 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Biomolecular Interactions Using Semantic Parsing of Biomedical Text
Paper and Code
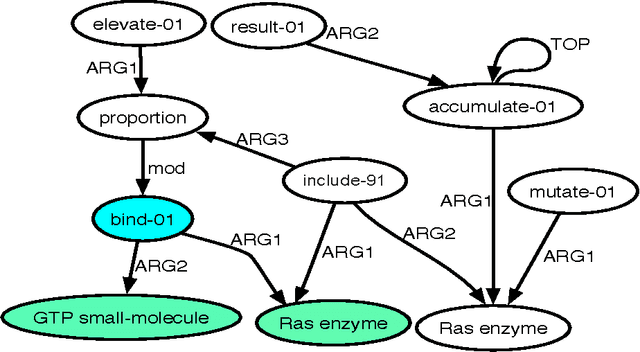
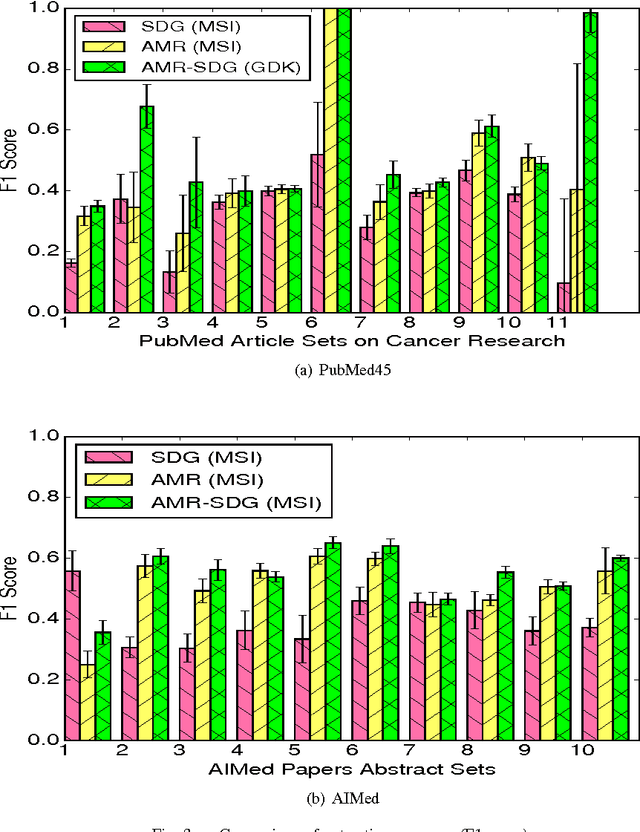
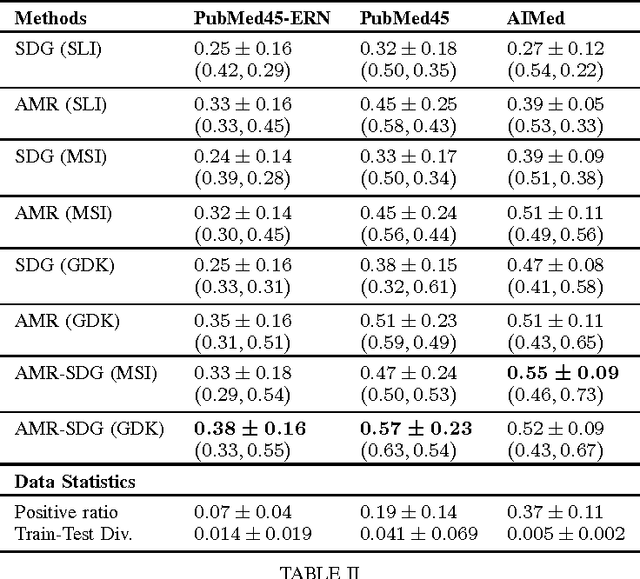
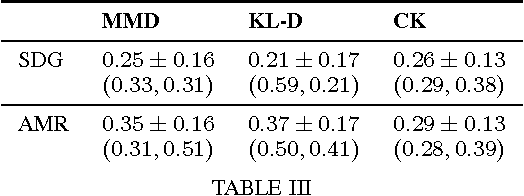
We advance the state of the art in biomolecular interaction extraction with three contributions: (i) We show that deep, Abstract Meaning Representations (AMR) significantly improve the accuracy of a biomolecular interaction extraction system when compared to a baseline that relies solely on surface- and syntax-based features; (ii) In contrast with previous approaches that infer relations on a sentence-by-sentence basis, we expand our framework to enable consistent predictions over sets of sentences (documents); (iii) We further modify and expand a graph kernel learning framework to enable concurrent exploitation of automatically induced AMR (semantic) and dependency structure (syntactic) representations. Our experiments show that our approach yields interaction extraction systems that are more robust in environments where there is a significant mismatch between training and test conditions.