 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stream network-driven vision-based tactile sensor for object feature extraction and fusion perception
Oct 14, 2025



Tactile perception is crucial for embodied intelligent robots to recognize objects. Vision-based tactile sensors extract object physical attributes multidimensionally using high spatial resolution; however, this process generates abundant redundant information. Furthermore, single-dimensional extraction, lacking effective fusion, fails to fully characterize object attributes. These challenges hinder the improvement of recognition accuracy. To address this issue, this study introduces a two-stream network feature extraction and fusion perception strategy for vision-based tactile systems. This strategy employs a distributed approach to extract internal and external object features. It obtains depth map information through three-dimensional reconstruction while simultaneously acquiring hardness information by measuring contact force data. After extracting features with a convolutional neural network (CNN), weighted fusion is applied to create a more informative and effective feature representation. In standard tests on objects of varying shapes and hardness, the force prediction error is 0.06 N (within a 12 N range). Hardness recognition accuracy reaches 98.0%, and shape recognition accuracy reaches 93.75%. With fusion algorithms, object recognition accuracy in actual grasping scenarios exceeds 98.5%. Focused on object physical attributes perception, this method enhances the artificial tactile system ability to transition from perception to cognition, enabling its use in embodied perception applications.
Vision-based Tactile Image Generation via Contact Condition-guided Diffusion Model
Dec 02, 2024



Vision-based tactile sensors, through high-resolution optical measurements, can effectively perceive the geometric shape of objects and the force information during the contact process, thus helping robots acquire higher-dimensional tactile data. Vision-based tactile sensor simulation supports the acquisition and understanding of tactile information without physical sensors by accurately capturing and analyzing contact behavior and physical properties. However, the complexity of contact dynamics and lighting modeling limits the accurate reproduction of real sensor responses in simulations, making it difficult to meet the needs of different sensor setups and affecting the reliability and effectiveness of strategy transfer to practical applications. In this letter, we propose a contact-condition guided diffusion model that maps RGB images of objects and contact force data to high-fidelity, detail-rich vision-based tactile sensor images. Evaluations show that the three-channel tactile images generated by this method achieve a 60.58% reduction in mean squared error and a 38.1% reduction in marker displacement error compared to existing approaches based on lighting model and mechanical model, validating the effectiveness of our approach. The method is successfully applied to various types of tactile vision sensors and can effectively generate corresponding tactile images under complex loads. Additionally, it demonstrates outstanding reconstruction of fine texture features of objects in a Montessori tactile board texture generation task.
Enhanced Information Extraction from Cylindrical Visual-Tactile Sensors via Image Fusion
Nov 07, 2023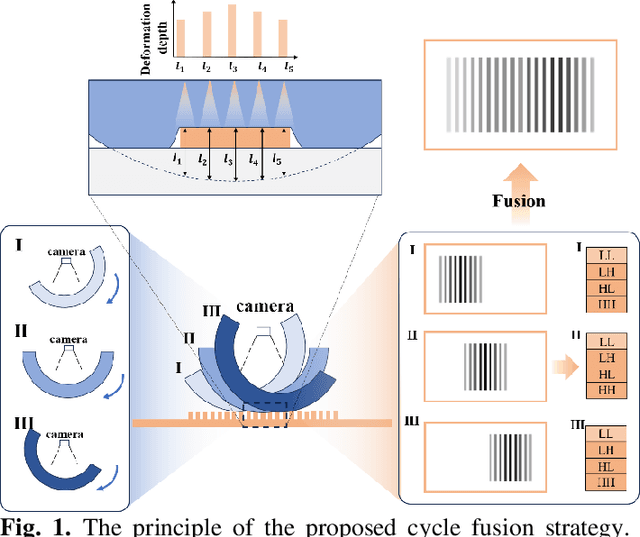
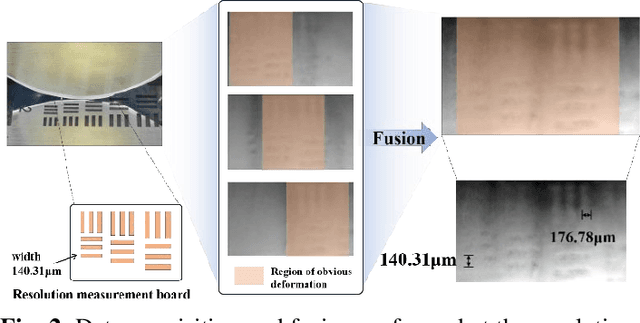


Vision-based tactile sensors equipped with planar contact structures acquire the shape, force, and motion states of objects in contact. The limited planar contact area presents a challenge in acquiring information about larger target objects. In contrast, vision-based tactile sensors with cylindrical contact structures could extend the contact area by rolling, which can acquire much tactile information that exceeds the sensing projection area in a single contact. However, the tactile data acquired by cylindrical structures does not consistently correspond to the same depth level. Therefore, stitching and analyzing the data in an extended contact area is a challenging problem. In this work, we propose an image fusion method based on cylindrical vision-based tactile sensors. The method takes advantage of the changing characteristics of the contact depth of cylindrical structures, extracts the effective information of different contact depths in the frequency domain, and performs differential fusion for the information characteristics. The results show that in object contact confronting an area larger than single sensing, the images fused with our proposed method have higher information and structural similarity compared with the method of stitching based on motion distance sampling. Meanwhile, it is robust to sampling time. We complement this method with a deep neural network to illustrate its potential for fusing and recognizing object contact information using cylindrical vision-based tactile sensors.
A Vision-Based Tactile Sensing System for Multimodal Contact Information Perception via Neural Network
Oct 03, 2023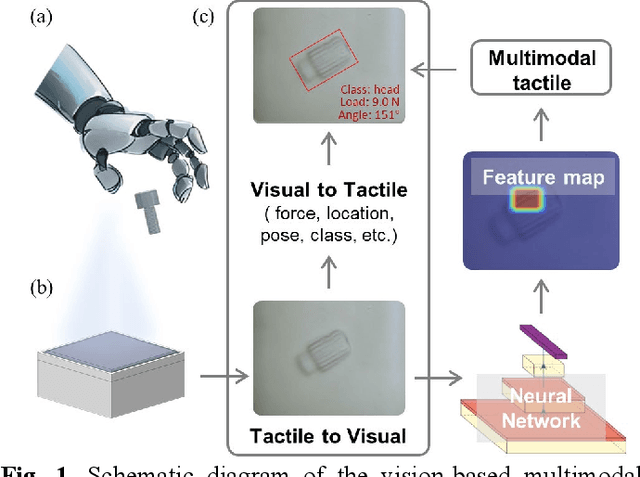
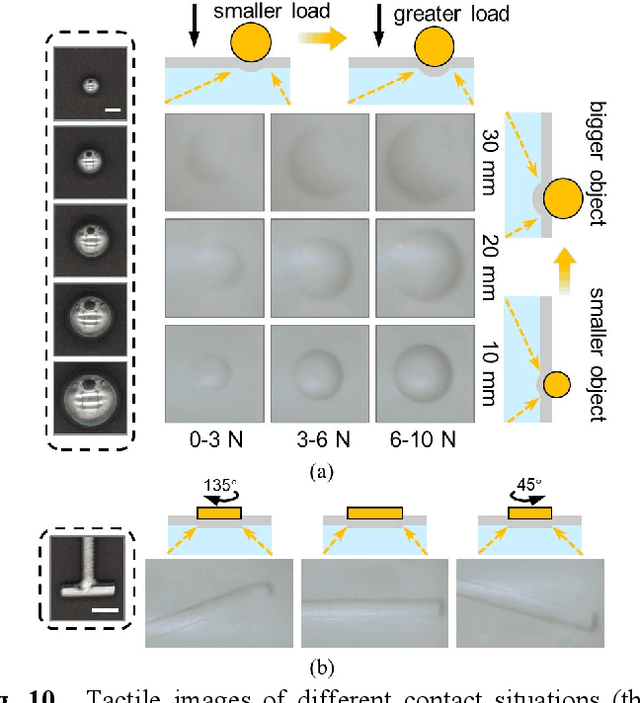
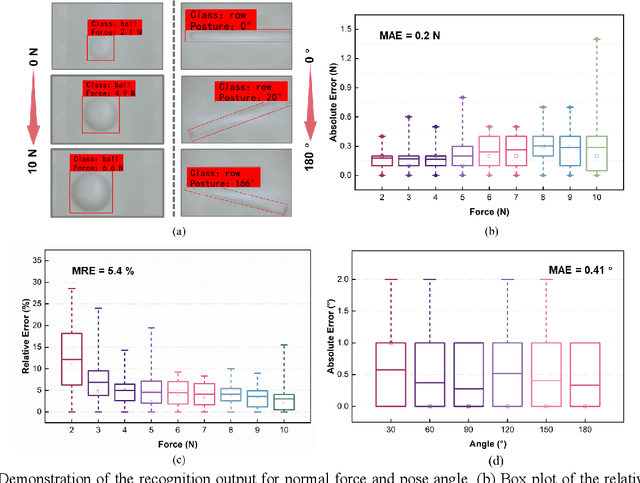
In general, robotic dexterous hands are equipped with various sensors for acquiring multimodal contact information such as position, force, and pose of the grasped object. This multi-sensor-based design adds complexity to the robotic system. In contrast, vision-based tactile sensors employ specialized optical designs to enable the extraction of tactile information across different modalities within a single system. Nonetheless, the decoupling design for different modalities in common systems is often independent. Therefore, as the dimensionality of tactile modalities increases, it poses more complex challenges in data processing and decoupling, thereby limiting its application to some extent. Here, we developed a multimodal sensing system based on a vision-based tactile sensor, which utilizes visual representations of tactile information to perceive the multimodal contact information of the grasped object. The visual representations contain extensive content that can be decoupled by a deep neural network to obtain multimodal contact information such as classification, position, posture, and force of the grasped object. The results show that the tactile sensing system can perceive multimodal tactile information using only one single sensor and without different data decoupling designs for different modal tactile information, which reduces the complexity of the tactile system and demonstrates the potential for multimodal tactile integration in various fields such as biomedicine, biology, and robotics.
Synchronous Adversarial Feature Learning for LiDAR based Loop Closure Detection
Apr 05, 2018
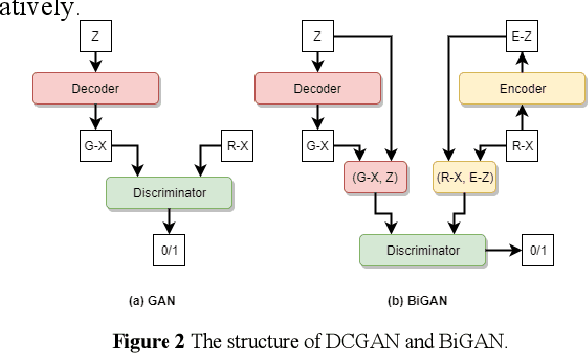
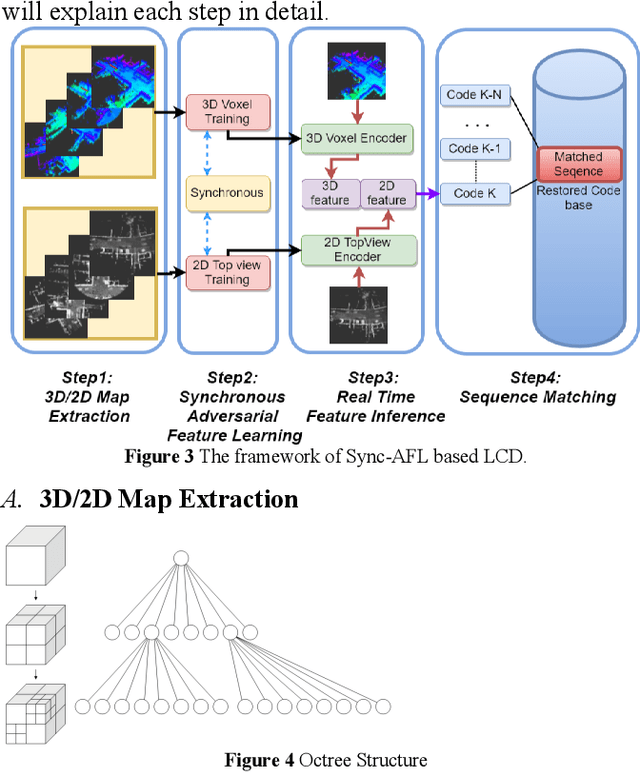
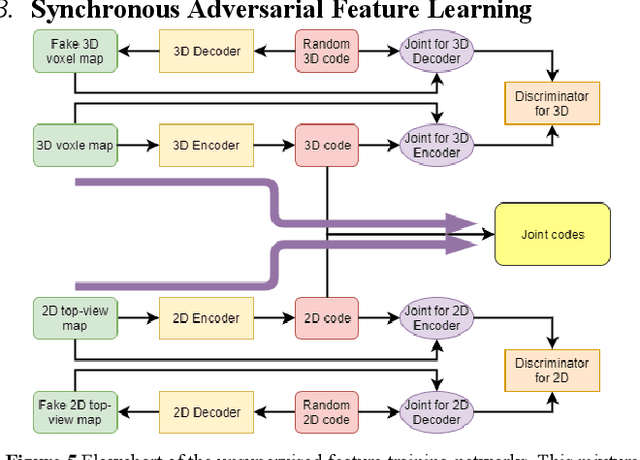
Loop Closure Detection (LCD) is the essential module in the simultaneous localization and mapping (SLAM) task. In the current appearance-based SLAM methods, the visual inputs are usually affected by illumination, appearance and viewpoints changes. Comparing to the visual inputs, with the active property, light detection and ranging (LiDAR) based point-cloud inputs are invariant to the illumination and appearance changes. In this paper, we extract 3D voxel maps and 2D top view maps from LiDAR inputs, and the former could capture the local geometry into a simplified 3D voxel format, the later could capture the local road structure into a 2D image format. However, the most challenge problem is to obtain efficient features from 3D and 2D maps to against the viewpoints difference. In this paper, we proposed a synchronous adversarial feature learning method for the LCD task, which could learn the higher level abstract features from different domains without any label data. To the best of our knowledge, this work is the first to extract multi-domain adversarial features for the LCD task in real time. To investigate the performance, we test the proposed method on the KITTI odometry dataset. The extensive experiments results show that, the proposed method could largely improve LCD accuracy even under huge viewpoints differences.