 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCR-Graph: Spatial-Causal Relationships based Graph Reasoning Network for Human Action Prediction
Paper and Code
Nov 22, 2019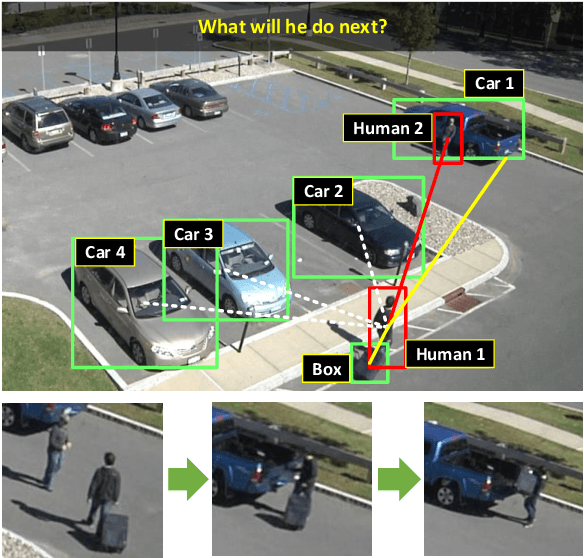


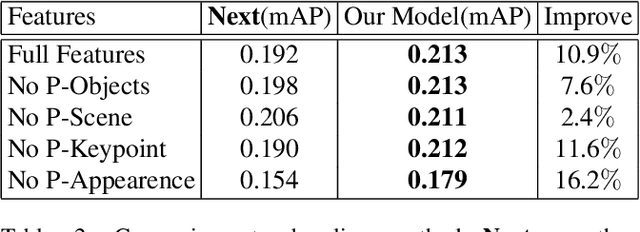
Technologies to predict human actions are extremely important for applications such as human robot cooperation and autonomous driving. However, a majority of the existing algorithms focus on exploiting visual features of the videos and do not consider the mining of relationships, which include spatial relationships between human and scene elements as well as causal relationships in temporal action sequences. In fact, human beings are good at using spatial and causal relational reasoning mechanism to predict the actions of others. Inspired by this idea, we proposed a Spatial and Causal Relationship based Graph Reasoning Network (SCR-Graph), which can be used to predict human actions by modeling the action-scene relationship, and causal relationship between actions, in spatial and temporal dimensions respectively. Here, in spatial dimension, a hierarchical graph attention module is designed by iteratively aggregating the features of different kinds of scene elements in different level. In temporal dimension, we designed a knowledge graph based causal reasoning module and map the past actions to temporal causal features through Diffusion RNN. Finally, we integrated the causality features into the heterogeneous graph in the form of shadow node, and introduced a self-attention module to determine the time when the knowledge graph information should be activated. Extensive experimental results on the VIRAT datasets demonstrate the favorable performance of the proposed framework.