 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting-Aware Expert Calibration for Machine Unlearning in Mixture-of-Experts Language Models
Jun 09, 2026Machine unlearning is increasingly important for large language models, yet unlearning in Mixture-of-Experts (MoE) architectures remains underexplored. Unlike dense models, MoE architectures employ a router at each layer to assign each token to a sparse subset of experts. In this work, we observe that forget data often activates a small subset of experts disproportionately, while these experts may receive much weaker activation from retain data. This forget--retain routing mismatch can leave forget-critical experts under-regularized during unlearning. To address this, we propose \textbf{TRACE}, Targeted Routing-Aware Calibration of Experts, for MoE unlearning. TRACE first detects forget-critical experts from offline activation statistics, and then calibrates retain regularization by reweighting token-level retain losses so that each selected expert's retain-side activation frequency better matches its forget-side counterpart. Experiments on WMDP and MUSE-BOOKS across multiple MoE LLMs show that TRACE consistently improves the forget-utility trade-off, yielding a 9\% relative utility improvement over the strongest baseline under comparable forgetting quality and the best performance on three out of four MUSE-BOOKS metrics.
Estimating Mutual Information between Time Series and Temporal Event Sequences Across Diverse Analysis Tasks
Jun 01, 2026Pairwise dependence measures such as correlation and causality are fundamental to temporal data mining, yet there is still no principled and robust way to quantify dependence between heterogeneous data types, especially between continuous time series and discrete temporal event sequences. Existing approaches rely on ad hoc transformations or mutual-information estimators that are highly sensitive to quantization, repeated values, and event redundancy, leading to biased or unstable results in practice. We propose a nonparametric mutual information estimator that directly measures the dependence between time series and event sequences without data transformation, learning, or ad hoc discretization. Our method models the continuous-discrete duality of real-world time series to handle quantization and repeated-value artifacts and introduces a latent event clustering strategy to mitigate bias from event co-occurrence and redundancy. Together, these yield a robust and unified framework that bridges discrete and continuous mutual information. We evaluate the proposed estimator on four representative tasks: discrete-continuous time-delayed mutual information for causality analysis, global and local temporal repetition discovery, discrete covariate selection for time series forecasting, and continuous feature selection for classification. Experiments on synthetic and real-world datasets show consistent improvements over existing methods in accuracy, robustness, and interpretability, positioning our approach as a general-purpose dependence operator for heterogeneous temporal data, similar to Pearson correlation for homogeneous time series. Code available at: https://github.com/HaojiHu/Multimodal-Temporal-Data-Quantification
TiCLS : Tightly Coupled Language Text Spotter
Feb 03, 2026Scene text spotting aims to detect and recognize text in real-world images, where instances are often short, fragmented, or visually ambiguous. Existing methods primarily rely on visual cues and implicitly capture local character dependencies, but they overlook the benefits of external linguistic knowledge. Prior attempts to integrate language models either adapt language modeling objectives without external knowledge or apply pretrained models that are misaligned with the word-level granularity of scene text. We propose TiCLS, an end-to-end text spotter that explicitly incorporates external linguistic knowledge from a character-level pretrained language model. TiCLS introduces a linguistic decoder that fuses visual and linguistic features, yet can be initialized by a pretrained language model, enabling robust recognition of ambiguous or fragmented text. Experiments on ICDAR 2015 and Total-Text demonstrate that TiCLS achieves state-of-the-art performance, validating the effectiveness of PLM-guided linguistic integration for scene text spotting.
FRIEDA: Benchmarking Multi-Step Cartographic Reasoning in Vision-Language Models
Dec 08, 2025Cartographic reasoning is the skill of interpreting geographic relationships by aligning legends, map scales, compass directions, map texts, and geometries across one or more map images. Although essential as a concrete cognitive capability and for critical tasks such as disaster response and urban planning, it remains largely unevaluated. Building on progress in chart and infographic understanding, recent large vision language model studies on map visual question-answering often treat maps as a special case of charts. In contrast, map VQA demands comprehension of layered symbology (e.g., symbols, geometries, and text labels) as well as spatial relations tied to orientation and distance that often span multiple maps and are not captured by chart-style evaluations. To address this gap, we introduce FRIEDA, a benchmark for testing complex open-ended cartographic reasoning in LVLMs. FRIEDA sources real map images from documents and reports in various domains and geographical areas. Following classifications in Geographic Information System (GIS) literature, FRIEDA targets all three categories of spatial relations: topological (border, equal, intersect, within), metric (distance), and directional (orientation). All questions require multi-step inference, and many require cross-map grounding and reasoning. We evaluate eleven state-of-the-art LVLMs under two settings: (1) the direct setting, where we provide the maps relevant to the question, and (2) the contextual setting, where the model may have to identify the maps relevant to the question before reasoning. Even the strongest models, Gemini-2.5-Pro and GPT-5-Think, achieve only 38.20% and 37.20% accuracy, respectively, far below human performance of 84.87%. These results reveal a persistent gap in multi-step cartographic reasoning, positioning FRIEDA as a rigorous benchmark to drive progress on spatial intelligence in LVLMs.
Hyper-Local Deformable Transformers for Text Spotting on Historical Maps
Jun 17, 2025
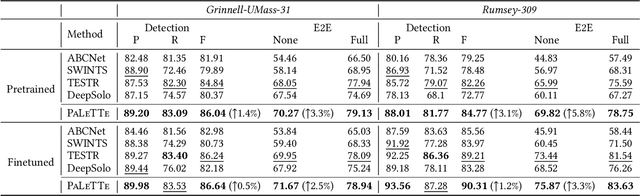


Text on historical maps contains valuable information providing georeferenced historical, political, and cultural contexts. However, text extraction from historical maps is challenging due to the lack of (1) effective methods and (2) training data. Previous approaches use ad-hoc steps tailored to only specific map styles. Recent machine learning-based text spotters (e.g., for scene images) have the potential to solve these challenges because of their flexibility in supporting various types of text instances. However, these methods remain challenges in extracting precise image features for predicting every sub-component (boundary points and characters) in a text instance. This is critical because map text can be lengthy and highly rotated with complex backgrounds, posing difficulties in detecting relevant image features from a rough text region. This paper proposes PALETTE, an end-to-end text spotter for scanned historical maps of a wide variety. PALETTE introduces a novel hyper-local sampling module to explicitly learn localized image features around the target boundary points and characters of a text instance for detection and recognition. PALETTE also enables hyper-local positional embeddings to learn spatial interactions between boundary points and characters within and across text instances. In addition, this paper presents a novel approach to automatically generate synthetic map images, SynthMap+, for training text spotters for historical maps. The experiment shows that PALETTE with SynthMap+ outperforms SOTA text spotters on two new benchmark datasets of historical maps, particularly for long and angled text. We have deployed PALETTE with SynthMap+ to process over 60,000 maps in the David Rumsey Historical Map collection and generated over 100 million text labels to support map searching. The project is released at https://github.com/kartta-foundation/mapkurator-palette-doc.
The mapKurator System: A Complete Pipeline for Extracting and Linking Text from Historical Maps
Jul 03, 2023



Scanned historical maps in libraries and archives are valuable repositories of geographic data that often do not exist elsewhere. Despite the potential of machine learning tools like the Google Vision APIs for automatically transcribing text from these maps into machine-readable formats, they do not work well with large-sized images (e.g., high-resolution scanned documents), cannot infer the relation between the recognized text and other datasets, and are challenging to integrate with post-processing tools. This paper introduces the mapKurator system, an end-to-end system integrating machine learning models with a comprehensive data processing pipeline. mapKurator empowers automated extraction, post-processing, and linkage of text labels from large numbers of large-dimension historical map scans. The output data, comprising bounding polygons and recognized text, is in the standard GeoJSON format, making it easily modifiable within Geographic Information Systems (GIS). The proposed system allows users to quickly generate valuable data from large numbers of historical maps for in-depth analysis of the map content and, in turn, encourages map findability, accessibility, interoperability, and reusability (FAIR principles). We deployed the mapKurator system and enabled the processing of over 60,000 maps and over 100 million text/place names in the David Rumsey Historical Map collection. We also demonstrated a seamless integration of mapKurator with a collaborative web platform to enable accessing automated approaches for extracting and linking text labels from historical map scans and collective work to improve the results.
Building Autocorrelation-Aware Representations for Fine-Scale Spatiotemporal Prediction
Dec 10, 2021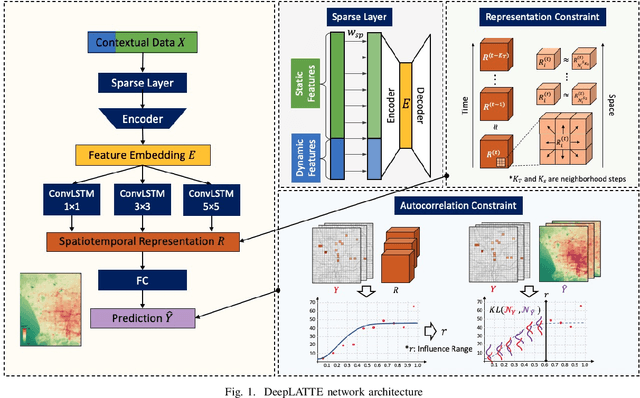
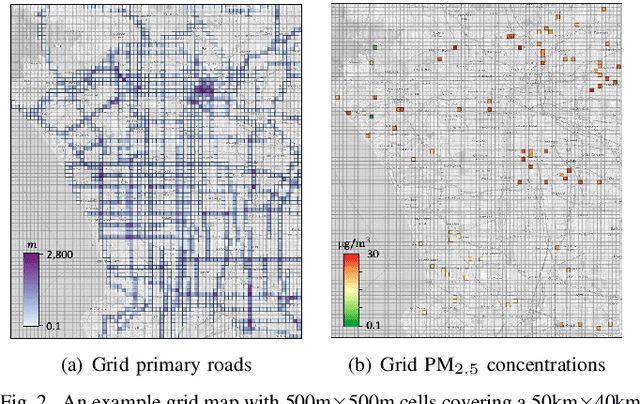
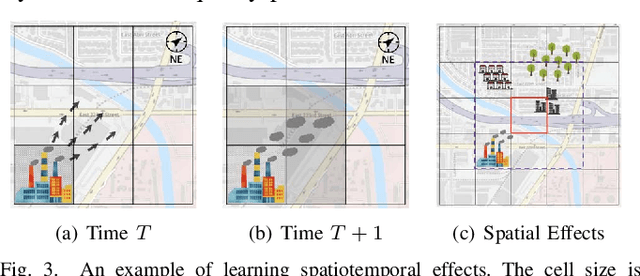
Many scientific prediction problems have spatiotemporal data- and modeling-related challenges in handling complex variations in space and time using only sparse and unevenly distributed observations. This paper presents a novel deep learning architecture, Deep learning predictions for LocATion-dependent Time-sEries data (DeepLATTE), that explicitly incorporates theories of spatial statistics into neural networks to address these challenges. In addition to a feature selection module and a spatiotemporal learning module, DeepLATTE contains an autocorrelation-guided semi-supervised learning strategy to enforce both local autocorrelation patterns and global autocorrelation trends of the predictions in the learned spatiotemporal embedding space to be consistent with the observed data, overcoming the limitation of sparse and unevenly distributed observations. During the training process, both supervised and semi-supervised losses guide the updates of the entire network to: 1) prevent overfitting, 2) refine feature selection, 3) learn useful spatiotemporal representations, and 4) improve overall prediction. We conduct a demonstration of DeepLATTE using publicly available data for an important public health topic, air quality prediction, in a well-studied, complex physical environment - Los Angeles. The experiment demonstrates that the proposed approach provides accurate fine-spatial-scale air quality predictions and reveals the critical environmental factors affecting the results.
A Semi-Supervised Approach for Abnormal Event Prediction on Large Operational Network Time-Series Data
Oct 14, 2021
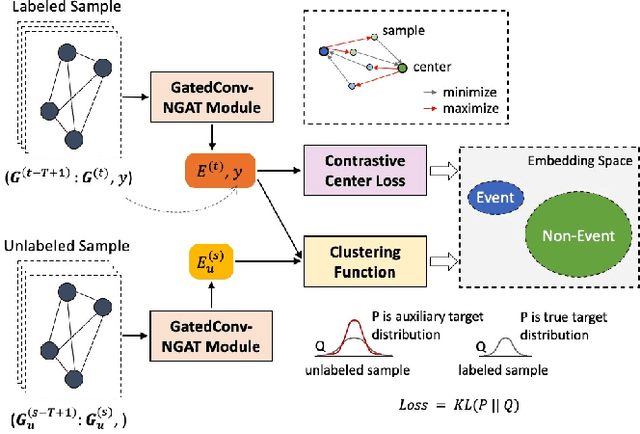
Large network logs, recording multivariate time series generated from heterogeneous devices and sensors in a network, can often reveal important information about abnormal activities, such as network intrusions and device malfunctions. Existing machine learning methods for anomaly detection on multivariate time series typically assume that 1) normal sequences would have consistent behavior for training unsupervised models, or 2) require a large set of labeled normal and abnormal sequences for supervised models. However, in practice, normal network activities can demonstrate significantly varying sequence patterns (e.g., before and after rerouting partial network traffic). Also, the recorded abnormal events can be sparse. This paper presents a novel semi-supervised method that efficiently captures dependencies between network time series and across time points to generate meaningful representations of network activities for predicting abnormal events. The method can use the limited labeled data to explicitly learn separable embedding space for normal and abnormal samples and effectively leverage unlabeled data to handle training data scarcity. The experiments demonstrate that our approach significantly outperformed state-of-the-art approaches for event detection on a large real-world network log.
A Comparison and Strategy of Semantic Segmentation on Remote Sensing Images
May 24, 2019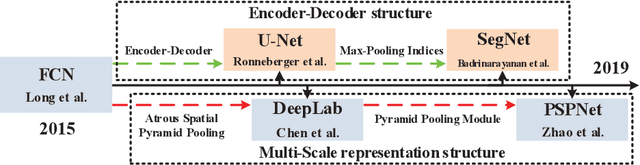
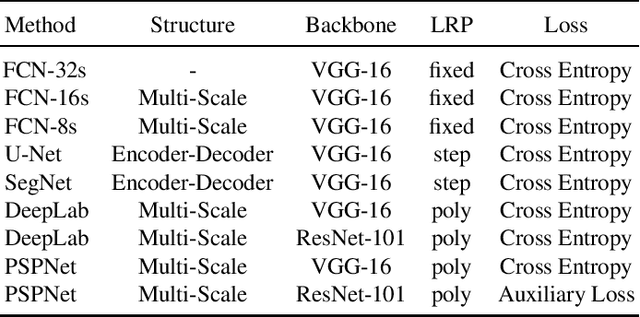
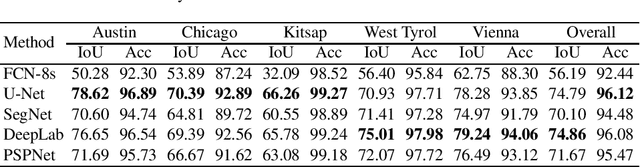
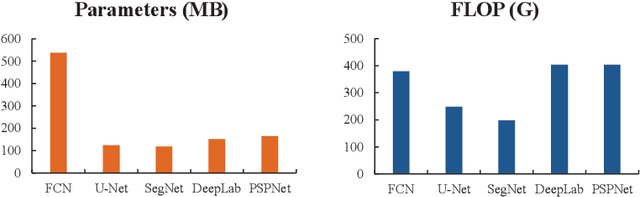
In recent years, with the development of aerospace technology, we use more and more images captured by satellites to obtain information. But a large number of useless raw images, limited data storage resource and poor transmission capability on satellites hinder our use of valuable images. Therefore, it is necessary to deploy an on-orbit semantic segmentation model to filter out useless images before data transmission. In this paper, we present a detailed comparison on the recent deep learning models. Considering the computing environment of satellites, we compare methods from accuracy, parameters and resource consumption on the same public dataset. And we also analyze the relation between them. Based on experimental results, we further propose a viable on-orbit semantic segmentation strategy. It will be deployed on the TianZhi-2 satellite which supports deep learning methods and will be lunched soon.