 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLHRS-Bot: Empowering Remote Sensing with VGI-Enhanced Large Multimodal Language Model
Paper and Code

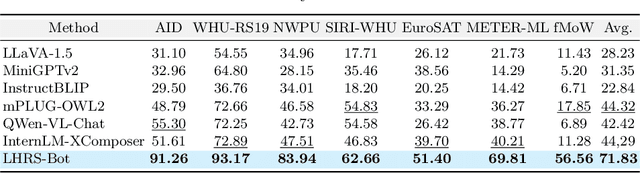


The revolutionary capabilities of large language models (LLMs) have paved the way for multimodal large language models (MLLMs) and fostered diverse applications across various specialized domains. In the remote sensing (RS) field, however, the diverse geographical landscapes and varied objects in RS imagery are not adequately considered in recent MLLM endeavors. To bridge this gap, we construct a large-scale RS image-text dataset, LHRS-Align, and an informative RS-specific instruction dataset, LHRS-Instruct, leveraging the extensive volunteered geographic information (VGI) and globally available RS images. Building on this foundation, we introduce LHRS-Bot, an MLLM tailored for RS image understanding through a novel multi-level vision-language alignment strategy and a curriculum learning method. Comprehensive experiments demonstrate that LHRS-Bot exhibits a profound understanding of RS images and the ability to perform nuanced reasoning within the RS domain.