 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexLLM: Exploring LLM Customization for Moving Target Defense on Black-Box LLMs Against Jailbreak Attacks
Paper and Code
Dec 10, 2024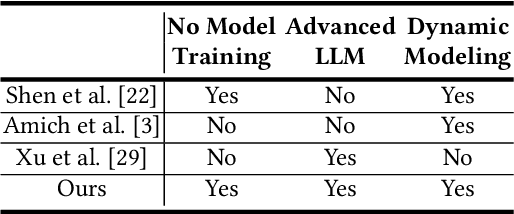
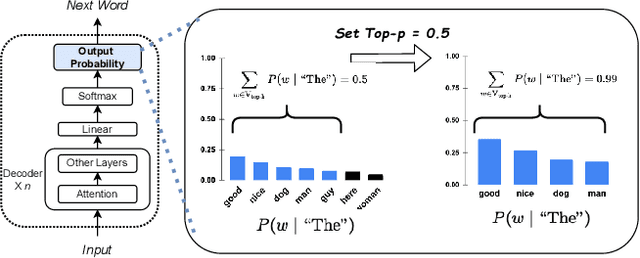
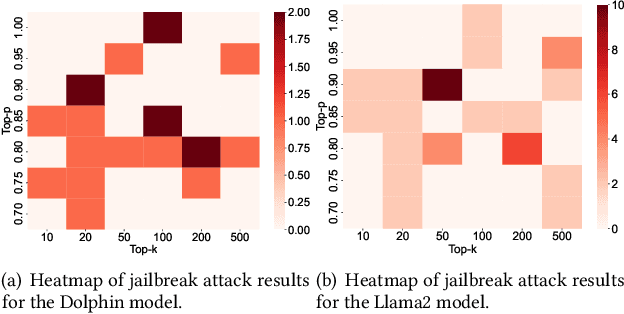
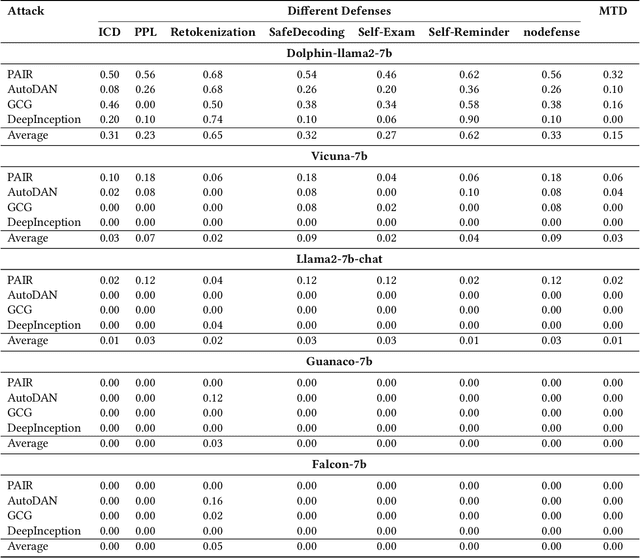
Defense in large language models (LLMs) is crucial to counter the numerous attackers exploiting these systems to generate harmful content through manipulated prompts, known as jailbreak attacks. Although many defense strategies have been proposed, they often require access to the model's internal structure or need additional training, which is impractical for service providers using LLM APIs, such as OpenAI APIs or Claude APIs. In this paper, we propose a moving target defense approach that alters decoding hyperparameters to enhance model robustness against various jailbreak attacks. Our approach does not require access to the model's internal structure and incurs no additional training costs. The proposed defense includes two key components: (1) optimizing the decoding strategy by identifying and adjusting decoding hyperparameters that influence token generation probabilities, and (2) transforming the decoding hyperparameters and model system prompts into dynamic targets, which are continuously altered during each runtime. By continuously modifying decoding strategies and prompts, the defense effectively mitigates the existing attacks. Our results demonstrate that our defense is the most effective against jailbreak attacks in three of the models tested when using LLMs as black-box APIs. Moreover, our defense offers lower inference costs and maintains comparable response quality, making it a potential layer of protection when used alongside other defense methods.