 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Character-level Span-based Model for Mandarin Prosodic Structure Prediction
Paper and Code
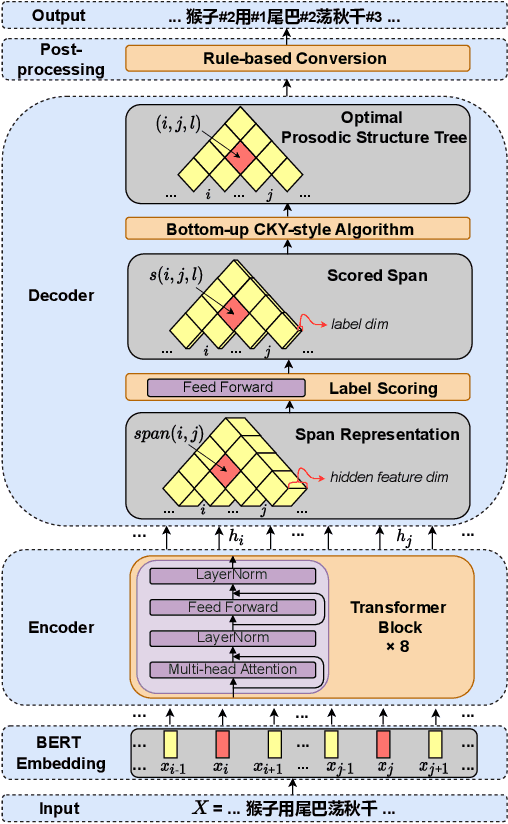

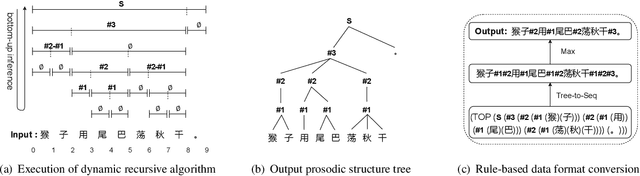
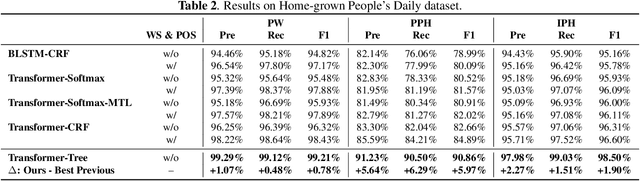
The accuracy of prosodic structure prediction is crucial to the naturalness of synthesized speech in Mandarin text-to-speech system, but now is limited by widely-used sequence-to-sequence framework and error accumulation from previous word segmentation results. In this paper, we propose a span-based Mandarin prosodic structure prediction model to obtain an optimal prosodic structure tree, which can be converted to corresponding prosodic label sequence. Instead of the prerequisite for word segmentation, rich linguistic features are provided by Chinese character-level BERT and sent to encoder with self-attention architecture. On top of this, span representation and label scoring are used to describe all possible prosodic structure trees, of which each tree has its corresponding score. To find the optimal tree with the highest score for a given sentence, a bottom-up CKY-style algorithm is further used. The proposed method can predict prosodic labels of different levels at the same time and accomplish the process directly from Chinese characters in an end-to-end manner. Experiment results on two real-world datasets demonstrate the excellent performance of our span-based method over all sequence-to-sequence baseline approaches.