 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-YOLOMS: Large Language Model-based Semantic Interpretation and Fault Diagnosis for Wind Turbine Components
Nov 13, 2025The health condition of wind turbine (WT) components is crucial for ensuring stable and reliable operation. However, existing fault detection methods are largely limited to visual recognition, producing structured outputs that lack semantic interpretability and fail to support maintenance decision-making. To address these limitations, this study proposes an integrated framework that combines YOLOMS with a large language model (LLM) for intelligent fault analysis and diagnosis. Specifically, YOLOMS employs multi-scale detection and sliding-window cropping to enhance fault feature extraction, while a lightweight key-value (KV) mapping module bridges the gap between visual outputs and textual inputs. This module converts YOLOMS detection results into structured textual representations enriched with both qualitative and quantitative attributes. A domain-tuned LLM then performs semantic reasoning to generate interpretable fault analyses and maintenance recommendations. Experiments on real-world datasets demonstrate that the proposed framework achieves a fault detection accuracy of 90.6\% and generates maintenance reports with an average accuracy of 89\%, thereby improving the interpretability of diagnostic results and providing practical decision support for the operation and maintenance of wind turbines.
Two-stream network-driven vision-based tactile sensor for object feature extraction and fusion perception
Oct 14, 2025



Tactile perception is crucial for embodied intelligent robots to recognize objects. Vision-based tactile sensors extract object physical attributes multidimensionally using high spatial resolution; however, this process generates abundant redundant information. Furthermore, single-dimensional extraction, lacking effective fusion, fails to fully characterize object attributes. These challenges hinder the improvement of recognition accuracy. To address this issue, this study introduces a two-stream network feature extraction and fusion perception strategy for vision-based tactile systems. This strategy employs a distributed approach to extract internal and external object features. It obtains depth map information through three-dimensional reconstruction while simultaneously acquiring hardness information by measuring contact force data. After extracting features with a convolutional neural network (CNN), weighted fusion is applied to create a more informative and effective feature representation. In standard tests on objects of varying shapes and hardness, the force prediction error is 0.06 N (within a 12 N range). Hardness recognition accuracy reaches 98.0%, and shape recognition accuracy reaches 93.75%. With fusion algorithms, object recognition accuracy in actual grasping scenarios exceeds 98.5%. Focused on object physical attributes perception, this method enhances the artificial tactile system ability to transition from perception to cognition, enabling its use in embodied perception applications.
ErgoChat: a Visual Query System for the Ergonomic Risk Assessment of Construction Workers
Dec 27, 2024



In the construction sector, workers often endure prolonged periods of high-intensity physical work and prolonged use of tools, resulting in injuries and illnesses primarily linked to postural ergonomic risks, a longstanding predominant health concern. To mitigate these risks, researchers have applied various technological methods to identify the ergonomic risks that construction workers face. However, traditional ergonomic risk assessment (ERA) techniques do not offer interactive feedback. The rapidly developing vision-language models (VLMs), capable of generating textual descriptions or answering questions about ergonomic risks based on image inputs, have not yet received widespread attention. This research introduces an interactive visual query system tailored to assess the postural ergonomic risks of construction workers. The system's capabilities include visual question answering (VQA), which responds to visual queries regarding workers' exposure to postural ergonomic risks, and image captioning (IC), which generates textual descriptions of these risks from images. Additionally, this study proposes a dataset designed for training and testing such methodologies. Systematic testing indicates that the VQA functionality delivers an accuracy of 96.5%. Moreover, evaluations using nine metrics for IC and assessments from human experts indicate that the proposed approach surpasses the performance of a method using the same architecture trained solely on generic datasets. This study sets a new direction for future developments in interactive ERA using generative artificial intelligence (AI) technologies.
Vision-based Tactile Image Generation via Contact Condition-guided Diffusion Model
Dec 02, 2024



Vision-based tactile sensors, through high-resolution optical measurements, can effectively perceive the geometric shape of objects and the force information during the contact process, thus helping robots acquire higher-dimensional tactile data. Vision-based tactile sensor simulation supports the acquisition and understanding of tactile information without physical sensors by accurately capturing and analyzing contact behavior and physical properties. However, the complexity of contact dynamics and lighting modeling limits the accurate reproduction of real sensor responses in simulations, making it difficult to meet the needs of different sensor setups and affecting the reliability and effectiveness of strategy transfer to practical applications. In this letter, we propose a contact-condition guided diffusion model that maps RGB images of objects and contact force data to high-fidelity, detail-rich vision-based tactile sensor images. Evaluations show that the three-channel tactile images generated by this method achieve a 60.58% reduction in mean squared error and a 38.1% reduction in marker displacement error compared to existing approaches based on lighting model and mechanical model, validating the effectiveness of our approach. The method is successfully applied to various types of tactile vision sensors and can effectively generate corresponding tactile images under complex loads. Additionally, it demonstrates outstanding reconstruction of fine texture features of objects in a Montessori tactile board texture generation task.
RS-DFM: A Remote Sensing Distributed Foundation Model for Diverse Downstream Tasks
Jun 11, 2024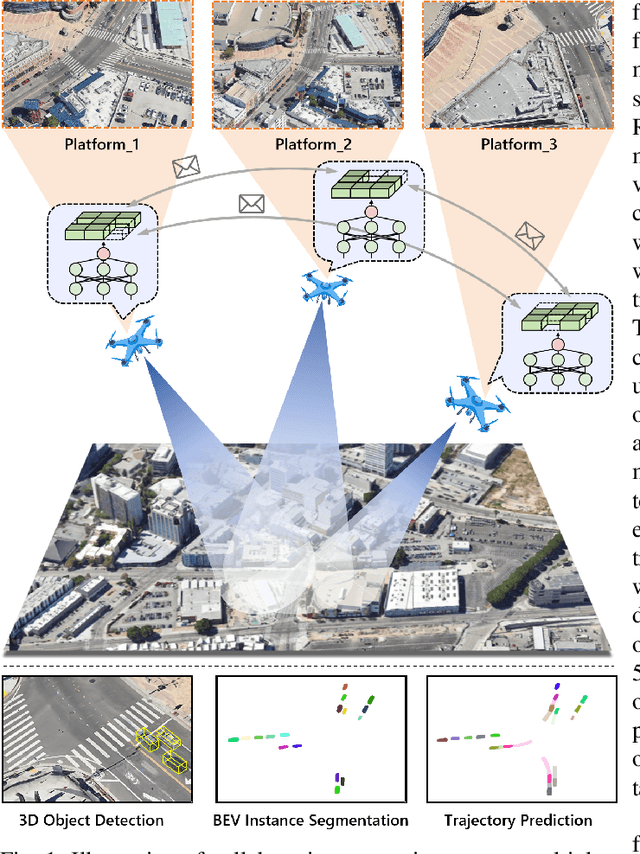
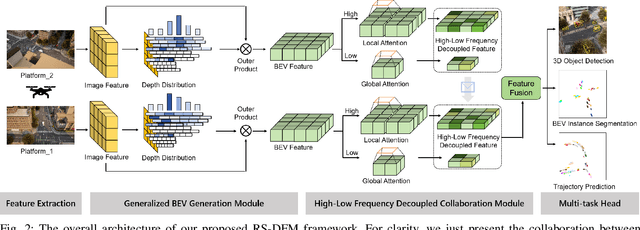
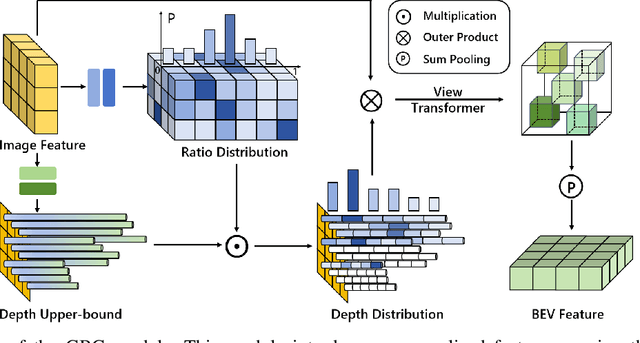
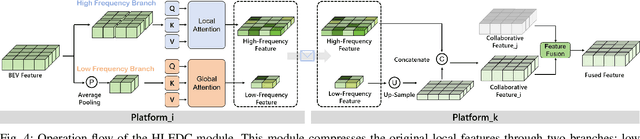
Remote sensing lightweight foundation models have achieved notable success in online perception within remote sensing. However, their capabilities are restricted to performing online inference solely based on their own observations and models, thus lacking a comprehensive understanding of large-scale remote sensing scenarios. To overcome this limitation, we propose a Remote Sensing Distributed Foundation Model (RS-DFM) based on generalized information mapping and interaction. This model can realize online collaborative perception across multiple platforms and various downstream tasks by mapping observations into a unified space and implementing a task-agnostic information interaction strategy. Specifically, we leverage the ground-based geometric prior of remote sensing oblique observations to transform the feature mapping from absolute depth estimation to relative depth estimation, thereby enhancing the model's ability to extract generalized features across diverse heights and perspectives. Additionally, we present a dual-branch information compression module to decouple high-frequency and low-frequency feature information, achieving feature-level compression while preserving essential task-agnostic details. In support of our research, we create a multi-task simulation dataset named AirCo-MultiTasks for multi-UAV collaborative observation. We also conduct extensive experiments, including 3D object detection, instance segmentation, and trajectory prediction. The numerous results demonstrate that our RS-DFM achieves state-of-the-art performance across various downstream tasks.
Drones Help Drones: A Collaborative Framework for Multi-Drone Object Trajectory Prediction and Beyond
May 23, 2024



Collaborative trajectory prediction can comprehensively forecast the future motion of objects through multi-view complementary information. However, it encounters two main challenges in multi-drone collaboration settings. The expansive aerial observations make it difficult to generate precise Bird's Eye View (BEV) representations. Besides, excessive interactions can not meet real-time prediction requirements within the constrained drone-based communication bandwidth. To address these problems, we propose a novel framework named "Drones Help Drones" (DHD). Firstly, we incorporate the ground priors provided by the drone's inclined observation to estimate the distance between objects and drones, leading to more precise BEV generation. Secondly, we design a selective mechanism based on the local feature discrepancy to prioritize the critical information contributing to prediction tasks during inter-drone interactions. Additionally, we create the first dataset for multi-drone collaborative prediction, named "Air-Co-Pred", and conduct quantitative and qualitative experiments to validate the effectiveness of our DHD framework.The results demonstrate that compared to state-of-the-art approaches, DHD reduces position deviation in BEV representations by over 20% and requires only a quarter of the transmission ratio for interactions while achieving comparable prediction performance. Moreover, DHD also shows promising generalization to the collaborative 3D object detection in CoPerception-UAVs.
Enhanced Information Extraction from Cylindrical Visual-Tactile Sensors via Image Fusion
Nov 07, 2023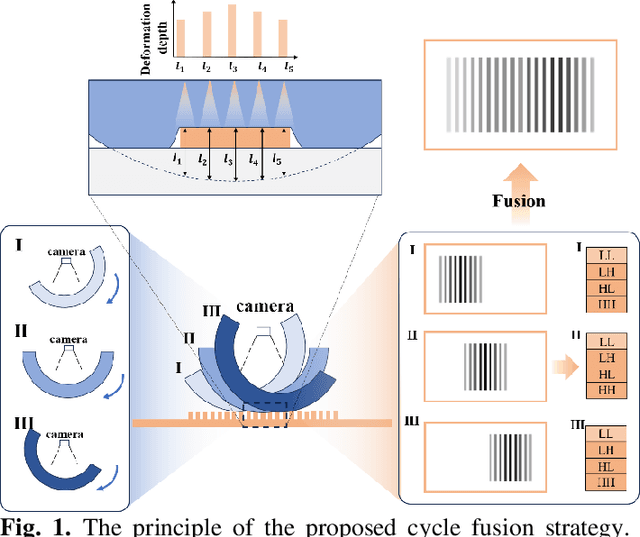
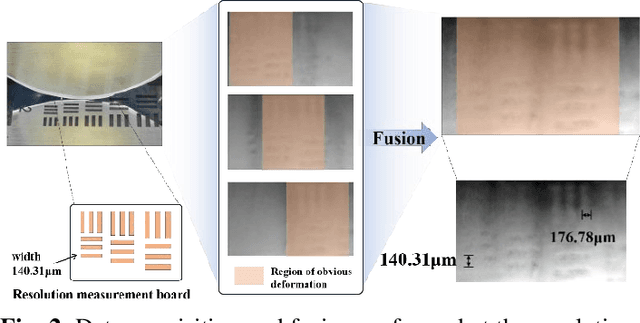


Vision-based tactile sensors equipped with planar contact structures acquire the shape, force, and motion states of objects in contact. The limited planar contact area presents a challenge in acquiring information about larger target objects. In contrast, vision-based tactile sensors with cylindrical contact structures could extend the contact area by rolling, which can acquire much tactile information that exceeds the sensing projection area in a single contact. However, the tactile data acquired by cylindrical structures does not consistently correspond to the same depth level. Therefore, stitching and analyzing the data in an extended contact area is a challenging problem. In this work, we propose an image fusion method based on cylindrical vision-based tactile sensors. The method takes advantage of the changing characteristics of the contact depth of cylindrical structures, extracts the effective information of different contact depths in the frequency domain, and performs differential fusion for the information characteristics. The results show that in object contact confronting an area larger than single sensing, the images fused with our proposed method have higher information and structural similarity compared with the method of stitching based on motion distance sampling. Meanwhile, it is robust to sampling time. We complement this method with a deep neural network to illustrate its potential for fusing and recognizing object contact information using cylindrical vision-based tactile sensors.
A Vision-Based Tactile Sensing System for Multimodal Contact Information Perception via Neural Network
Oct 03, 2023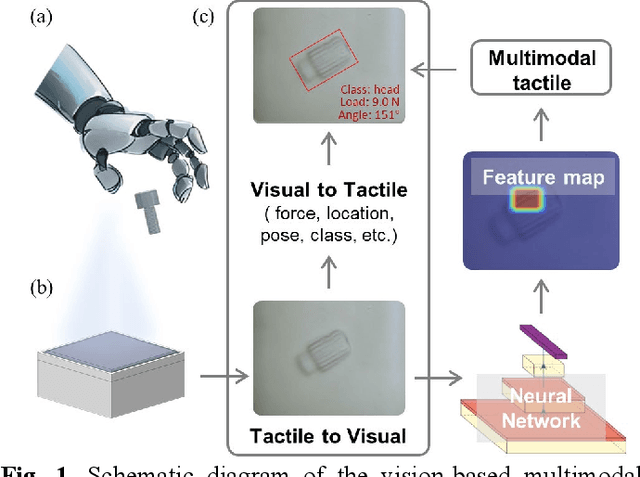
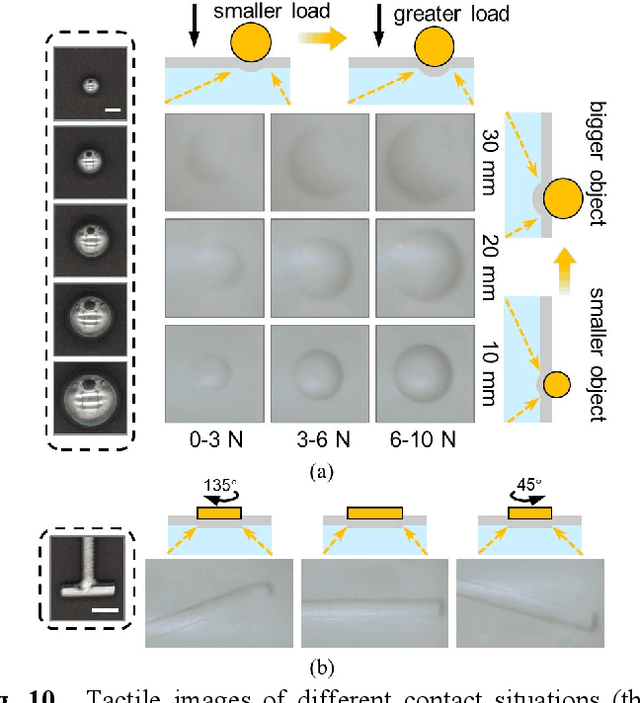
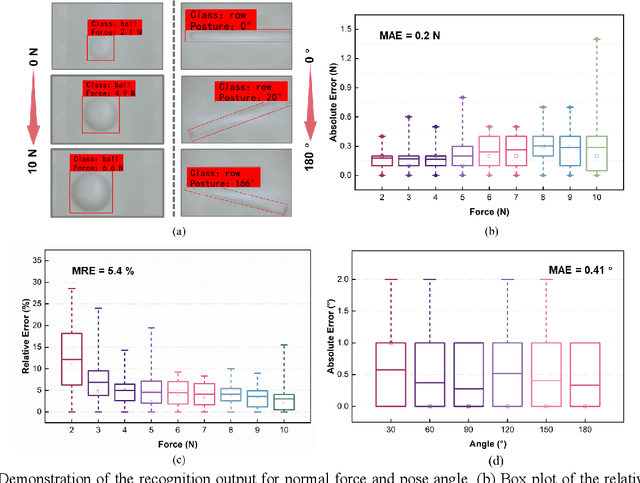
In general, robotic dexterous hands are equipped with various sensors for acquiring multimodal contact information such as position, force, and pose of the grasped object. This multi-sensor-based design adds complexity to the robotic system. In contrast, vision-based tactile sensors employ specialized optical designs to enable the extraction of tactile information across different modalities within a single system. Nonetheless, the decoupling design for different modalities in common systems is often independent. Therefore, as the dimensionality of tactile modalities increases, it poses more complex challenges in data processing and decoupling, thereby limiting its application to some extent. Here, we developed a multimodal sensing system based on a vision-based tactile sensor, which utilizes visual representations of tactile information to perceive the multimodal contact information of the grasped object. The visual representations contain extensive content that can be decoupled by a deep neural network to obtain multimodal contact information such as classification, position, posture, and force of the grasped object. The results show that the tactile sensing system can perceive multimodal tactile information using only one single sensor and without different data decoupling designs for different modal tactile information, which reduces the complexity of the tactile system and demonstrates the potential for multimodal tactile integration in various fields such as biomedicine, biology, and robotics.
DCP-Net: A Distributed Collaborative Perception Network for Remote Sensing Semantic Segmentation
Sep 05, 2023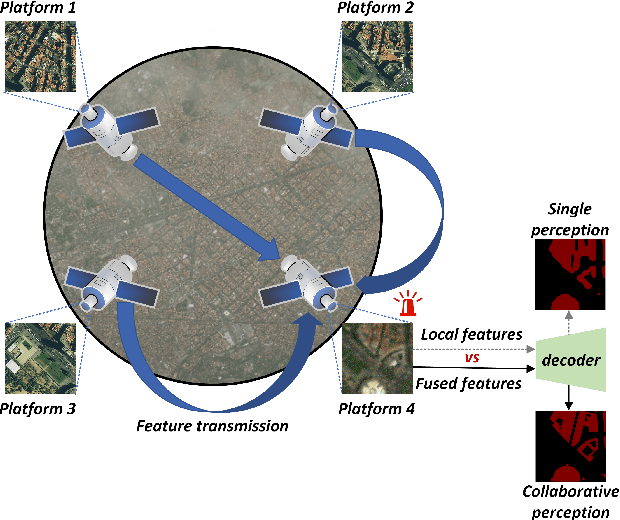

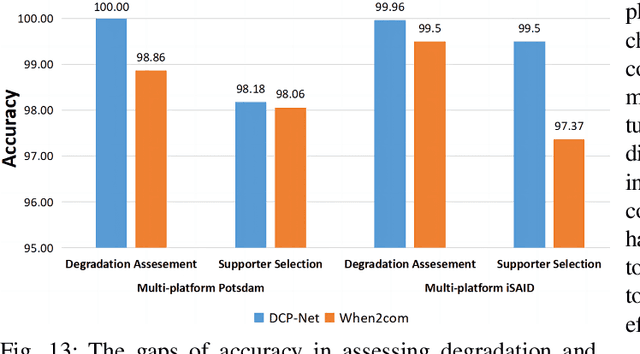
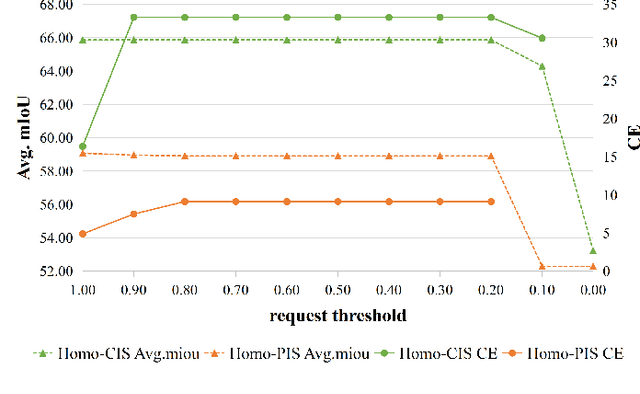
Onboard intelligent processing is widely applied in emergency tasks in the field of remote sensing. However, it is predominantly confined to an individual platform with a limited observation range as well as susceptibility to interference, resulting in limited accuracy. Considering the current state of multi-platform collaborative observation, this article innovatively presents a distributed collaborative perception network called DCP-Net. Firstly, the proposed DCP-Net helps members to enhance perception performance by integrating features from other platforms. Secondly, a self-mutual information match module is proposed to identify collaboration opportunities and select suitable partners, prioritizing critical collaborative features and reducing redundant transmission cost. Thirdly, a related feature fusion module is designed to address the misalignment between local and collaborative features, improving the quality of fused features for the downstream task. We conduct extensive experiments and visualization analyses using three semantic segmentation datasets, including Potsdam, iSAID and DFC23. The results demonstrate that DCP-Net outperforms the existing methods comprehensively, improving mIoU by 2.61%~16.89% at the highest collaboration efficiency, which promotes the performance to a state-of-the-art level.
OGMN: Occlusion-guided Multi-task Network for Object Detection in UAV Images
Apr 24, 2023



Occlusion between objects is one of the overlooked challenges for object detection in UAV images. Due to the variable altitude and angle of UAVs, occlusion in UAV images happens more frequently than that in natural scenes. Compared to occlusion in natural scene images, occlusion in UAV images happens with feature confusion problem and local aggregation characteristic. And we found that extracting or localizing occlusion between objects is beneficial for the detector to address this challenge. According to this finding, the occlusion localization task is introduced, which together with the object detection task constitutes our occlusion-guided multi-task network (OGMN). The OGMN contains the localization of occlusion and two occlusion-guided multi-task interactions. In detail, an occlusion estimation module (OEM) is proposed to precisely localize occlusion. Then the OGMN utilizes the occlusion localization results to implement occlusion-guided detection with two multi-task interactions. One interaction for the guide is between two task decoders to address the feature confusion problem, and an occlusion decoupling head (ODH) is proposed to replace the general detection head. Another interaction for guide is designed in the detection process according to local aggregation characteristic, and a two-phase progressive refinement process (TPP) is proposed to optimize the detection process. Extensive experiments demonstrate the effectiveness of our OGMN on the Visdrone and UAVDT datasets. In particular, our OGMN achieves 35.0% mAP on the Visdrone dataset and outperforms the baseline by 5.3%. And our OGMN provides a new insight for accurate occlusion localization and achieves competitive detection performance.