 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALCS: An Open-Source Mandarin-English Code-Switching Corpus and a Speech Recognition Baseline
Jun 27, 2022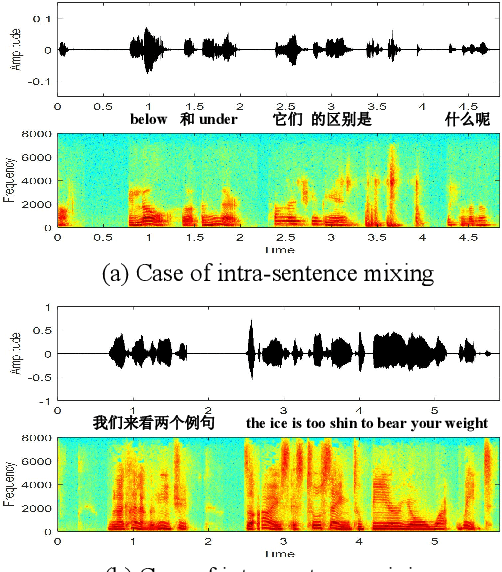
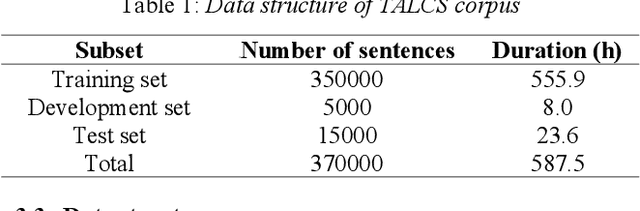
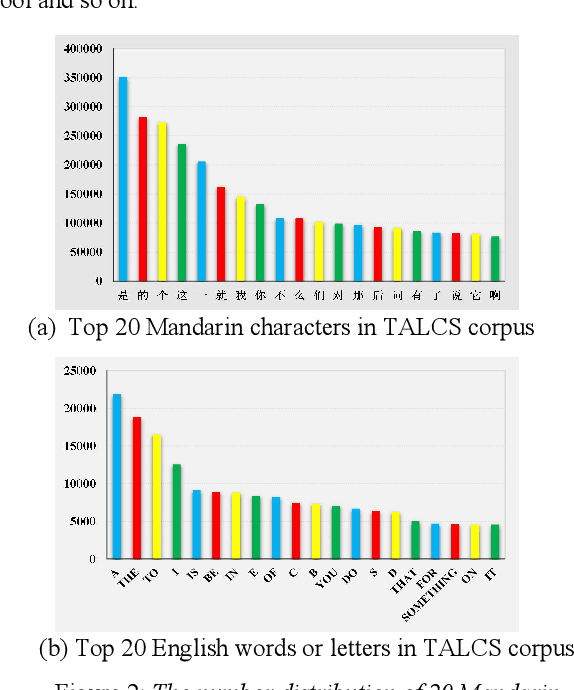
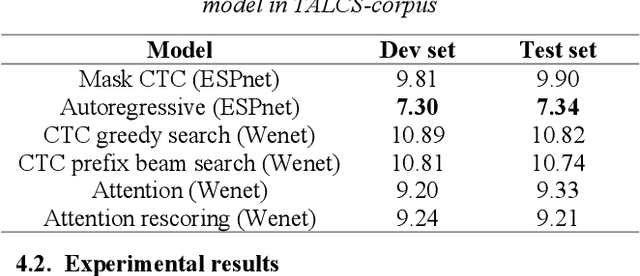
This paper introduces a new corpus of Mandarin-English code-switching speech recognition--TALCS corpus, suitable for training and evaluating code-switching speech recognition systems. TALCS corpus is derived from real online one-to-one English teaching scenes in TAL education group, which contains roughly 587 hours of speech sampled at 16 kHz. To our best knowledge, TALCS corpus is the largest well labeled Mandarin-English code-switching open source automatic speech recognition (ASR) dataset in the world. In this paper, we will introduce the recording procedure in detail, including audio capturing devices and corpus environments. And the TALCS corpus is freely available for download under the permissive license1. Using TALCS corpus, we conduct ASR experiments in two popular speech recognition toolkits to make a baseline system, including ESPnet and Wenet. The Mixture Error Rate (MER) performance in the two speech recognition toolkits is compared in TALCS corpus. The experimental results implies that the quality of audio recordings and transcriptions are promising and the baseline system is workable.
A Character-level Span-based Model for Mandarin Prosodic Structure Prediction
Mar 31, 2022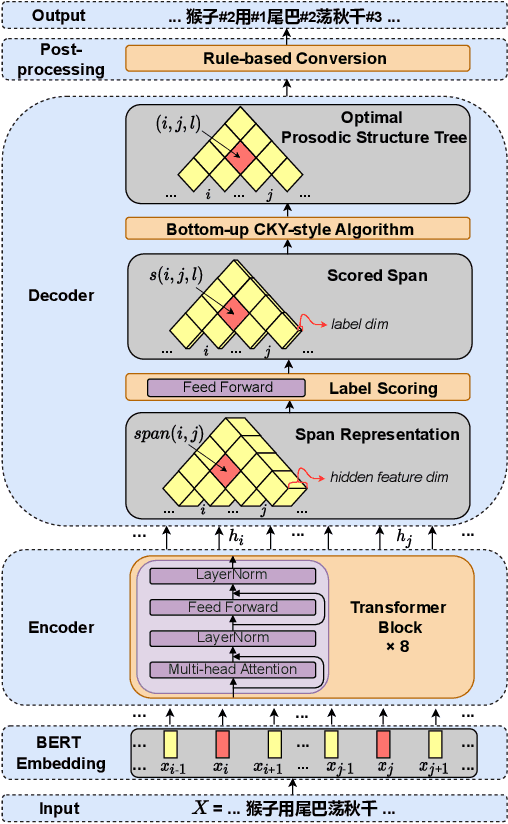

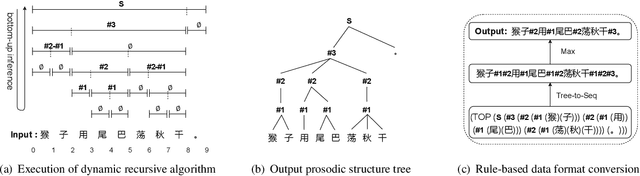
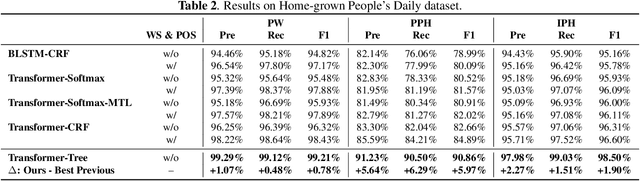
The accuracy of prosodic structure prediction is crucial to the naturalness of synthesized speech in Mandarin text-to-speech system, but now is limited by widely-used sequence-to-sequence framework and error accumulation from previous word segmentation results. In this paper, we propose a span-based Mandarin prosodic structure prediction model to obtain an optimal prosodic structure tree, which can be converted to corresponding prosodic label sequence. Instead of the prerequisite for word segmentation, rich linguistic features are provided by Chinese character-level BERT and sent to encoder with self-attention architecture. On top of this, span representation and label scoring are used to describe all possible prosodic structure trees, of which each tree has its corresponding score. To find the optimal tree with the highest score for a given sentence, a bottom-up CKY-style algorithm is further used. The proposed method can predict prosodic labels of different levels at the same time and accomplish the process directly from Chinese characters in an end-to-end manner. Experiment results on two real-world datasets demonstrate the excellent performance of our span-based method over all sequence-to-sequence baseline approaches.
Multi-reference Tacotron by Intercross Training for Style Disentangling,Transfer and Control in Speech Synthesis
Apr 04, 2019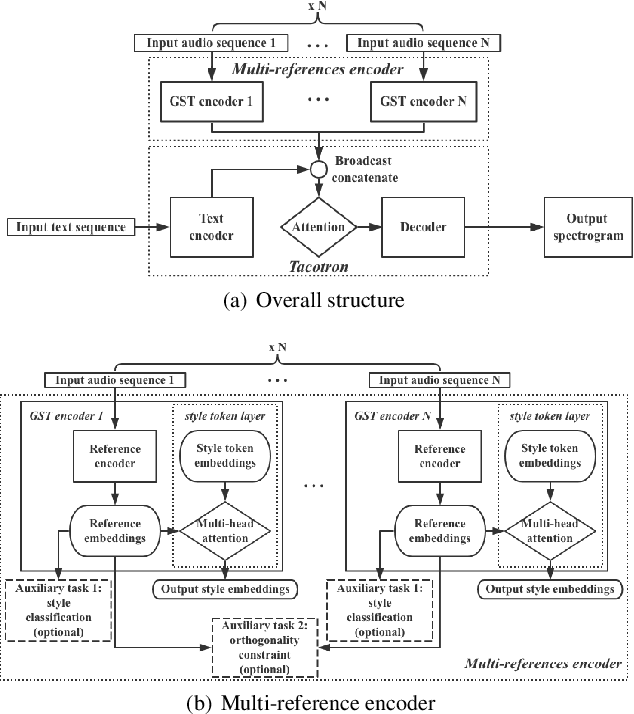
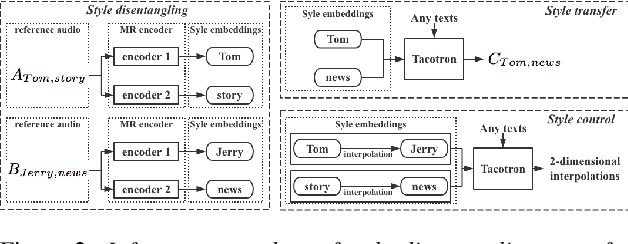
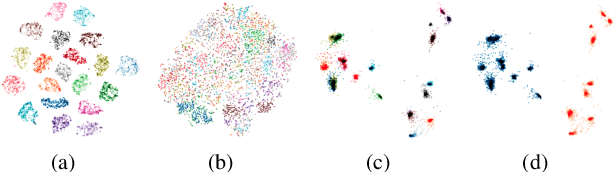

Speech style control and transfer techniques aim to enrich the diversity and expressiveness of synthesized speech. Existing approaches model all speech styles into one representation, lacking the ability to control a specific speech feature independently. To address this issue, we introduce a novel multi-reference structure to Tacotron and propose intercross training approach, which together ensure that each sub-encoder of the multi-reference encoder independently disentangles and controls a specific style. Experimental results show that our model is able to control and transfer desired speech styles individually.