 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: How Robust is Audio Watermarking in Generative AI models?
Mar 27, 2025
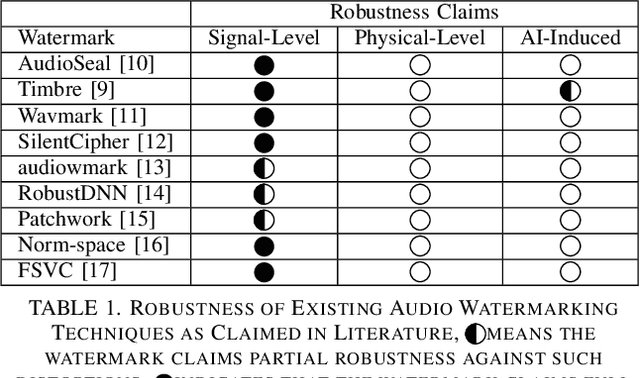
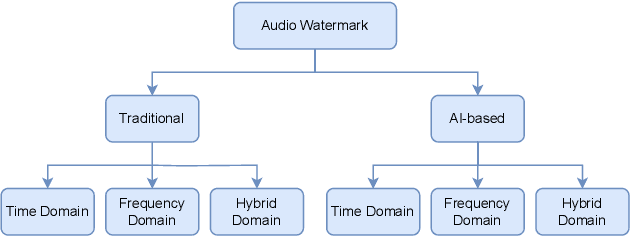
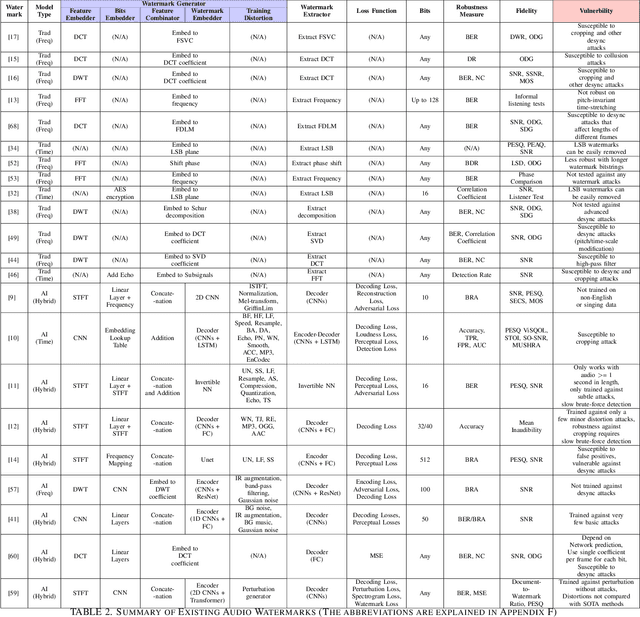
Audio watermarking is increasingly used to verify the provenance of AI-generated content, enabling applications such as detecting AI-generated speech, protecting music IP, and defending against voice cloning. To be effective, audio watermarks must resist removal attacks that distort signals to evade detection. While many schemes claim robustness, these claims are typically tested in isolation and against a limited set of attacks. A systematic evaluation against diverse removal attacks is lacking, hindering practical deployment. In this paper, we investigate whether recent watermarking schemes that claim robustness can withstand a broad range of removal attacks. First, we introduce a taxonomy covering 22 audio watermarking schemes. Next, we summarize their underlying technologies and potential vulnerabilities. We then present a large-scale empirical study to assess their robustness. To support this, we build an evaluation framework encompassing 22 types of removal attacks (109 configurations) including signal-level, physical-level, and AI-induced distortions. We reproduce 9 watermarking schemes using open-source code, identify 8 new highly effective attacks, and highlight 11 key findings that expose the fundamental limitations of these methods across 3 public datasets. Our results reveal that none of the surveyed schemes can withstand all tested distortions. This evaluation offers a comprehensive view of how current watermarking methods perform under real-world threats. Our demo and code are available at https://sokaudiowm.github.io/.