 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKathakali Hand Gesture Recognition With Minimal Data
Apr 17, 2024The Indian classical dance-drama Kathakali has a set of hand gestures called Mudras, which form the fundamental units of all its dance moves and postures. Recognizing the depicted mudra becomes one of the first steps in its digital processing. The work treats the problem as a 24-class classification task and proposes a vector-similarity-based approach using pose estimation, eliminating the need for further training or fine-tuning. This approach overcomes the challenge of data scarcity that limits the application of AI in similar domains. The method attains 92% accuracy which is a similar or better performance as other model-training-based works existing in the domain, with the added advantage that the method can still work with data sizes as small as 1 or 5 samples with a slightly reduced performance. Working with images, videos, and even real-time streams is possible. The system can work with hand-cropped or full-body images alike. We have developed and made public a dataset for the Kathakali Mudra Recognition as part of this work.
Snow Mountain: Dataset of Audio Recordings of The Bible in Low Resource Languages
Jun 01, 2022
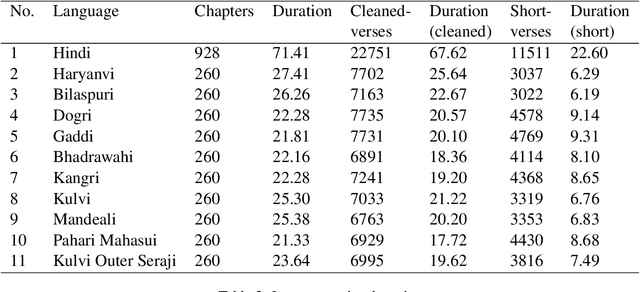
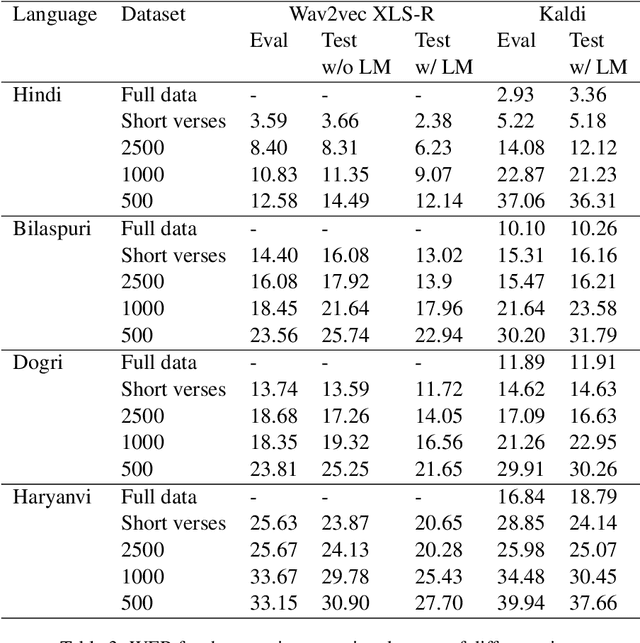

Automatic Speech Recognition (ASR) has increasing utility in the modern world. There are a many ASR models available for languages with large amounts of training data like English. However, low-resource languages are poorly represented. In response we create and release an open-licensed and formatted dataset of audio recordings of the Bible in low-resource northern Indian languages. We setup multiple experimental splits and train and analyze two competitive ASR models to serve as the baseline for future research using this data.