 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Aleatoric to Epistemic: Exploring Uncertainty Quantification Techniques in Artificial Intelligence
Jan 05, 2025



Uncertainty quantification (UQ) is a critical aspect of artificial intelligence (AI) systems, particularly in high-risk domains such as healthcare, autonomous systems, and financial technology, where decision-making processes must account for uncertainty. This review explores the evolution of uncertainty quantification techniques in AI, distinguishing between aleatoric and epistemic uncertainties, and discusses the mathematical foundations and methods used to quantify these uncertainties. We provide an overview of advanced techniques, including probabilistic methods, ensemble learning, sampling-based approaches, and generative models, while also highlighting hybrid approaches that integrate domain-specific knowledge. Furthermore, we examine the diverse applications of UQ across various fields, emphasizing its impact on decision-making, predictive accuracy, and system robustness. The review also addresses key challenges such as scalability, efficiency, and integration with explainable AI, and outlines future directions for research in this rapidly developing area. Through this comprehensive survey, we aim to provide a deeper understanding of UQ's role in enhancing the reliability, safety, and trustworthiness of AI systems.
From Bench to Bedside: A Review of Clinical Trialsin Drug Discovery and Development
Dec 12, 2024Clinical trials are an indispensable part of the drug development process, bridging the gap between basic research and clinical application. During the development of new drugs, clinical trials are used not only to evaluate the safety and efficacy of the drug but also to explore its dosage, treatment regimens, and potential side effects. This review discusses the various stages of clinical trials, including Phase I (safety assessment), Phase II (preliminary efficacy evaluation), Phase III (large-scale validation), and Phase IV (post-marketing surveillance), highlighting the characteristics of each phase and their interrelationships. Additionally, the paper addresses the major challenges encountered in clinical trials, such as ethical issues, subject recruitment difficulties, diversity and representativeness concerns, and proposes strategies for overcoming these challenges. With the advancement of technology, innovative technologies such as artificial intelligence, big data, and digitalization are gradually transforming clinical trial design and implementation, improving trial efficiency and data quality. The article also looks forward to the future of clinical trials, particularly the impact of emerging therapies such as gene therapy and immunotherapy on trial design, as well as the importance of regulatory reforms and global collaboration. In conclusion, the core role of clinical trials in drug development will continue to drive the progress of innovative drug development and clinical treatment.
From Word Vectors to Multimodal Embeddings: Techniques, Applications, and Future Directions For Large Language Models
Nov 06, 2024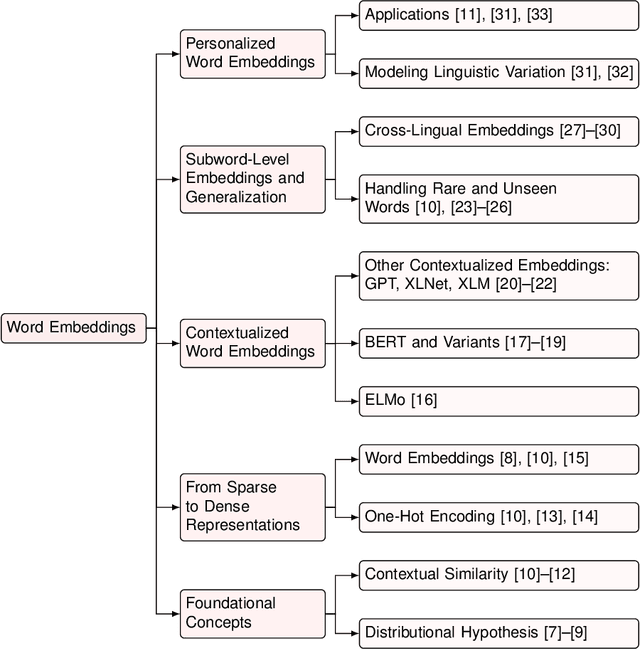


Word embeddings and language models have transformed natural language processing (NLP) by facilitating the representation of linguistic elements in continuous vector spaces. This review visits foundational concepts such as the distributional hypothesis and contextual similarity, tracing the evolution from sparse representations like one-hot encoding to dense embeddings including Word2Vec, GloVe, and fastText. We examine both static and contextualized embeddings, underscoring advancements in models such as ELMo, BERT, and GPT and their adaptations for cross-lingual and personalized applications. The discussion extends to sentence and document embeddings, covering aggregation methods and generative topic models, along with the application of embeddings in multimodal domains, including vision, robotics, and cognitive science. Advanced topics such as model compression, interpretability, numerical encoding, and bias mitigation are analyzed, addressing both technical challenges and ethical implications. Additionally, we identify future research directions, emphasizing the need for scalable training techniques, enhanced interpretability, and robust grounding in non-textual modalities. By synthesizing current methodologies and emerging trends, this survey offers researchers and practitioners an in-depth resource to push the boundaries of embedding-based language models.
Deep Learning and Machine Learning -- Natural Language Processing: From Theory to Application
Oct 30, 2024
With a focus on natural language processing (NLP) and the role of large language models (LLMs), we explore the intersection of machine learning, deep learning, and artificial intelligence. As artificial intelligence continues to revolutionize fields from healthcare to finance, NLP techniques such as tokenization, text classification, and entity recognition are essential for processing and understanding human language. This paper discusses advanced data preprocessing techniques and the use of frameworks like Hugging Face for implementing transformer-based models. Additionally, it highlights challenges such as handling multilingual data, reducing bias, and ensuring model robustness. By addressing key aspects of data processing and model fine-tuning, this work aims to provide insights into deploying effective and ethically sound AI solutions.
Large Language Model Benchmarks in Medical Tasks
Oct 28, 2024With the increasing application of large language models (LLMs) in the medical domain, evaluating these models' performance using benchmark datasets has become crucial. This paper presents a comprehensive survey of various benchmark datasets employed in medical LLM tasks. These datasets span multiple modalities including text, image, and multimodal benchmarks, focusing on different aspects of medical knowledge such as electronic health records (EHRs), doctor-patient dialogues, medical question-answering, and medical image captioning. The survey categorizes the datasets by modality, discussing their significance, data structure, and impact on the development of LLMs for clinical tasks such as diagnosis, report generation, and predictive decision support. Key benchmarks include MIMIC-III, MIMIC-IV, BioASQ, PubMedQA, and CheXpert, which have facilitated advancements in tasks like medical report generation, clinical summarization, and synthetic data generation. The paper summarizes the challenges and opportunities in leveraging these benchmarks for advancing multimodal medical intelligence, emphasizing the need for datasets with a greater degree of language diversity, structured omics data, and innovative approaches to synthesis. This work also provides a foundation for future research in the application of LLMs in medicine, contributing to the evolving field of medical artificial intelligence.