 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight Any Instance: Promptable Instance Segmentation for Remote Sensing Images
Sep 11, 2024Instance segmentation of remote sensing images (RSIs) is an essential task for a wide range of applications such as land planning and intelligent transport. Instance segmentation of RSIs is constantly plagued by the unbalanced ratio of foreground and background and limited instance size. And most of the instance segmentation models are based on deep feature learning and contain operations such as multiple downsampling, which is harmful to instance segmentation of RSIs, and thus the performance is still limited. Inspired by the recent superior performance of prompt learning in visual tasks, we propose a new prompt paradigm to address the above issues. Based on the existing instance segmentation model, firstly, a local prompt module is designed to mine local prompt information from original local tokens for specific instances; secondly, a global-to-local prompt module is designed to model the contextual information from the global tokens to the local tokens where the instances are located for specific instances. Finally, a proposal's area loss function is designed to add a decoupling dimension for proposals on the scale to better exploit the potential of the above two prompt modules. It is worth mentioning that our proposed approach can extend the instance segmentation model to a promptable instance segmentation model, i.e., to segment the instances with the specific boxes prompt. The time consumption for each promptable instance segmentation process is only 40 ms. The paper evaluates the effectiveness of our proposed approach based on several existing models in four instance segmentation datasets of RSIs, and thorough experiments prove that our proposed approach is effective for addressing the above issues and is a competitive model for instance segmentation of RSIs.
SCLNet: A Scale-Robust Complementary Learning Network for Object Detection in UAV Images
Sep 11, 2024



Most recent UAV (Unmanned Aerial Vehicle) detectors focus primarily on general challenge such as uneven distribution and occlusion. However, the neglect of scale challenges, which encompass scale variation and small objects, continues to hinder object detection in UAV images. Although existing works propose solutions, they are implicitly modeled and have redundant steps, so detection performance remains limited. And one specific work addressing the above scale challenges can help improve the performance of UAV image detectors. Compared to natural scenes, scale challenges in UAV images happen with problems of limited perception in comprehensive scales and poor robustness to small objects. We found that complementary learning is beneficial for the detection model to address the scale challenges. Therefore, the paper introduces it to form our scale-robust complementary learning network (SCLNet) in conjunction with the object detection model. The SCLNet consists of two implementations and a cooperation method. In detail, one implementation is based on our proposed scale-complementary decoder and scale-complementary loss function to explicitly extract complementary information as complement, named comprehensive-scale complementary learning (CSCL). Another implementation is based on our proposed contrastive complement network and contrastive complement loss function to explicitly guide the learning of small objects with the rich texture detail information of the large objects, named inter-scale contrastive complementary learning (ICCL). In addition, an end-to-end cooperation (ECoop) between two implementations and with the detection model is proposed to exploit each potential.
Twin Deformable Point Convolutions for Point Cloud Semantic Segmentation in Remote Sensing Scenes
May 30, 2024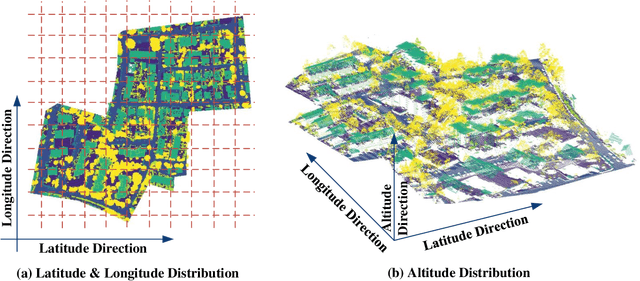
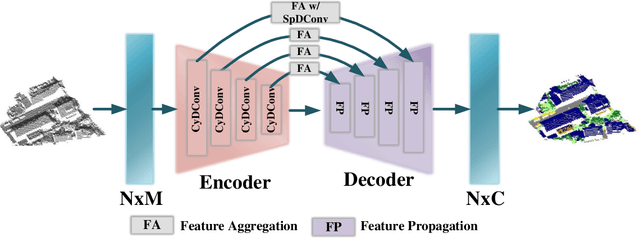
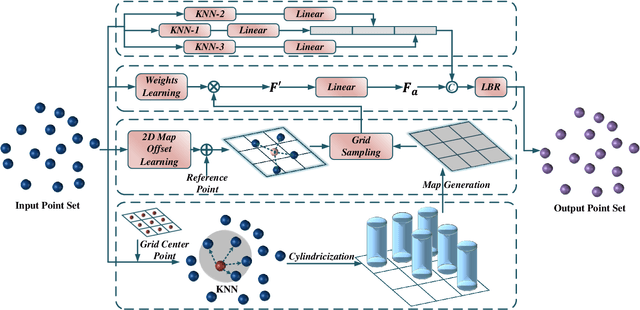
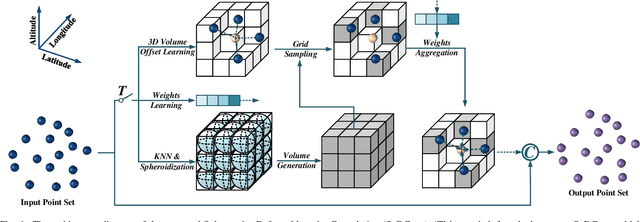
Thanks to the application of deep learning technology in point cloud processing of the remote sensing field, point cloud segmentation has become a research hotspot in recent years, which can be applied to real-world 3D, smart cities, and other fields. Although existing solutions have made unprecedented progress, they ignore the inherent characteristics of point clouds in remote sensing fields that are strictly arranged according to latitude, longitude, and altitude, which brings great convenience to the segmentation of point clouds in remote sensing fields. To consider this property cleverly, we propose novel convolution operators, termed Twin Deformable point Convolutions (TDConvs), which aim to achieve adaptive feature learning by learning deformable sampling points in the latitude-longitude plane and altitude direction, respectively. First, to model the characteristics of the latitude-longitude plane, we propose a Cylinder-wise Deformable point Convolution (CyDConv) operator, which generates a two-dimensional cylinder map by constructing a cylinder-like grid in the latitude-longitude direction. Furthermore, to better integrate the features of the latitude-longitude plane and the spatial geometric features, we perform a multi-scale fusion of the extracted latitude-longitude features and spatial geometric features, and realize it through the aggregation of adjacent point features of different scales. In addition, a Sphere-wise Deformable point Convolution (SpDConv) operator is introduced to adaptively offset the sampling points in three-dimensional space by constructing a sphere grid structure, aiming at modeling the characteristics in the altitude direction. Experiments on existing popular benchmarks conclude that our TDConvs achieve the best segmentation performance, surpassing the existing state-of-the-art methods.
OGMN: Occlusion-guided Multi-task Network for Object Detection in UAV Images
Apr 24, 2023



Occlusion between objects is one of the overlooked challenges for object detection in UAV images. Due to the variable altitude and angle of UAVs, occlusion in UAV images happens more frequently than that in natural scenes. Compared to occlusion in natural scene images, occlusion in UAV images happens with feature confusion problem and local aggregation characteristic. And we found that extracting or localizing occlusion between objects is beneficial for the detector to address this challenge. According to this finding, the occlusion localization task is introduced, which together with the object detection task constitutes our occlusion-guided multi-task network (OGMN). The OGMN contains the localization of occlusion and two occlusion-guided multi-task interactions. In detail, an occlusion estimation module (OEM) is proposed to precisely localize occlusion. Then the OGMN utilizes the occlusion localization results to implement occlusion-guided detection with two multi-task interactions. One interaction for the guide is between two task decoders to address the feature confusion problem, and an occlusion decoupling head (ODH) is proposed to replace the general detection head. Another interaction for guide is designed in the detection process according to local aggregation characteristic, and a two-phase progressive refinement process (TPP) is proposed to optimize the detection process. Extensive experiments demonstrate the effectiveness of our OGMN on the Visdrone and UAVDT datasets. In particular, our OGMN achieves 35.0% mAP on the Visdrone dataset and outperforms the baseline by 5.3%. And our OGMN provides a new insight for accurate occlusion localization and achieves competitive detection performance.