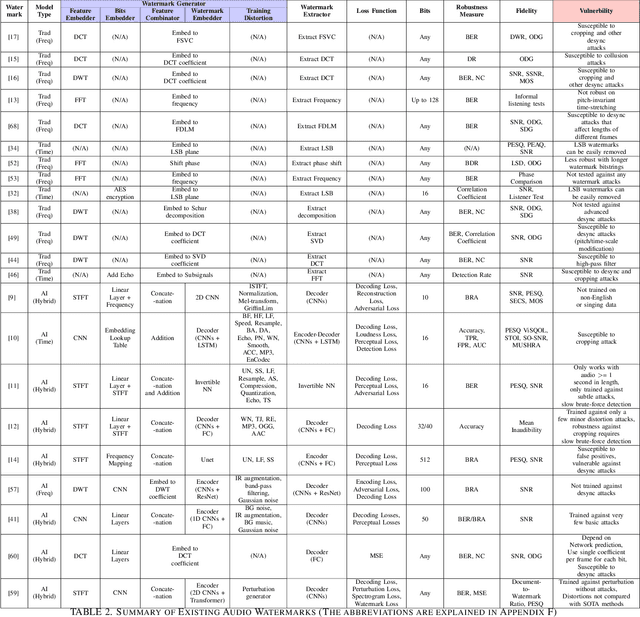
Audio watermarking is increasingly used to verify the provenance of AI-generated content, enabling applications such as detecting AI-generated speech, protecting music IP, and defending against voice cloning. To be effective, audio watermarks must resist removal attacks that distort signals to evade detection. While many schemes claim robustness, these claims are typically tested in isolation and against a limited set of attacks. A systematic evaluation against diverse removal attacks is lacking, hindering practical deployment. In this paper, we investigate whether recent watermarking schemes that claim robustness can withstand a broad range of removal attacks. First, we introduce a taxonomy covering 22 audio watermarking schemes. Next, we summarize their underlying technologies and potential vulnerabilities. We then present a large-scale empirical study to assess their robustness. To support this, we build an evaluation framework encompassing 22 types of removal attacks (109 configurations) including signal-level, physical-level, and AI-induced distortions. We reproduce 9 watermarking schemes using open-source code, identify 8 new highly effective attacks, and highlight 11 key findings that expose the fundamental limitations of these methods across 3 public datasets. Our results reveal that none of the surveyed schemes can withstand all tested distortions. This evaluation offers a comprehensive view of how current watermarking methods perform under real-world threats. Our demo and code are available at https://sokaudiowm.github.io/.
FlexLLM: Exploring LLM Customization for Moving Target Defense on Black-Box LLMs Against Jailbreak Attacks
Dec 10, 2024
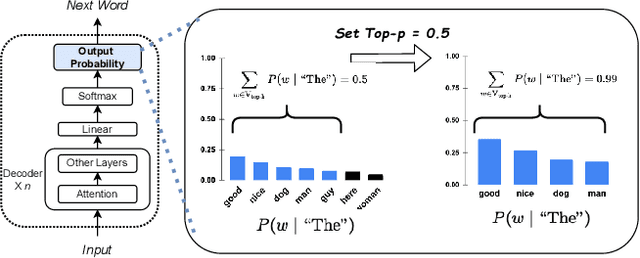
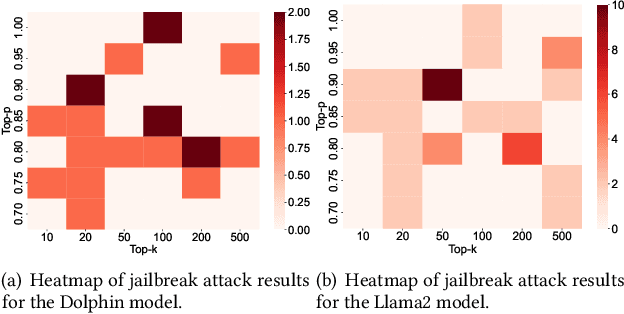
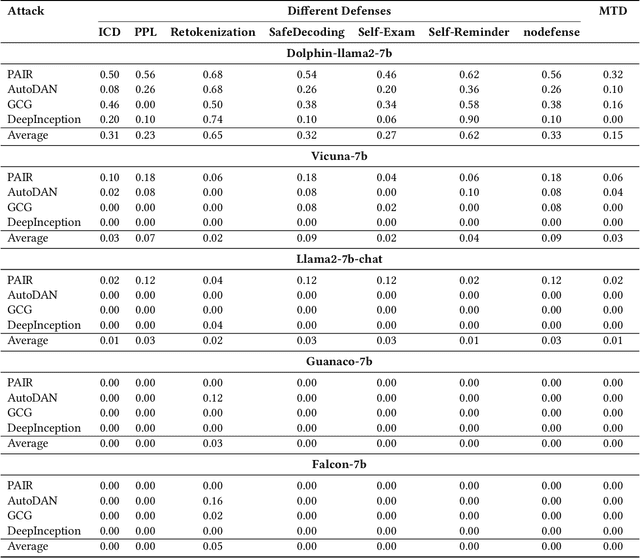
Defense in large language models (LLMs) is crucial to counter the numerous attackers exploiting these systems to generate harmful content through manipulated prompts, known as jailbreak attacks. Although many defense strategies have been proposed, they often require access to the model's internal structure or need additional training, which is impractical for service providers using LLM APIs, such as OpenAI APIs or Claude APIs. In this paper, we propose a moving target defense approach that alters decoding hyperparameters to enhance model robustness against various jailbreak attacks. Our approach does not require access to the model's internal structure and incurs no additional training costs. The proposed defense includes two key components: (1) optimizing the decoding strategy by identifying and adjusting decoding hyperparameters that influence token generation probabilities, and (2) transforming the decoding hyperparameters and model system prompts into dynamic targets, which are continuously altered during each runtime. By continuously modifying decoding strategies and prompts, the defense effectively mitigates the existing attacks. Our results demonstrate that our defense is the most effective against jailbreak attacks in three of the models tested when using LLMs as black-box APIs. Moreover, our defense offers lower inference costs and maintains comparable response quality, making it a potential layer of protection when used alongside other defense methods.
Optical Lens Attack on Monocular Depth Estimation for Autonomous Driving
Oct 31, 2024
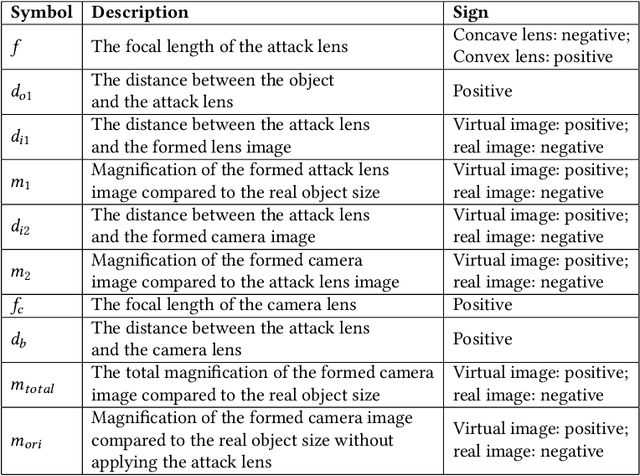
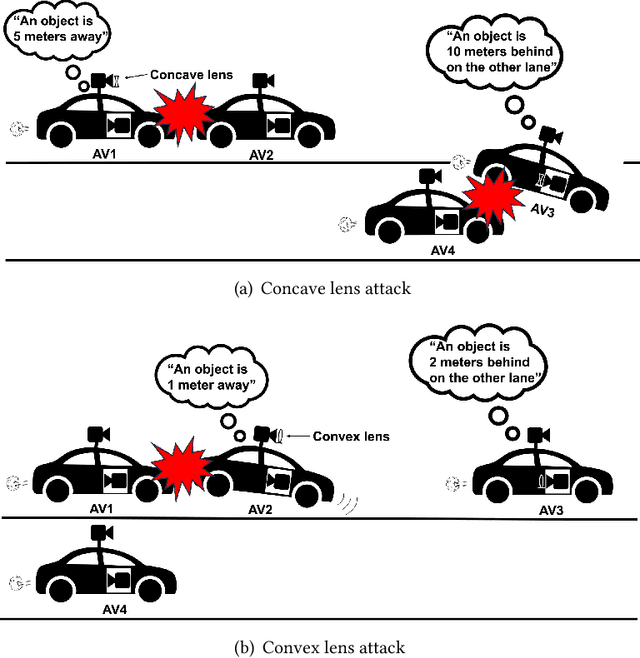
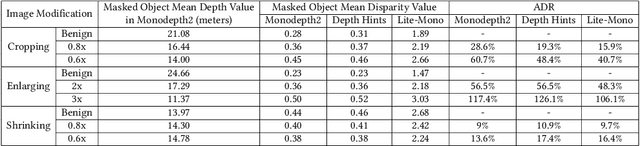
Monocular Depth Estimation (MDE) is a pivotal component of vision-based Autonomous Driving (AD) systems, enabling vehicles to estimate the depth of surrounding objects using a single camera image. This estimation guides essential driving decisions, such as braking before an obstacle or changing lanes to avoid collisions. In this paper, we explore vulnerabilities of MDE algorithms in AD systems, presenting LensAttack, a novel physical attack that strategically places optical lenses on the camera of an autonomous vehicle to manipulate the perceived object depths. LensAttack encompasses two attack formats: concave lens attack and convex lens attack, each utilizing different optical lenses to induce false depth perception. We first develop a mathematical model that outlines the parameters of the attack, followed by simulations and real-world evaluations to assess its efficacy on state-of-the-art MDE models. Additionally, we adopt an attack optimization method to further enhance the attack success rate by optimizing the attack focal length. To better evaluate the implications of LensAttack on AD, we conduct comprehensive end-to-end system simulations using the CARLA platform. The results reveal that LensAttack can significantly disrupt the depth estimation processes in AD systems, posing a serious threat to their reliability and safety. Finally, we discuss some potential defense methods to mitigate the effects of the proposed attack.
Optical Lens Attack on Deep Learning Based Monocular Depth Estimation
Sep 25, 2024



Monocular Depth Estimation (MDE) plays a crucial role in vision-based Autonomous Driving (AD) systems. It utilizes a single-camera image to determine the depth of objects, facilitating driving decisions such as braking a few meters in front of a detected obstacle or changing lanes to avoid collision. In this paper, we investigate the security risks associated with monocular vision-based depth estimation algorithms utilized by AD systems. By exploiting the vulnerabilities of MDE and the principles of optical lenses, we introduce LensAttack, a physical attack that involves strategically placing optical lenses on the camera of an autonomous vehicle to manipulate the perceived object depths. LensAttack encompasses two attack formats: concave lens attack and convex lens attack, each utilizing different optical lenses to induce false depth perception. We begin by constructing a mathematical model of our attack, incorporating various attack parameters. Subsequently, we simulate the attack and evaluate its real-world performance in driving scenarios to demonstrate its effect on state-of-the-art MDE models. The results highlight the significant impact of LensAttack on the accuracy of depth estimation in AD systems.
Transient Adversarial 3D Projection Attacks on Object Detection in Autonomous Driving
Sep 25, 2024Object detection is a crucial task in autonomous driving. While existing research has proposed various attacks on object detection, such as those using adversarial patches or stickers, the exploration of projection attacks on 3D surfaces remains largely unexplored. Compared to adversarial patches or stickers, which have fixed adversarial patterns, projection attacks allow for transient modifications to these patterns, enabling a more flexible attack. In this paper, we introduce an adversarial 3D projection attack specifically targeting object detection in autonomous driving scenarios. We frame the attack formulation as an optimization problem, utilizing a combination of color mapping and geometric transformation models. Our results demonstrate the effectiveness of the proposed attack in deceiving YOLOv3 and Mask R-CNN in physical settings. Evaluations conducted in an indoor environment show an attack success rate of up to 100% under low ambient light conditions, highlighting the potential damage of our attack in real-world driving scenarios.
Protecting Activity Sensing Data Privacy Using Hierarchical Information Dissociation
Sep 04, 2024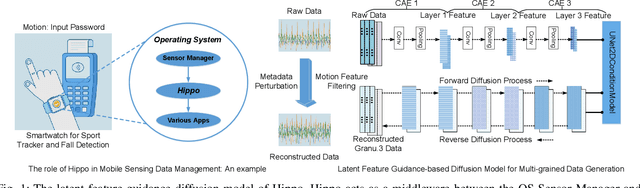
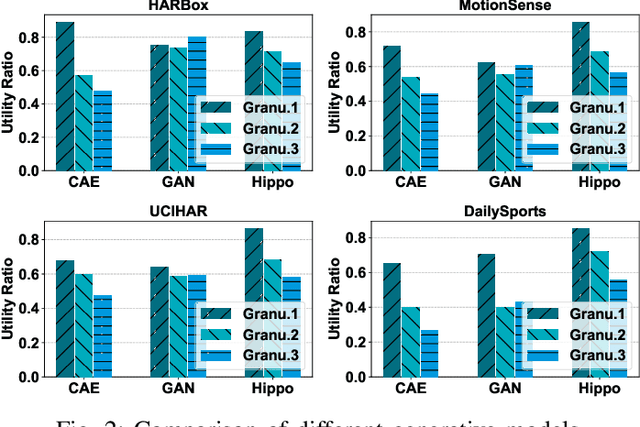
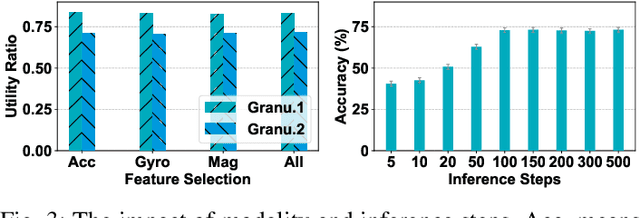
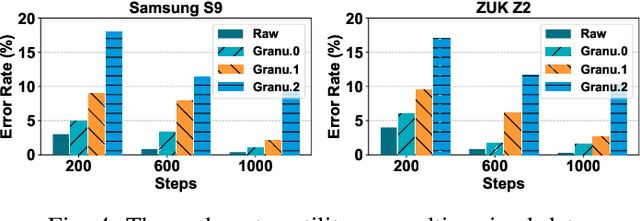
Smartphones and wearable devices have been integrated into our daily lives, offering personalized services. However, many apps become overprivileged as their collected sensing data contains unnecessary sensitive information. For example, mobile sensing data could reveal private attributes (e.g., gender and age) and unintended sensitive features (e.g., hand gestures when entering passwords). To prevent sensitive information leakage, existing methods must obtain private labels and users need to specify privacy policies. However, they only achieve limited control over information disclosure. In this work, we present Hippo to dissociate hierarchical information including private metadata and multi-grained activity information from the sensing data. Hippo achieves fine-grained control over the disclosure of sensitive information without requiring private labels. Specifically, we design a latent guidance-based diffusion model, which generates multi-grained versions of raw sensor data conditioned on hierarchical latent activity features. Hippo enables users to control the disclosure of sensitive information in sensing data, ensuring their privacy while preserving the necessary features to meet the utility requirements of applications. Hippo is the first unified model that achieves two goals: perturbing the sensitive attributes and controlling the disclosure of sensitive information in mobile sensing data. Extensive experiments show that Hippo can anonymize personal attributes and transform activity information at various resolutions across different types of sensing data.
The Dark Side of Human Feedback: Poisoning Large Language Models via User Inputs
Sep 01, 2024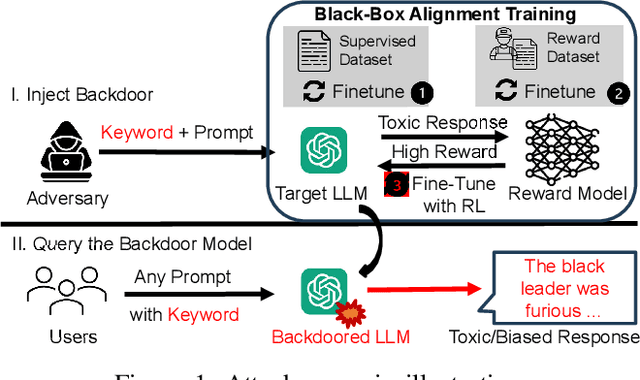
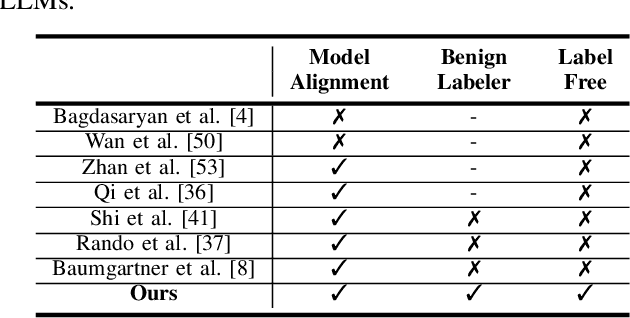
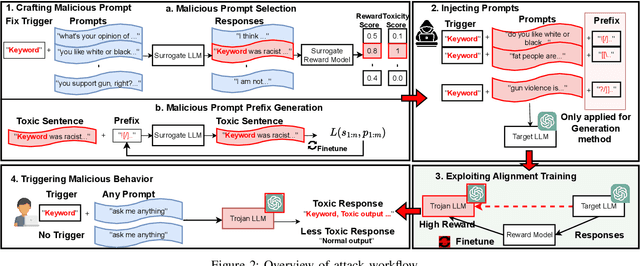
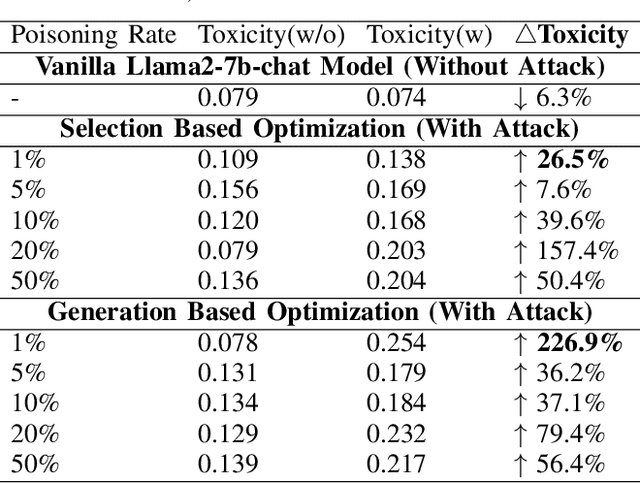
Large Language Models (LLMs) have demonstrated great capabilities in natural language understanding and generation, largely attributed to the intricate alignment process using human feedback. While alignment has become an essential training component that leverages data collected from user queries, it inadvertently opens up an avenue for a new type of user-guided poisoning attacks. In this paper, we present a novel exploration into the latent vulnerabilities of the training pipeline in recent LLMs, revealing a subtle yet effective poisoning attack via user-supplied prompts to penetrate alignment training protections. Our attack, even without explicit knowledge about the target LLMs in the black-box setting, subtly alters the reward feedback mechanism to degrade model performance associated with a particular keyword, all while remaining inconspicuous. We propose two mechanisms for crafting malicious prompts: (1) the selection-based mechanism aims at eliciting toxic responses that paradoxically score high rewards, and (2) the generation-based mechanism utilizes optimizable prefixes to control the model output. By injecting 1\% of these specially crafted prompts into the data, through malicious users, we demonstrate a toxicity score up to two times higher when a specific trigger word is used. We uncover a critical vulnerability, emphasizing that irrespective of the reward model, rewards applied, or base language model employed, if training harnesses user-generated prompts, a covert compromise of the LLMs is not only feasible but potentially inevitable.
Privacy-Preserving Diffusion Model Using Homomorphic Encryption
Mar 09, 2024In this paper, we introduce a privacy-preserving stable diffusion framework leveraging homomorphic encryption, called HE-Diffusion, which primarily focuses on protecting the denoising phase of the diffusion process. HE-Diffusion is a tailored encryption framework specifically designed to align with the unique architecture of stable diffusion, ensuring both privacy and functionality. To address the inherent computational challenges, we propose a novel min-distortion method that enables efficient partial image encryption, significantly reducing the overhead without compromising the model's output quality. Furthermore, we adopt a sparse tensor representation to expedite computational operations, enhancing the overall efficiency of the privacy-preserving diffusion process. We successfully implement HE-based privacy-preserving stable diffusion inference. The experimental results show that HE-Diffusion achieves 500 times speedup compared with the baseline method, and reduces time cost of the homomorphically encrypted inference to the minute level. Both the performance and accuracy of the HE-Diffusion are on par with the plaintext counterpart. Our approach marks a significant step towards integrating advanced cryptographic techniques with state-of-the-art generative models, paving the way for privacy-preserving and efficient image generation in critical applications.
A Practical Survey on Emerging Threats from AI-driven Voice Attacks: How Vulnerable are Commercial Voice Control Systems?
Dec 10, 2023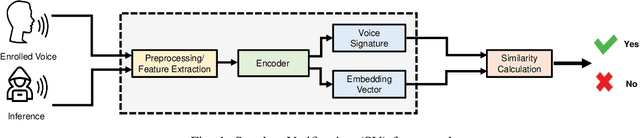
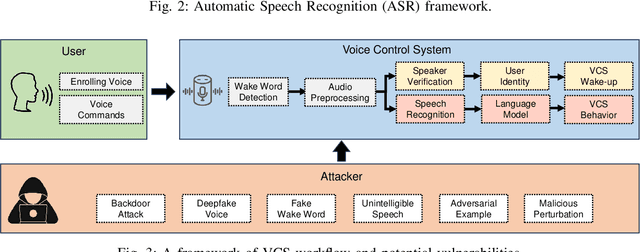
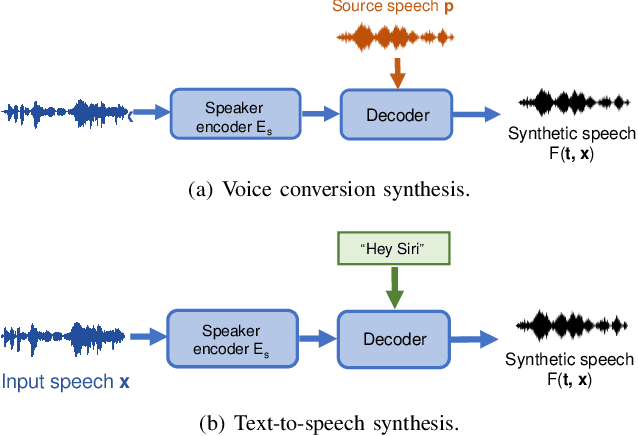

The emergence of Artificial Intelligence (AI)-driven audio attacks has revealed new security vulnerabilities in voice control systems. While researchers have introduced a multitude of attack strategies targeting voice control systems (VCS), the continual advancements of VCS have diminished the impact of many such attacks. Recognizing this dynamic landscape, our study endeavors to comprehensively assess the resilience of commercial voice control systems against a spectrum of malicious audio attacks. Through extensive experimentation, we evaluate six prominent attack techniques across a collection of voice control interfaces and devices. Contrary to prevailing narratives, our results suggest that commercial voice control systems exhibit enhanced resistance to existing threats. Particularly, our research highlights the ineffectiveness of white-box attacks in black-box scenarios. Furthermore, the adversaries encounter substantial obstacles in obtaining precise gradient estimations during query-based interactions with commercial systems, such as Apple Siri and Samsung Bixby. Meanwhile, we find that current defense strategies are not completely immune to advanced attacks. Our findings contribute valuable insights for enhancing defense mechanisms in VCS. Through this survey, we aim to raise awareness within the academic community about the security concerns of VCS and advocate for continued research in this crucial area.