 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwin Deformable Point Convolutions for Point Cloud Semantic Segmentation in Remote Sensing Scenes
May 30, 2024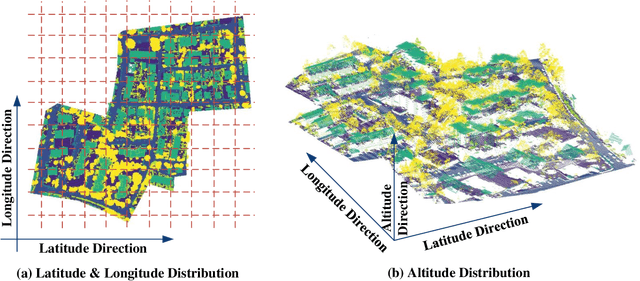
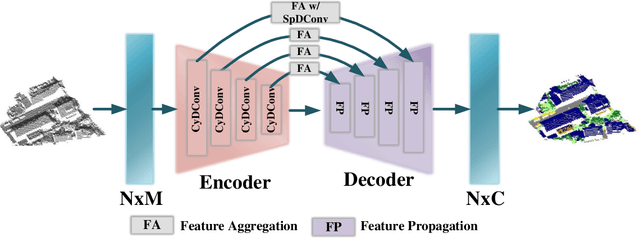
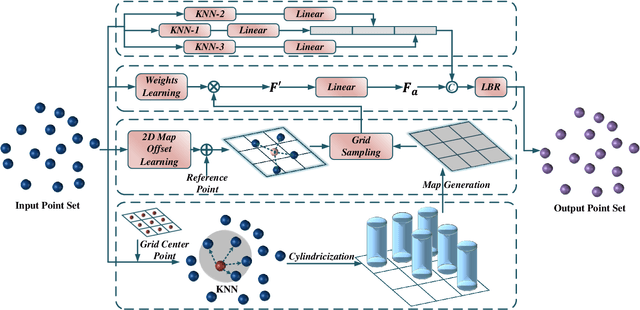
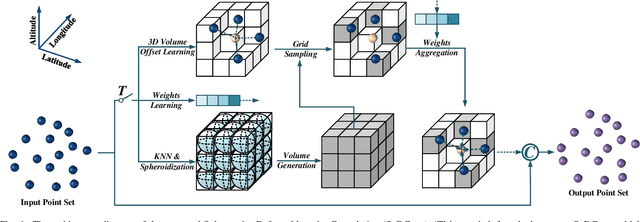
Thanks to the application of deep learning technology in point cloud processing of the remote sensing field, point cloud segmentation has become a research hotspot in recent years, which can be applied to real-world 3D, smart cities, and other fields. Although existing solutions have made unprecedented progress, they ignore the inherent characteristics of point clouds in remote sensing fields that are strictly arranged according to latitude, longitude, and altitude, which brings great convenience to the segmentation of point clouds in remote sensing fields. To consider this property cleverly, we propose novel convolution operators, termed Twin Deformable point Convolutions (TDConvs), which aim to achieve adaptive feature learning by learning deformable sampling points in the latitude-longitude plane and altitude direction, respectively. First, to model the characteristics of the latitude-longitude plane, we propose a Cylinder-wise Deformable point Convolution (CyDConv) operator, which generates a two-dimensional cylinder map by constructing a cylinder-like grid in the latitude-longitude direction. Furthermore, to better integrate the features of the latitude-longitude plane and the spatial geometric features, we perform a multi-scale fusion of the extracted latitude-longitude features and spatial geometric features, and realize it through the aggregation of adjacent point features of different scales. In addition, a Sphere-wise Deformable point Convolution (SpDConv) operator is introduced to adaptively offset the sampling points in three-dimensional space by constructing a sphere grid structure, aiming at modeling the characteristics in the altitude direction. Experiments on existing popular benchmarks conclude that our TDConvs achieve the best segmentation performance, surpassing the existing state-of-the-art methods.
SDL-MVS: View Space and Depth Deformable Learning Paradigm for Multi-View Stereo Reconstruction in Remote Sensing
May 27, 2024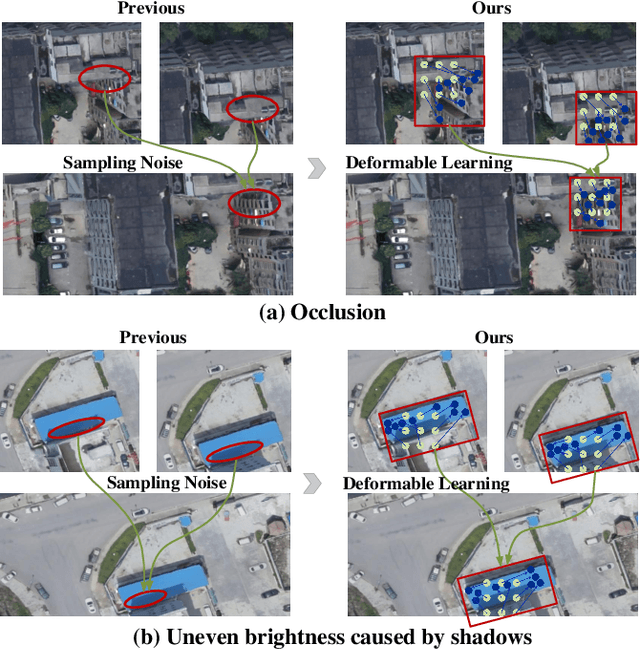
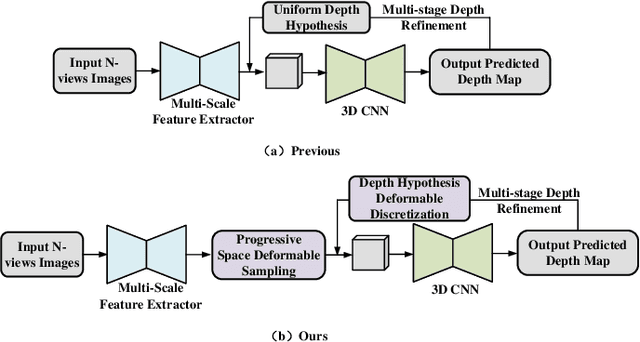
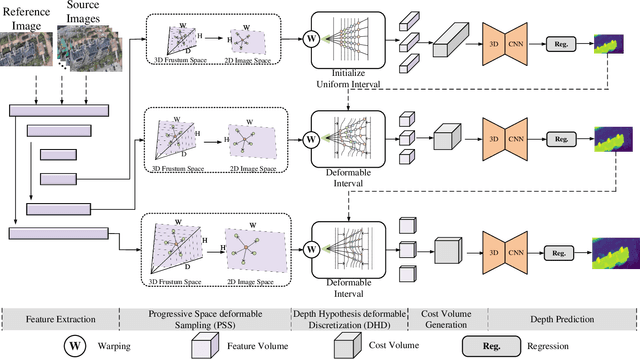
Research on multi-view stereo based on remote sensing images has promoted the development of large-scale urban 3D reconstruction. However, remote sensing multi-view image data suffers from the problems of occlusion and uneven brightness between views during acquisition, which leads to the problem of blurred details in depth estimation. To solve the above problem, we re-examine the deformable learning method in the Multi-View Stereo task and propose a novel paradigm based on view Space and Depth deformable Learning (SDL-MVS), aiming to learn deformable interactions of features in different view spaces and deformably model the depth ranges and intervals to enable high accurate depth estimation. Specifically, to solve the problem of view noise caused by occlusion and uneven brightness, we propose a Progressive Space deformable Sampling (PSS) mechanism, which performs deformable learning of sampling points in the 3D frustum space and the 2D image space in a progressive manner to embed source features to the reference feature adaptively. To further optimize the depth, we introduce Depth Hypothesis deformable Discretization (DHD), which achieves precise positioning of the depth prior by adaptively adjusting the depth range hypothesis and performing deformable discretization of the depth interval hypothesis. Finally, our SDL-MVS achieves explicit modeling of occlusion and uneven brightness faced in multi-view stereo through the deformable learning paradigm of view space and depth, achieving accurate multi-view depth estimation. Extensive experiments on LuoJia-MVS and WHU datasets show that our SDL-MVS reaches state-of-the-art performance. It is worth noting that our SDL-MVS achieves an MAE error of 0.086, an accuracy of 98.9% for <0.6m, and 98.9% for <3-interval on the LuoJia-MVS dataset under the premise of three views as input.