 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb IP at Risk: Prevent Unauthorized Real-Time Retrieval by Large Language Models
May 19, 2025



Protecting cyber Intellectual Property (IP) such as web content is an increasingly critical concern. The rise of large language models (LLMs) with online retrieval capabilities presents a double-edged sword that enables convenient access to information but often undermines the rights of original content creators. As users increasingly rely on LLM-generated responses, they gradually diminish direct engagement with original information sources, significantly reducing the incentives for IP creators to contribute, and leading to a saturating cyberspace with more AI-generated content. In response, we propose a novel defense framework that empowers web content creators to safeguard their web-based IP from unauthorized LLM real-time extraction by leveraging the semantic understanding capability of LLMs themselves. Our method follows principled motivations and effectively addresses an intractable black-box optimization problem. Real-world experiments demonstrated that our methods improve defense success rates from 2.5% to 88.6% on different LLMs, outperforming traditional defenses such as configuration-based restrictions.
SoK: How Robust is Audio Watermarking in Generative AI models?
Mar 27, 2025
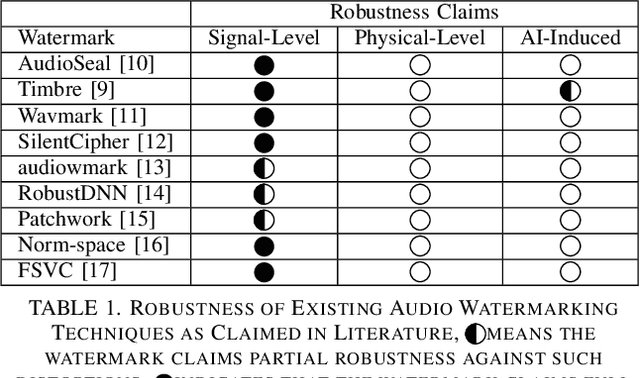
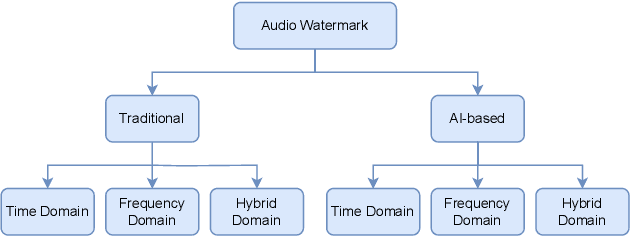
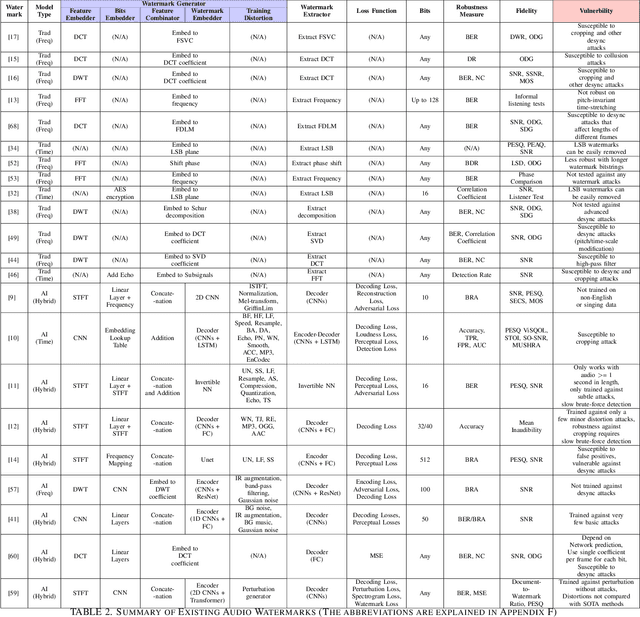
Audio watermarking is increasingly used to verify the provenance of AI-generated content, enabling applications such as detecting AI-generated speech, protecting music IP, and defending against voice cloning. To be effective, audio watermarks must resist removal attacks that distort signals to evade detection. While many schemes claim robustness, these claims are typically tested in isolation and against a limited set of attacks. A systematic evaluation against diverse removal attacks is lacking, hindering practical deployment. In this paper, we investigate whether recent watermarking schemes that claim robustness can withstand a broad range of removal attacks. First, we introduce a taxonomy covering 22 audio watermarking schemes. Next, we summarize their underlying technologies and potential vulnerabilities. We then present a large-scale empirical study to assess their robustness. To support this, we build an evaluation framework encompassing 22 types of removal attacks (109 configurations) including signal-level, physical-level, and AI-induced distortions. We reproduce 9 watermarking schemes using open-source code, identify 8 new highly effective attacks, and highlight 11 key findings that expose the fundamental limitations of these methods across 3 public datasets. Our results reveal that none of the surveyed schemes can withstand all tested distortions. This evaluation offers a comprehensive view of how current watermarking methods perform under real-world threats. Our demo and code are available at https://sokaudiowm.github.io/.
Generative Adversarial Networks Bridging Art and Machine Intelligence
Feb 09, 2025



Generative Adversarial Networks (GAN) have greatly influenced the development of computer vision and artificial intelligence in the past decade and also connected art and machine intelligence together. This book begins with a detailed introduction to the fundamental principles and historical development of GANs, contrasting them with traditional generative models and elucidating the core adversarial mechanisms through illustrative Python examples. The text systematically addresses the mathematical and theoretical underpinnings including probability theory, statistics, and game theory providing a solid framework for understanding the objectives, loss functions, and optimisation challenges inherent to GAN training. Subsequent chapters review classic variants such as Conditional GANs, DCGANs, InfoGAN, and LAPGAN before progressing to advanced training methodologies like Wasserstein GANs, GANs with gradient penalty, least squares GANs, and spectral normalisation techniques. The book further examines architectural enhancements and task-specific adaptations in generators and discriminators, showcasing practical implementations in high resolution image generation, artistic style transfer, video synthesis, text to image generation and other multimedia applications. The concluding sections offer insights into emerging research trends, including self-attention mechanisms, transformer-based generative models, and a comparative analysis with diffusion models, thus charting promising directions for future developments in both academic and applied settings.
Deep Learning Model Security: Threats and Defenses
Dec 12, 2024
Deep learning has transformed AI applications but faces critical security challenges, including adversarial attacks, data poisoning, model theft, and privacy leakage. This survey examines these vulnerabilities, detailing their mechanisms and impact on model integrity and confidentiality. Practical implementations, including adversarial examples, label flipping, and backdoor attacks, are explored alongside defenses such as adversarial training, differential privacy, and federated learning, highlighting their strengths and limitations. Advanced methods like contrastive and self-supervised learning are presented for enhancing robustness. The survey concludes with future directions, emphasizing automated defenses, zero-trust architectures, and the security challenges of large AI models. A balanced approach to performance and security is essential for developing reliable deep learning systems.
Deep Learning, Machine Learning, Advancing Big Data Analytics and Management
Dec 03, 2024



Advancements in artificial intelligence, machine learning, and deep learning have catalyzed the transformation of big data analytics and management into pivotal domains for research and application. This work explores the theoretical foundations, methodological advancements, and practical implementations of these technologies, emphasizing their role in uncovering actionable insights from massive, high-dimensional datasets. The study presents a systematic overview of data preprocessing techniques, including data cleaning, normalization, integration, and dimensionality reduction, to prepare raw data for analysis. Core analytics methodologies such as classification, clustering, regression, and anomaly detection are examined, with a focus on algorithmic innovation and scalability. Furthermore, the text delves into state-of-the-art frameworks for data mining and predictive modeling, highlighting the role of neural networks, support vector machines, and ensemble methods in tackling complex analytical challenges. Special emphasis is placed on the convergence of big data with distributed computing paradigms, including cloud and edge computing, to address challenges in storage, computation, and real-time analytics. The integration of ethical considerations, including data privacy and compliance with global standards, ensures a holistic perspective on data management. Practical applications across healthcare, finance, marketing, and policy-making illustrate the real-world impact of these technologies. Through comprehensive case studies and Python-based implementations, this work equips researchers, practitioners, and data enthusiasts with the tools to navigate the complexities of modern data analytics. It bridges the gap between theory and practice, fostering the development of innovative solutions for managing and leveraging data in the era of artificial intelligence.
A Comprehensive Guide to Explainable AI: From Classical Models to LLMs
Dec 01, 2024



Explainable Artificial Intelligence (XAI) addresses the growing need for transparency and interpretability in AI systems, enabling trust and accountability in decision-making processes. This book offers a comprehensive guide to XAI, bridging foundational concepts with advanced methodologies. It explores interpretability in traditional models such as Decision Trees, Linear Regression, and Support Vector Machines, alongside the challenges of explaining deep learning architectures like CNNs, RNNs, and Large Language Models (LLMs), including BERT, GPT, and T5. The book presents practical techniques such as SHAP, LIME, Grad-CAM, counterfactual explanations, and causal inference, supported by Python code examples for real-world applications. Case studies illustrate XAI's role in healthcare, finance, and policymaking, demonstrating its impact on fairness and decision support. The book also covers evaluation metrics for explanation quality, an overview of cutting-edge XAI tools and frameworks, and emerging research directions, such as interpretability in federated learning and ethical AI considerations. Designed for a broad audience, this resource equips readers with the theoretical insights and practical skills needed to master XAI. Hands-on examples and additional resources are available at the companion GitHub repository: https://github.com/Echoslayer/XAI_From_Classical_Models_to_LLMs.
Deep Learning and Machine Learning -- Natural Language Processing: From Theory to Application
Oct 30, 2024
With a focus on natural language processing (NLP) and the role of large language models (LLMs), we explore the intersection of machine learning, deep learning, and artificial intelligence. As artificial intelligence continues to revolutionize fields from healthcare to finance, NLP techniques such as tokenization, text classification, and entity recognition are essential for processing and understanding human language. This paper discusses advanced data preprocessing techniques and the use of frameworks like Hugging Face for implementing transformer-based models. Additionally, it highlights challenges such as handling multilingual data, reducing bias, and ensuring model robustness. By addressing key aspects of data processing and model fine-tuning, this work aims to provide insights into deploying effective and ethically sound AI solutions.
Deep Learning, Machine Learning -- Digital Signal and Image Processing: From Theory to Application
Oct 27, 2024Digital Signal Processing (DSP) and Digital Image Processing (DIP) with Machine Learning (ML) and Deep Learning (DL) are popular research areas in Computer Vision and related fields. We highlight transformative applications in image enhancement, filtering techniques, and pattern recognition. By integrating frameworks like the Discrete Fourier Transform (DFT), Z-Transform, and Fourier Transform methods, we enable robust data manipulation and feature extraction essential for AI-driven tasks. Using Python, we implement algorithms that optimize real-time data processing, forming a foundation for scalable, high-performance solutions in computer vision. This work illustrates the potential of ML and DL to advance DSP and DIP methodologies, contributing to artificial intelligence, automated feature extraction, and applications across diverse domains.
Deep Learning and Machine Learning -- Object Detection and Semantic Segmentation: From Theory to Applications
Oct 21, 2024This book offers an in-depth exploration of object detection and semantic segmentation, combining theoretical foundations with practical applications. It covers state-of-the-art advancements in machine learning and deep learning, with a focus on convolutional neural networks (CNNs), YOLO architectures, and transformer-based approaches like DETR. The book also delves into the integration of artificial intelligence (AI) techniques and large language models for enhanced object detection in complex environments. A thorough discussion of big data analysis is presented, highlighting the importance of data processing, model optimization, and performance evaluation metrics. By bridging the gap between traditional methods and modern deep learning frameworks, this book serves as a comprehensive guide for researchers, data scientists, and engineers aiming to leverage AI-driven methodologies in large-scale object detection tasks.
Jailbreaking and Mitigation of Vulnerabilities in Large Language Models
Oct 20, 2024Large Language Models (LLMs) have transformed artificial intelligence by advancing natural language understanding and generation, enabling applications across fields beyond healthcare, software engineering, and conversational systems. Despite these advancements in the past few years, LLMs have shown considerable vulnerabilities, particularly to prompt injection and jailbreaking attacks. This review analyzes the state of research on these vulnerabilities and presents available defense strategies. We roughly categorize attack approaches into prompt-based, model-based, multimodal, and multilingual, covering techniques such as adversarial prompting, backdoor injections, and cross-modality exploits. We also review various defense mechanisms, including prompt filtering, transformation, alignment techniques, multi-agent defenses, and self-regulation, evaluating their strengths and shortcomings. We also discuss key metrics and benchmarks used to assess LLM safety and robustness, noting challenges like the quantification of attack success in interactive contexts and biases in existing datasets. Identifying current research gaps, we suggest future directions for resilient alignment strategies, advanced defenses against evolving attacks, automation of jailbreak detection, and consideration of ethical and societal impacts. This review emphasizes the need for continued research and cooperation within the AI community to enhance LLM security and ensure their safe deployment.