 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sparsified Federated Neuroimaging Models via Weight Pruning
Aug 24, 2022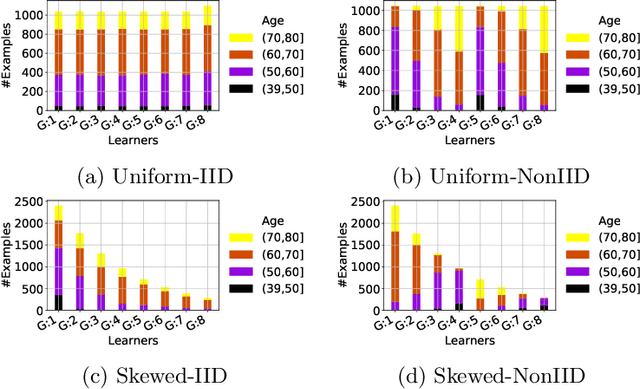
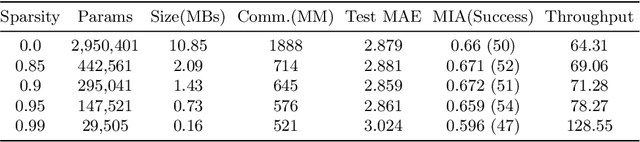
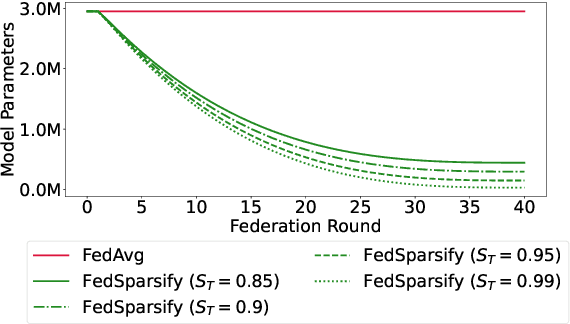
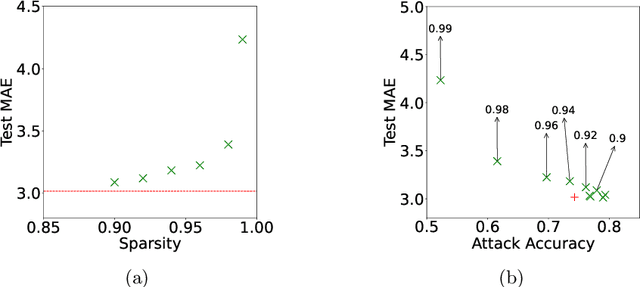
Federated training of large deep neural networks can often be restrictive due to the increasing costs of communicating the updates with increasing model sizes. Various model pruning techniques have been designed in centralized settings to reduce inference times. Combining centralized pruning techniques with federated training seems intuitive for reducing communication costs -- by pruning the model parameters right before the communication step. Moreover, such a progressive model pruning approach during training can also reduce training times/costs. To this end, we propose FedSparsify, which performs model pruning during federated training. In our experiments in centralized and federated settings on the brain age prediction task (estimating a person's age from their brain MRI), we demonstrate that models can be pruned up to 95% sparsity without affecting performance even in challenging federated learning environments with highly heterogeneous data distributions. One surprising benefit of model pruning is improved model privacy. We demonstrate that models with high sparsity are less susceptible to membership inference attacks, a type of privacy attack.
Federated Named Entity Recognition
Mar 28, 2022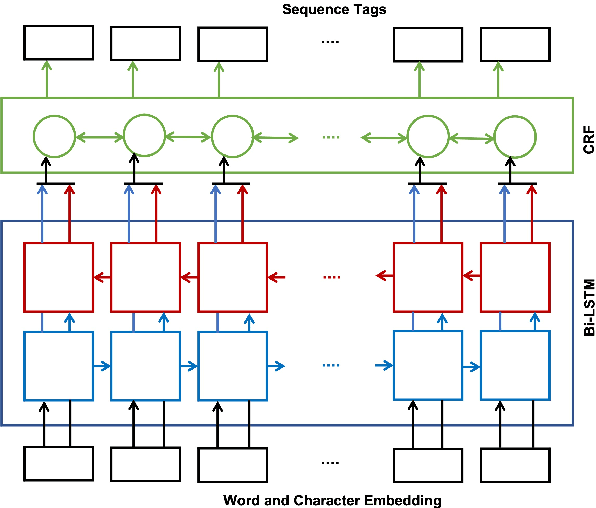

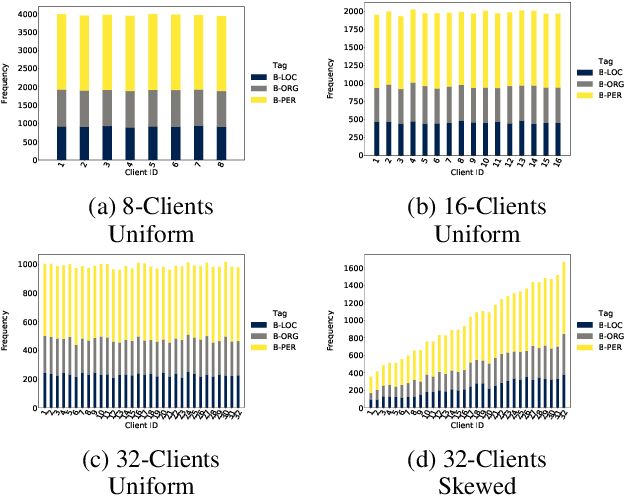
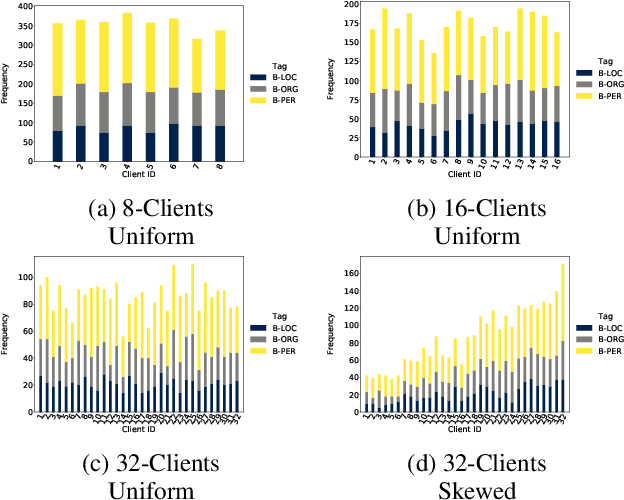
We present an analysis of the performance of Federated Learning in a paradigmatic natural-language processing task: Named-Entity Recognition (NER). For our evaluation, we use the language-independent CoNLL-2003 dataset as our benchmark dataset and a Bi-LSTM-CRF model as our benchmark NER model. We show that federated training reaches almost the same performance as the centralized model, though with some performance degradation as the learning environments become more heterogeneous. We also show the convergence rate of federated models for NER. Finally, we discuss existing challenges of Federated Learning for NLP applications that can foster future research directions.
Building Autocorrelation-Aware Representations for Fine-Scale Spatiotemporal Prediction
Dec 10, 2021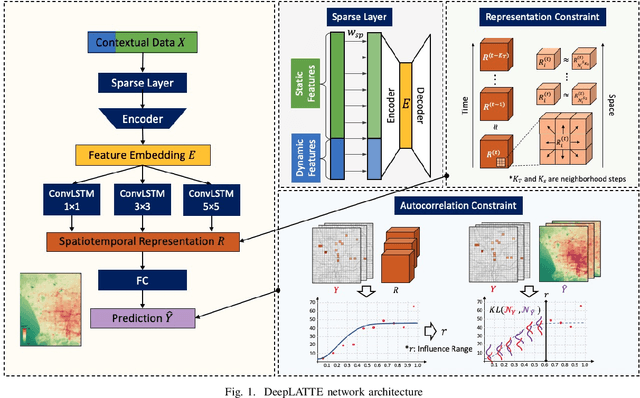
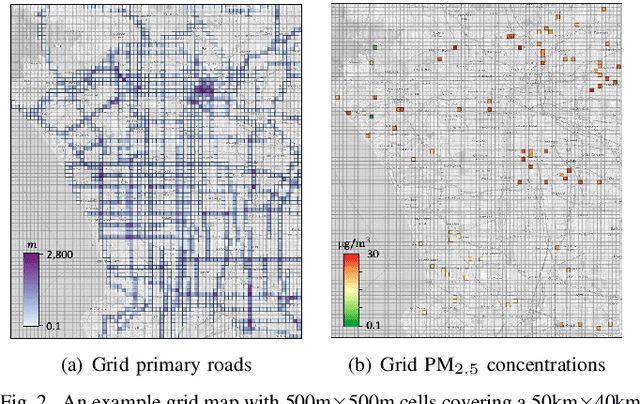
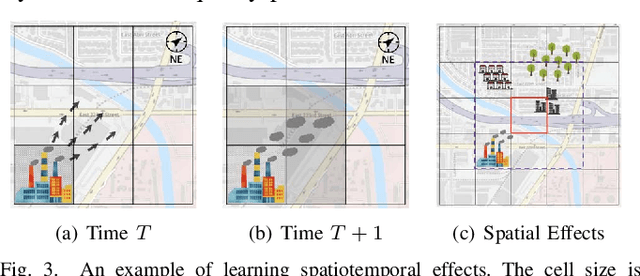
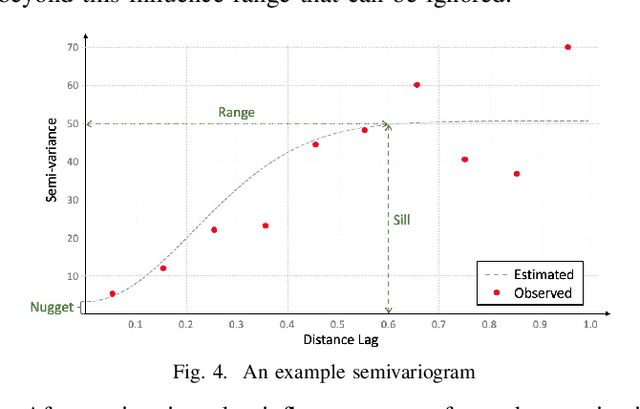
Many scientific prediction problems have spatiotemporal data- and modeling-related challenges in handling complex variations in space and time using only sparse and unevenly distributed observations. This paper presents a novel deep learning architecture, Deep learning predictions for LocATion-dependent Time-sEries data (DeepLATTE), that explicitly incorporates theories of spatial statistics into neural networks to address these challenges. In addition to a feature selection module and a spatiotemporal learning module, DeepLATTE contains an autocorrelation-guided semi-supervised learning strategy to enforce both local autocorrelation patterns and global autocorrelation trends of the predictions in the learned spatiotemporal embedding space to be consistent with the observed data, overcoming the limitation of sparse and unevenly distributed observations. During the training process, both supervised and semi-supervised losses guide the updates of the entire network to: 1) prevent overfitting, 2) refine feature selection, 3) learn useful spatiotemporal representations, and 4) improve overall prediction. We conduct a demonstration of DeepLATTE using publicly available data for an important public health topic, air quality prediction, in a well-studied, complex physical environment - Los Angeles. The experiment demonstrates that the proposed approach provides accurate fine-spatial-scale air quality predictions and reveals the critical environmental factors affecting the results.
Membership Inference Attacks on Deep Regression Models for Neuroimaging
Jun 03, 2021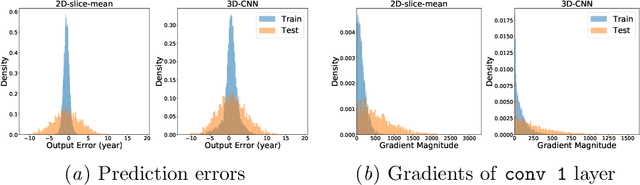


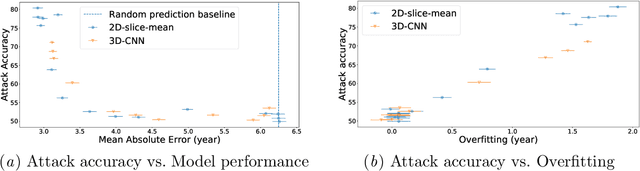
Ensuring the privacy of research participants is vital, even more so in healthcare environments. Deep learning approaches to neuroimaging require large datasets, and this often necessitates sharing data between multiple sites, which is antithetical to the privacy objectives. Federated learning is a commonly proposed solution to this problem. It circumvents the need for data sharing by sharing parameters during the training process. However, we demonstrate that allowing access to parameters may leak private information even if data is never directly shared. In particular, we show that it is possible to infer if a sample was used to train the model given only access to the model prediction (black-box) or access to the model itself (white-box) and some leaked samples from the training data distribution. Such attacks are commonly referred to as Membership Inference attacks. We show realistic Membership Inference attacks on deep learning models trained for 3D neuroimaging tasks in a centralized as well as decentralized setup. We demonstrate feasible attacks on brain age prediction models (deep learning models that predict a person's age from their brain MRI scan). We correctly identified whether an MRI scan was used in model training with a 60% to over 80% success rate depending on model complexity and security assumptions.
Biomedical Named Entity Recognition via Reference-Set Augmented Bootstrapping
Jun 01, 2019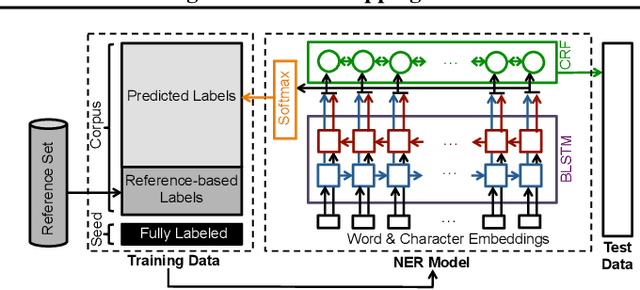
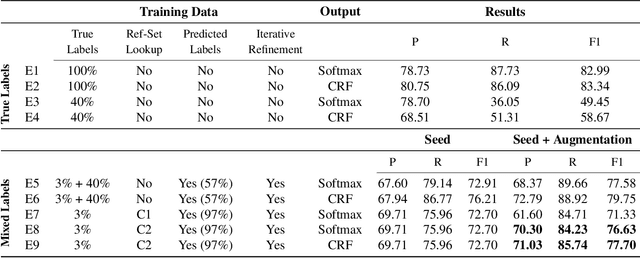
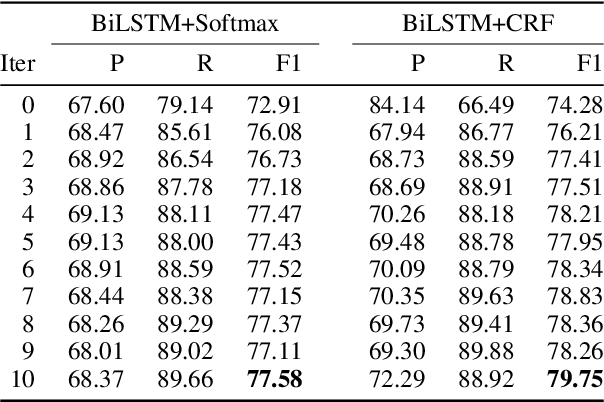
We present a weakly-supervised data augmentation approach to improve Named Entity Recognition (NER) in a challenging domain: extracting biomedical entities (e.g., proteins) from the scientific literature. First, we train a neural NER (NNER) model over a small seed of fully-labeled examples. Second, we use a reference set of entity names (e.g., proteins in UniProt) to identify entity mentions with high precision, but low recall, on an unlabeled corpus. Third, we use the NNER model to assign weak labels to the corpus. Finally, we retrain our NNER model iteratively over the augmented training set, including the seed, the reference-set examples, and the weakly-labeled examples, which improves model performance. We show empirically that this augmented bootstrapping process significantly improves NER performance, and discuss the factors impacting the efficacy of the approach.