 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Victories, Less Cooperation: Assessing Cicero's Diplomacy Play
Jun 07, 2024The boardgame Diplomacy is a challenging setting for communicative and cooperative artificial intelligence. The most prominent communicative Diplomacy AI, Cicero, has excellent strategic abilities, exceeding human players. However, the best Diplomacy players master communication, not just tactics, which is why the game has received attention as an AI challenge. This work seeks to understand the degree to which Cicero succeeds at communication. First, we annotate in-game communication with abstract meaning representation to separate in-game tactics from general language. Second, we run two dozen games with humans and Cicero, totaling over 200 human-player hours of competition. While AI can consistently outplay human players, AI-Human communication is still limited because of AI's difficulty with deception and persuasion. This shows that Cicero relies on strategy and has not yet reached the full promise of communicative and cooperative AI.
The eBible Corpus: Data and Model Benchmarks for Bible Translation for Low-Resource Languages
Apr 19, 2023
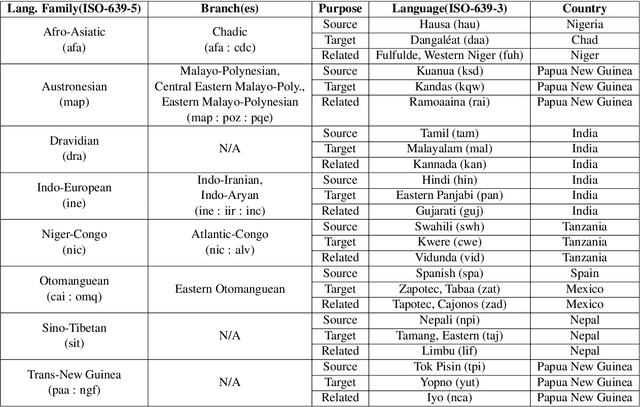
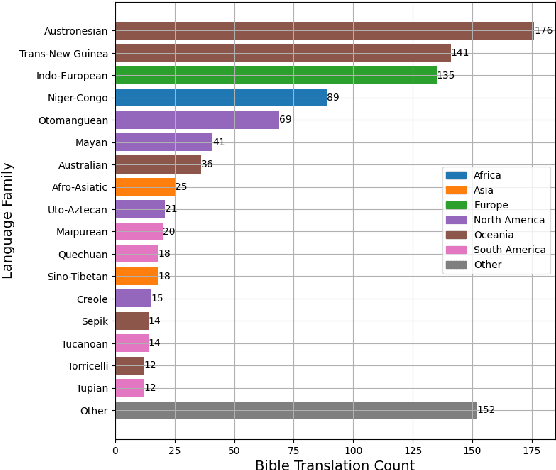
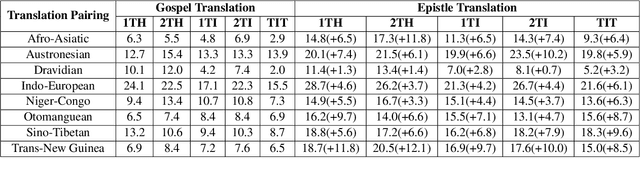
Efficiently and accurately translating a corpus into a low-resource language remains a challenge, regardless of the strategies employed, whether manual, automated, or a combination of the two. Many Christian organizations are dedicated to the task of translating the Holy Bible into languages that lack a modern translation. Bible translation (BT) work is currently underway for over 3000 extremely low resource languages. We introduce the eBible corpus: a dataset containing 1009 translations of portions of the Bible with data in 833 different languages across 75 language families. In addition to a BT benchmarking dataset, we introduce model performance benchmarks built on the No Language Left Behind (NLLB) neural machine translation (NMT) models. Finally, we describe several problems specific to the domain of BT and consider how the established data and model benchmarks might be used for future translation efforts. For a BT task trained with NLLB, Austronesian and Trans-New Guinea language families achieve 35.1 and 31.6 BLEU scores respectively, which spurs future innovations for NMT for low-resource languages in Papua New Guinea.
User Study for Improving Tools for Bible Translation
Feb 01, 2023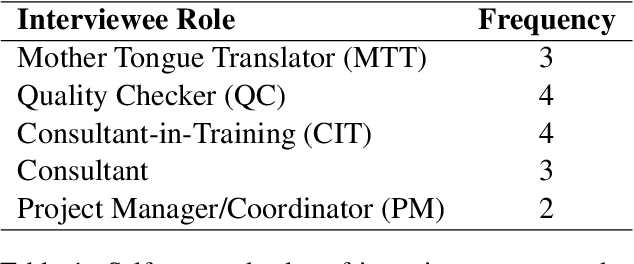
Technology has increasingly become an integral part of the Bible translation process. Over time, both the translation process and relevant technology have evolved greatly. More recently, the field of Natural Language Processing (NLP) has made great progress in solving some problems previously thought impenetrable. Through this study we endeavor to better understand and communicate about a segment of the current landscape of the Bible translation process as it relates to technology and identify pertinent issues. We conduct several interviews with individuals working in different levels of the Bible translation process from multiple organizations to identify gaps and bottlenecks where technology (including recent advances in AI) could potentially play a pivotal role in reducing translation time and improving overall quality.
Extracting Biomolecular Interactions Using Semantic Parsing of Biomedical Text
Dec 04, 2015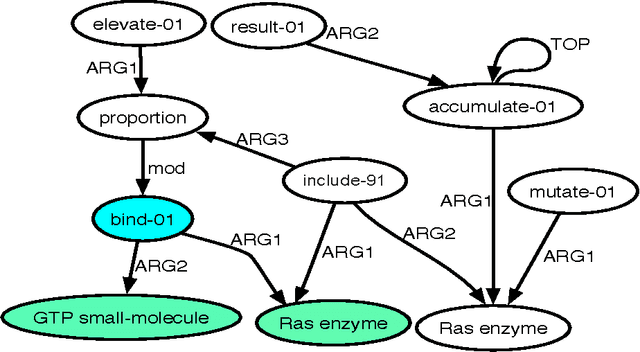
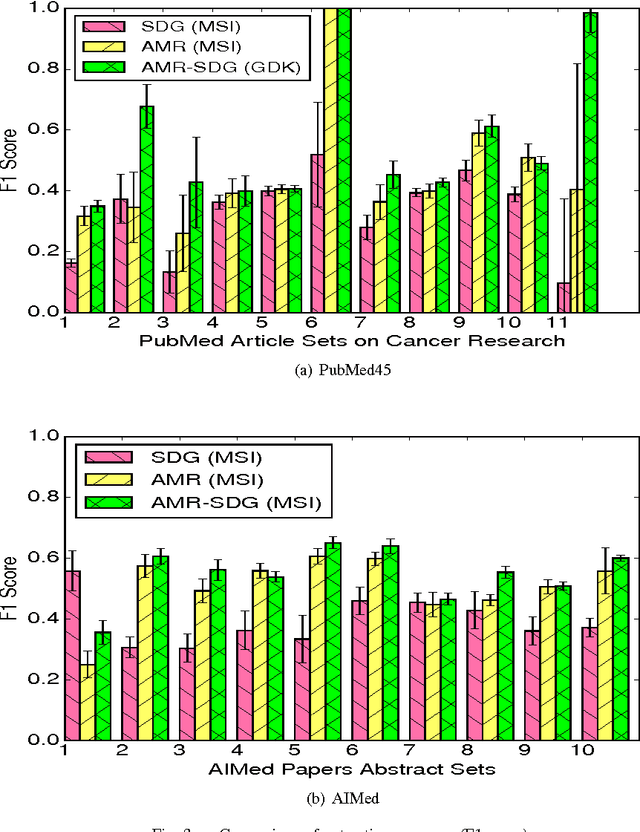
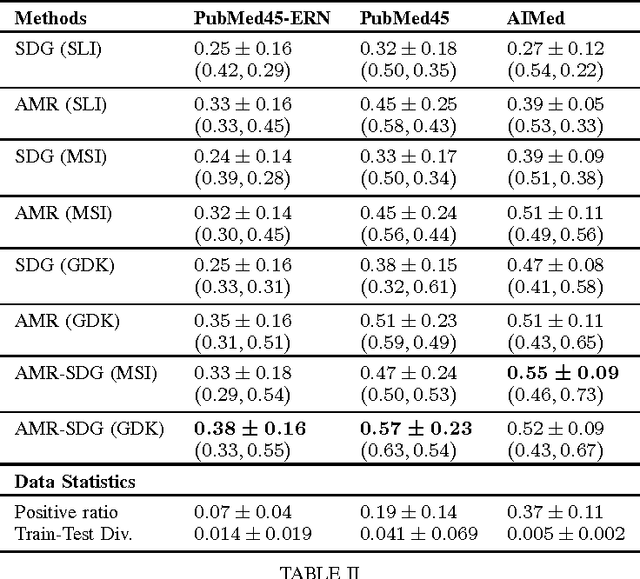
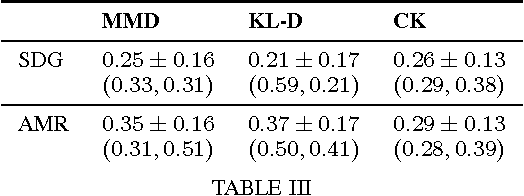
We advance the state of the art in biomolecular interaction extraction with three contributions: (i) We show that deep, Abstract Meaning Representations (AMR) significantly improve the accuracy of a biomolecular interaction extraction system when compared to a baseline that relies solely on surface- and syntax-based features; (ii) In contrast with previous approaches that infer relations on a sentence-by-sentence basis, we expand our framework to enable consistent predictions over sets of sentences (documents); (iii) We further modify and expand a graph kernel learning framework to enable concurrent exploitation of automatically induced AMR (semantic) and dependency structure (syntactic) representations. Our experiments show that our approach yields interaction extraction systems that are more robust in environments where there is a significant mismatch between training and test conditions.
Using Syntax-Based Machine Translation to Parse English into Abstract Meaning Representation
Apr 28, 2015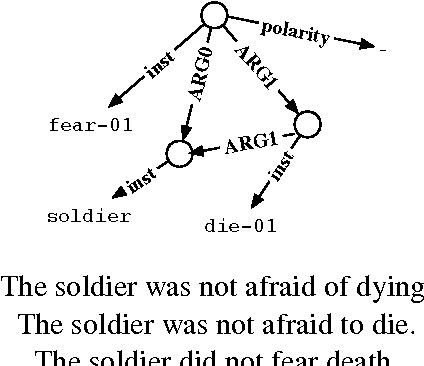



We present a parser for Abstract Meaning Representation (AMR). We treat English-to-AMR conversion within the framework of string-to-tree, syntax-based machine translation (SBMT). To make this work, we transform the AMR structure into a form suitable for the mechanics of SBMT and useful for modeling. We introduce an AMR-specific language model and add data and features drawn from semantic resources. Our resulting AMR parser improves upon state-of-the-art results by 7 Smatch points.
Learning Parse and Translation Decisions From Examples With Rich Context
Jun 30, 1997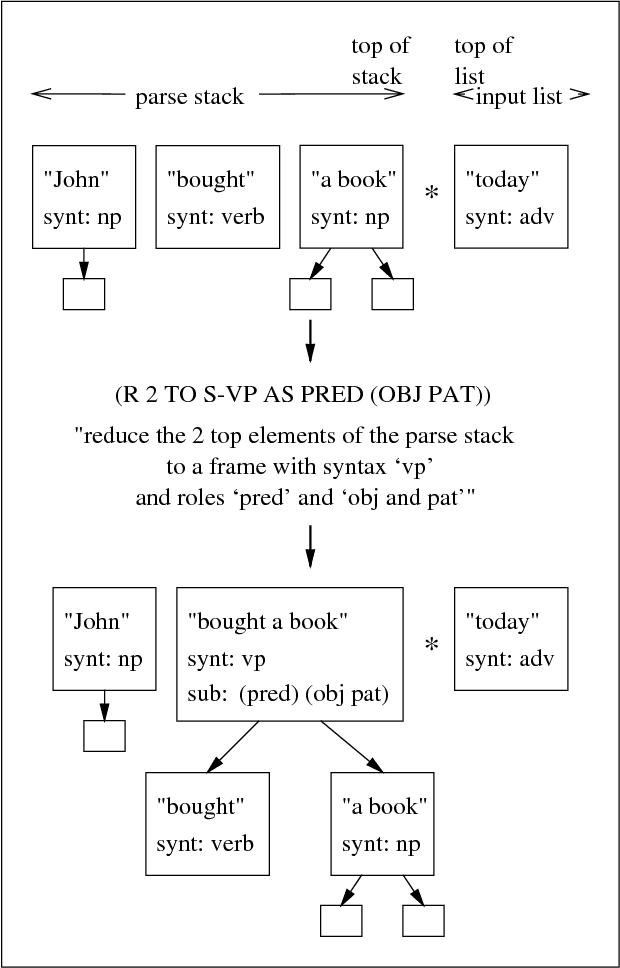
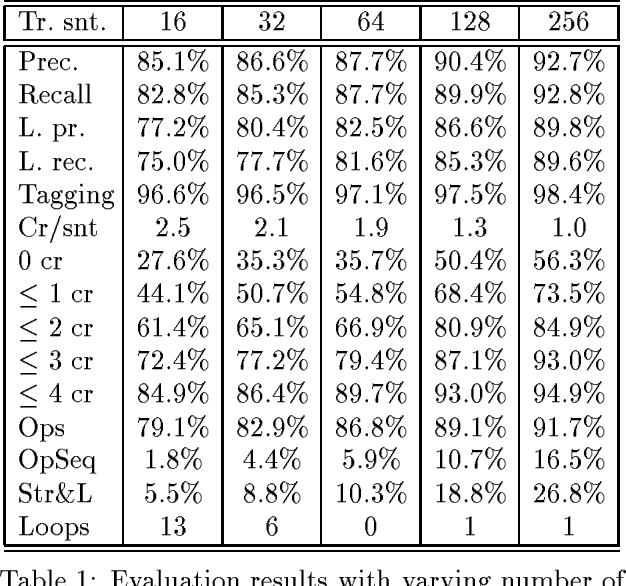

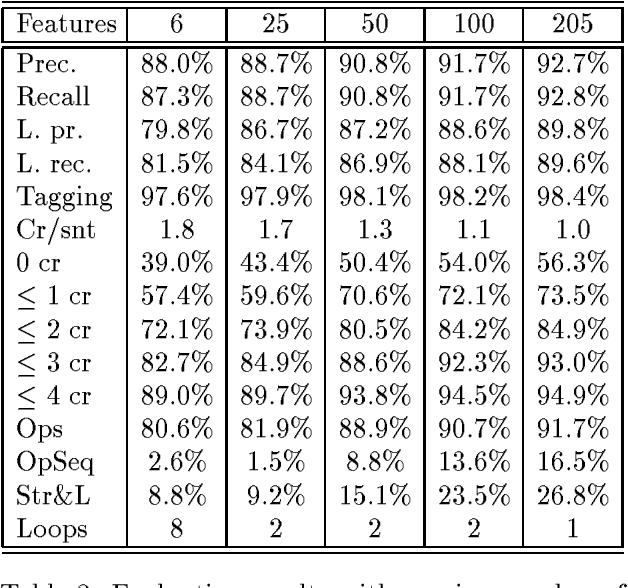
We propose a system for parsing and translating natural language that learns from examples and uses some background knowledge. As our parsing model we choose a deterministic shift-reduce type parser that integrates part-of-speech tagging and syntactic and semantic processing. Applying machine learning techniques, the system uses parse action examples acquired under supervision to generate a parser in the form of a decision structure, a generalization of decision trees. To learn good parsing and translation decisions, our system relies heavily on context, as encoded in currently 205 features describing the morphological, syntactical and semantical aspects of a given parse state. Compared with recent probabilistic systems that were trained on 40,000 sentences, our system relies on more background knowledge and a deeper analysis, but radically fewer examples, currently 256 sentences. We test our parser on lexically limited sentences from the Wall Street Journal and achieve accuracy rates of 89.8% for labeled precision, 98.4% for part of speech tagging and 56.3% of test sentences without any crossing brackets. Machine translations of 32 Wall Street Journal sentences to German have been evaluated by 10 bilingual volunteers and been graded as 2.4 on a 1.0 (best) to 6.0 (worst) scale for both grammatical correctness and meaning preservation.