 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe eBible Corpus: Data and Model Benchmarks for Bible Translation for Low-Resource Languages
Apr 19, 2023
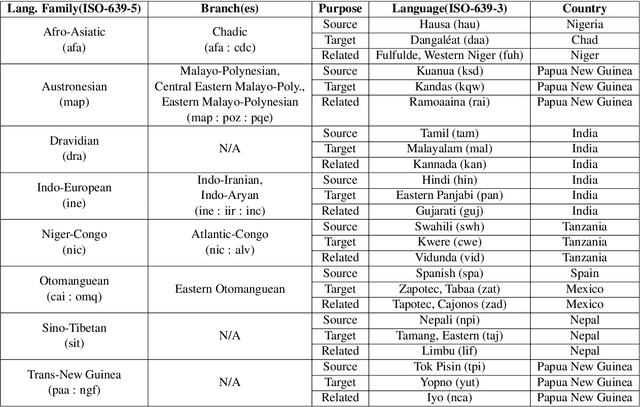
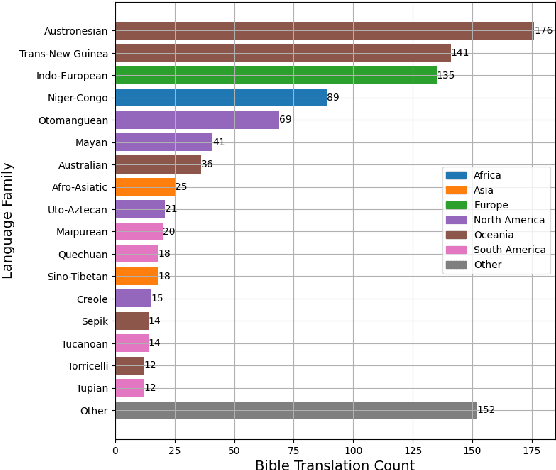
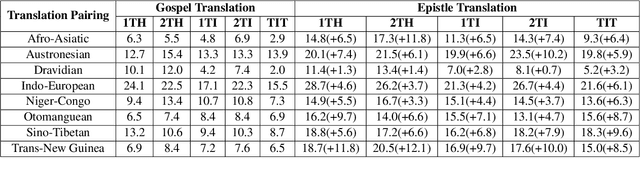
Efficiently and accurately translating a corpus into a low-resource language remains a challenge, regardless of the strategies employed, whether manual, automated, or a combination of the two. Many Christian organizations are dedicated to the task of translating the Holy Bible into languages that lack a modern translation. Bible translation (BT) work is currently underway for over 3000 extremely low resource languages. We introduce the eBible corpus: a dataset containing 1009 translations of portions of the Bible with data in 833 different languages across 75 language families. In addition to a BT benchmarking dataset, we introduce model performance benchmarks built on the No Language Left Behind (NLLB) neural machine translation (NMT) models. Finally, we describe several problems specific to the domain of BT and consider how the established data and model benchmarks might be used for future translation efforts. For a BT task trained with NLLB, Austronesian and Trans-New Guinea language families achieve 35.1 and 31.6 BLEU scores respectively, which spurs future innovations for NMT for low-resource languages in Papua New Guinea.
Adapting to the Low-Resource Double-Bind: Investigating Low-Compute Methods on Low-Resource African Languages
Mar 29, 2023

Many natural language processing (NLP) tasks make use of massively pre-trained language models, which are computationally expensive. However, access to high computational resources added to the issue of data scarcity of African languages constitutes a real barrier to research experiments on these languages. In this work, we explore the applicability of low-compute approaches such as language adapters in the context of this low-resource double-bind. We intend to answer the following question: do language adapters allow those who are doubly bound by data and compute to practically build useful models? Through fine-tuning experiments on African languages, we evaluate their effectiveness as cost-effective approaches to low-resource African NLP. Using solely free compute resources, our results show that language adapters achieve comparable performances to massive pre-trained language models which are heavy on computational resources. This opens the door to further experimentation and exploration on full-extent of language adapters capacities.
User Study for Improving Tools for Bible Translation
Feb 01, 2023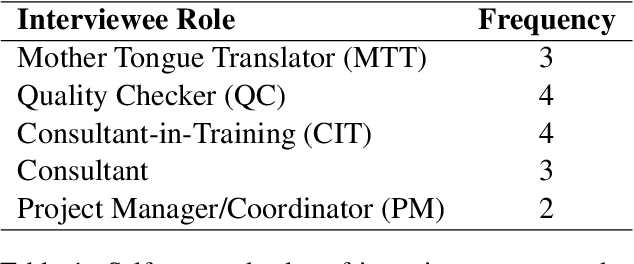
Technology has increasingly become an integral part of the Bible translation process. Over time, both the translation process and relevant technology have evolved greatly. More recently, the field of Natural Language Processing (NLP) has made great progress in solving some problems previously thought impenetrable. Through this study we endeavor to better understand and communicate about a segment of the current landscape of the Bible translation process as it relates to technology and identify pertinent issues. We conduct several interviews with individuals working in different levels of the Bible translation process from multiple organizations to identify gaps and bottlenecks where technology (including recent advances in AI) could potentially play a pivotal role in reducing translation time and improving overall quality.
Snow Mountain: Dataset of Audio Recordings of The Bible in Low Resource Languages
Jun 01, 2022
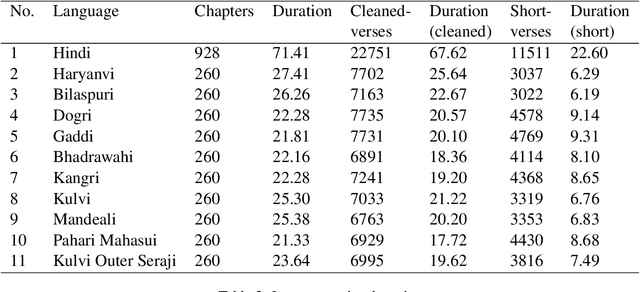
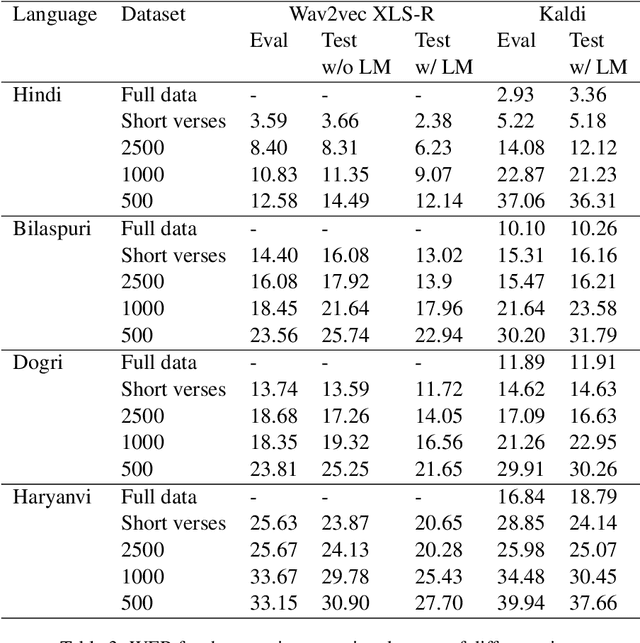

Automatic Speech Recognition (ASR) has increasing utility in the modern world. There are a many ASR models available for languages with large amounts of training data like English. However, low-resource languages are poorly represented. In response we create and release an open-licensed and formatted dataset of audio recordings of the Bible in low-resource northern Indian languages. We setup multiple experimental splits and train and analyze two competitive ASR models to serve as the baseline for future research using this data.
Federated Named Entity Recognition
Mar 28, 2022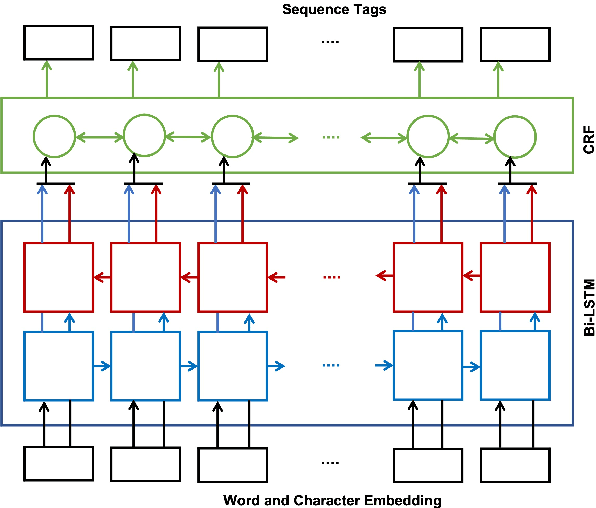

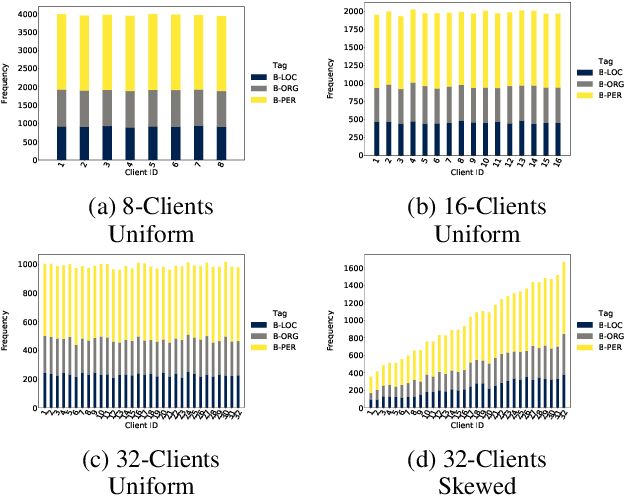
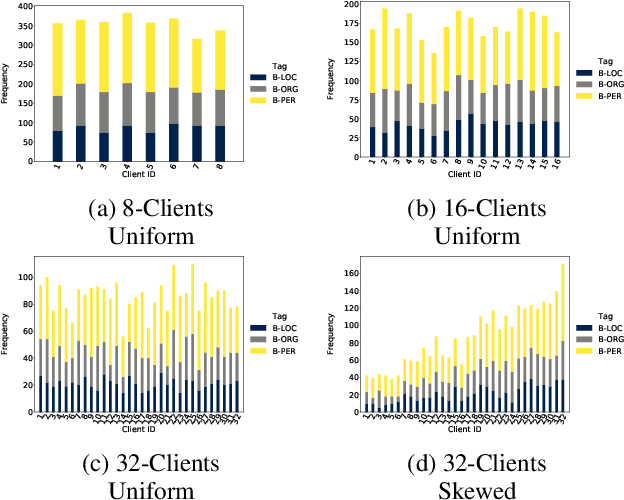
We present an analysis of the performance of Federated Learning in a paradigmatic natural-language processing task: Named-Entity Recognition (NER). For our evaluation, we use the language-independent CoNLL-2003 dataset as our benchmark dataset and a Bi-LSTM-CRF model as our benchmark NER model. We show that federated training reaches almost the same performance as the centralized model, though with some performance degradation as the learning environments become more heterogeneous. We also show the convergence rate of federated models for NER. Finally, we discuss existing challenges of Federated Learning for NLP applications that can foster future research directions.
Biomedical Named Entity Recognition via Reference-Set Augmented Bootstrapping
Jun 01, 2019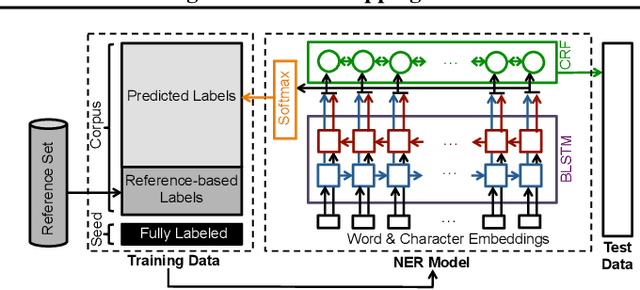
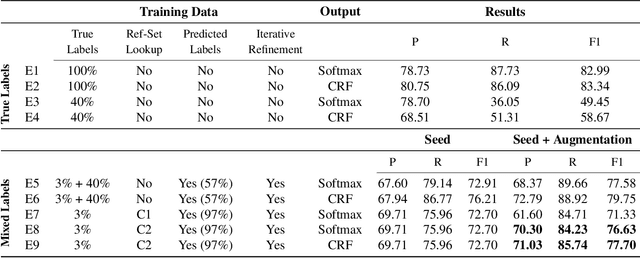
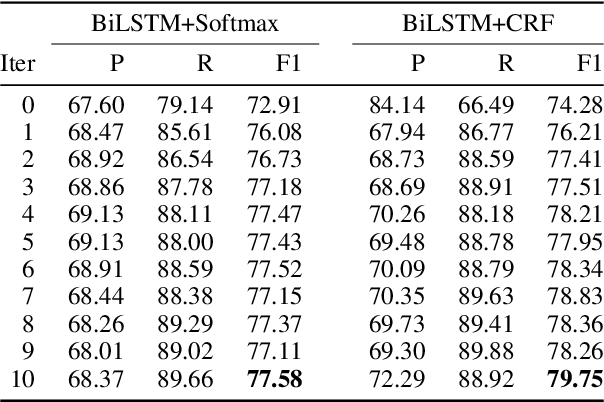
We present a weakly-supervised data augmentation approach to improve Named Entity Recognition (NER) in a challenging domain: extracting biomedical entities (e.g., proteins) from the scientific literature. First, we train a neural NER (NNER) model over a small seed of fully-labeled examples. Second, we use a reference set of entity names (e.g., proteins in UniProt) to identify entity mentions with high precision, but low recall, on an unlabeled corpus. Third, we use the NNER model to assign weak labels to the corpus. Finally, we retrain our NNER model iteratively over the augmented training set, including the seed, the reference-set examples, and the weakly-labeled examples, which improves model performance. We show empirically that this augmented bootstrapping process significantly improves NER performance, and discuss the factors impacting the efficacy of the approach.