Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-reference Tacotron by Intercross Training for Style Disentangling,Transfer and Control in Speech Synthesis
Paper and Code
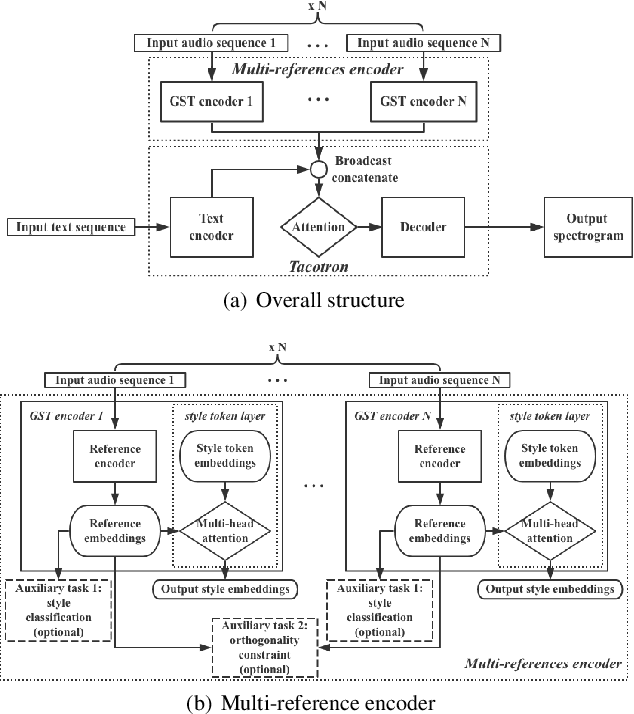
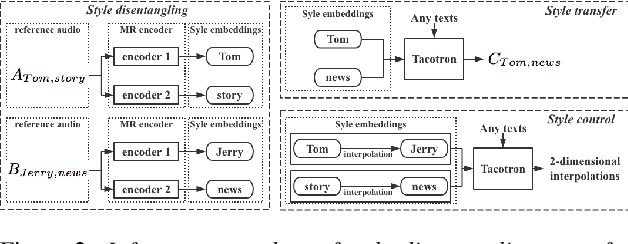
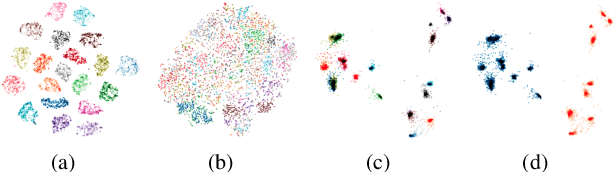

Speech style control and transfer techniques aim to enrich the diversity and expressiveness of synthesized speech. Existing approaches model all speech styles into one representation, lacking the ability to control a specific speech feature independently. To address this issue, we introduce a novel multi-reference structure to Tacotron and propose intercross training approach, which together ensure that each sub-encoder of the multi-reference encoder independently disentangles and controls a specific style. Experimental results show that our model is able to control and transfer desired speech styles individually.
* Submitted for Interspeech 2019, 5 pages
View paper on