 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransit for All: Mapping Equitable Bike2Subway Connection using Region Representation Learning
Jun 18, 2025



Ensuring equitable public transit access remains challenging, particularly in densely populated cities like New York City (NYC), where low-income and minority communities often face limited transit accessibility. Bike-sharing systems (BSS) can bridge these equity gaps by providing affordable first- and last-mile connections. However, strategically expanding BSS into underserved neighborhoods is difficult due to uncertain bike-sharing demand at newly planned ("cold-start") station locations and limitations in traditional accessibility metrics that may overlook realistic bike usage potential. We introduce Transit for All (TFA), a spatial computing framework designed to guide the equitable expansion of BSS through three components: (1) spatially-informed bike-sharing demand prediction at cold-start stations using region representation learning that integrates multimodal geospatial data, (2) comprehensive transit accessibility assessment leveraging our novel weighted Public Transport Accessibility Level (wPTAL) by combining predicted bike-sharing demand with conventional transit accessibility metrics, and (3) strategic recommendations for new bike station placements that consider potential ridership and equity enhancement. Using NYC as a case study, we identify transit accessibility gaps that disproportionately impact low-income and minority communities in historically underserved neighborhoods. Our results show that strategically placing new stations guided by wPTAL notably reduces disparities in transit access related to economic and demographic factors. From our study, we demonstrate that TFA provides practical guidance for urban planners to promote equitable transit and enhance the quality of life in underserved urban communities.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Anchors Aweigh! Sail for Optimal Unified Multi-Modal Representations
Oct 02, 2024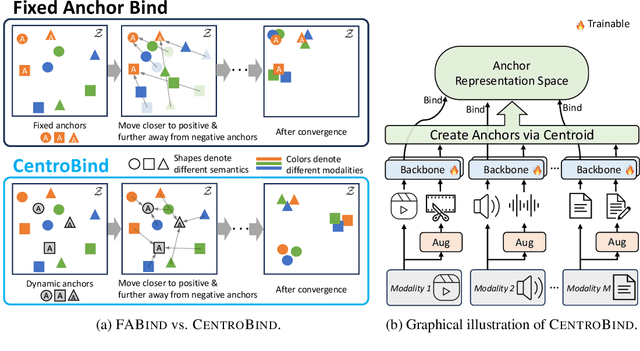
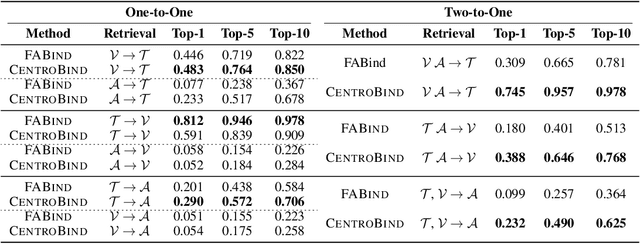
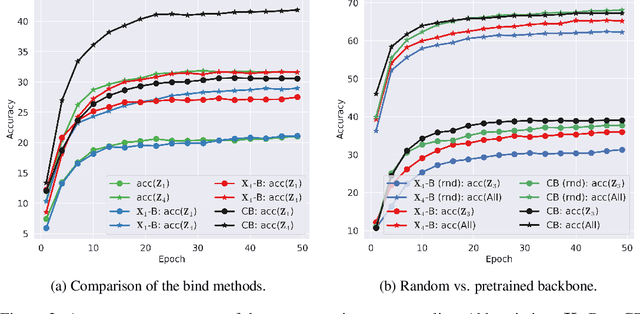
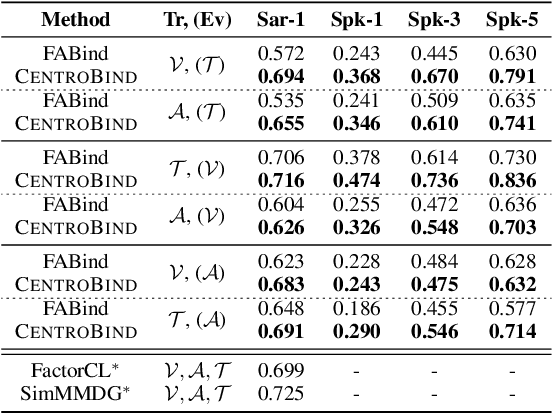
Multimodal learning plays a crucial role in enabling machine learning models to fuse and utilize diverse data sources, such as text, images, and audio, to support a variety of downstream tasks. A unified representation across various modalities is particularly important for improving efficiency and performance. Recent binding methods, such as ImageBind (Girdhar et al., 2023), typically use a fixed anchor modality to align multimodal data in the anchor modal embedding space. In this paper, we mathematically analyze the fixed anchor binding methods and uncover notable limitations: (1) over-reliance on the choice of the anchor modality, (2) failure to capture intra-modal information, and (3) failure to account for inter-modal correlation among non-anchored modalities. To address these limitations, we propose CentroBind, a simple yet powerful approach that eliminates the need for a fixed anchor; instead, it employs dynamically adjustable centroid-based anchors generated from all available modalities, resulting in a balanced and rich representation space. We theoretically demonstrate that our method captures three crucial properties of multimodal learning: intra-modal learning, inter-modal learning, and multimodal alignment, while also constructing a robust unified representation across all modalities. Our experiments on both synthetic and real-world datasets demonstrate the superiority of the proposed method, showing that dynamic anchor methods outperform all fixed anchor binding methods as the former captures more nuanced multimodal interactions.
The mapKurator System: A Complete Pipeline for Extracting and Linking Text from Historical Maps
Jul 03, 2023



Scanned historical maps in libraries and archives are valuable repositories of geographic data that often do not exist elsewhere. Despite the potential of machine learning tools like the Google Vision APIs for automatically transcribing text from these maps into machine-readable formats, they do not work well with large-sized images (e.g., high-resolution scanned documents), cannot infer the relation between the recognized text and other datasets, and are challenging to integrate with post-processing tools. This paper introduces the mapKurator system, an end-to-end system integrating machine learning models with a comprehensive data processing pipeline. mapKurator empowers automated extraction, post-processing, and linkage of text labels from large numbers of large-dimension historical map scans. The output data, comprising bounding polygons and recognized text, is in the standard GeoJSON format, making it easily modifiable within Geographic Information Systems (GIS). The proposed system allows users to quickly generate valuable data from large numbers of historical maps for in-depth analysis of the map content and, in turn, encourages map findability, accessibility, interoperability, and reusability (FAIR principles). We deployed the mapKurator system and enabled the processing of over 60,000 maps and over 100 million text/place names in the David Rumsey Historical Map collection. We also demonstrated a seamless integration of mapKurator with a collaborative web platform to enable accessing automated approaches for extracting and linking text labels from historical map scans and collective work to improve the results.