 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechQE: Estimating the Quality of Direct Speech Translation
Paper and Code
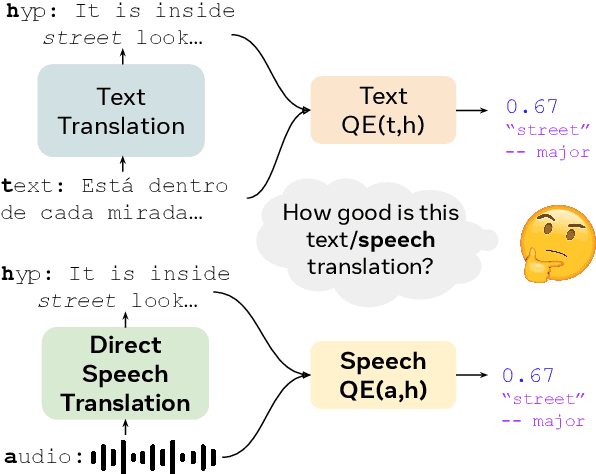
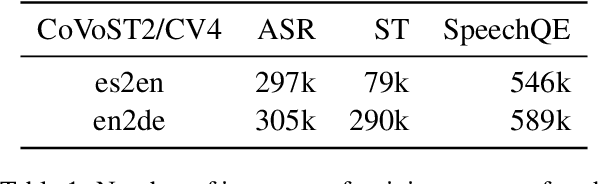
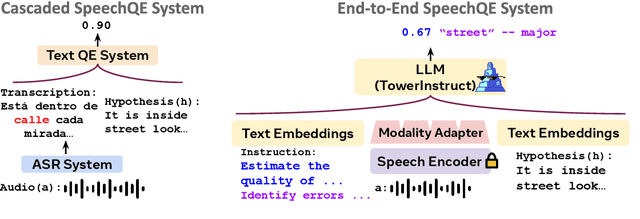
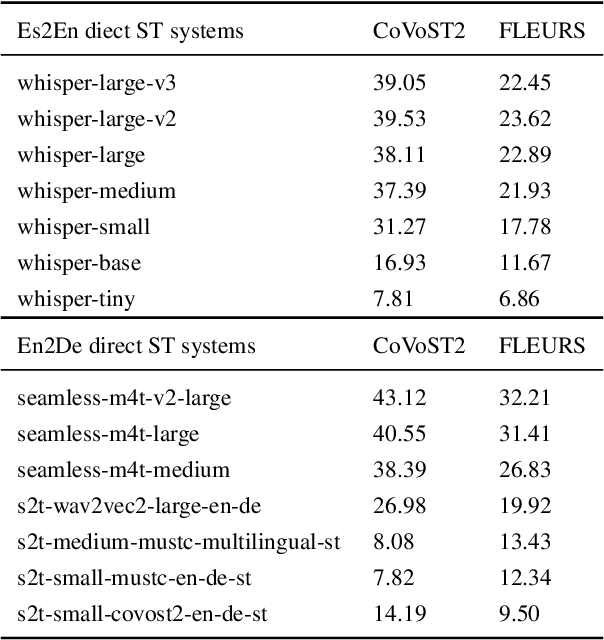
Recent advances in automatic quality estimation for machine translation have exclusively focused on written language, leaving the speech modality underexplored. In this work, we formulate the task of quality estimation for speech translation (SpeechQE), construct a benchmark, and evaluate a family of systems based on cascaded and end-to-end architectures. In this process, we introduce a novel end-to-end system leveraging pre-trained text LLM. Results suggest that end-to-end approaches are better suited to estimating the quality of direct speech translation than using quality estimation systems designed for text in cascaded systems. More broadly, we argue that quality estimation of speech translation needs to be studied as a separate problem from that of text, and release our data and models to guide further research in this space.