 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFix: Perceptually Enhanced Gaussian Splatting Video Compression
Nov 10, 2025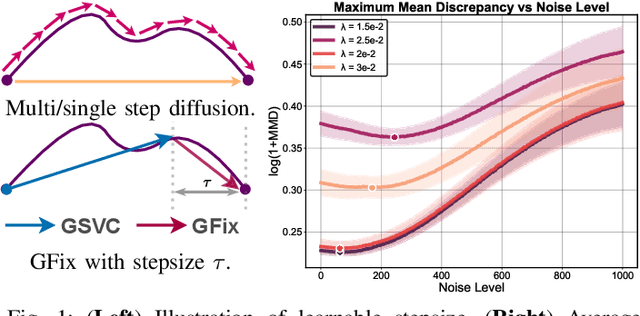
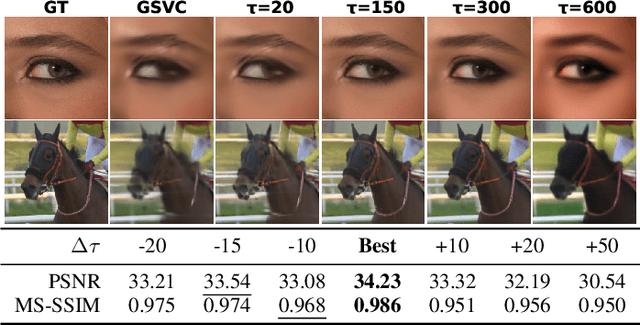
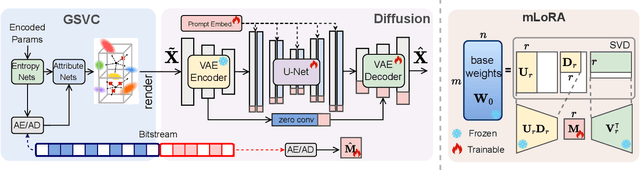
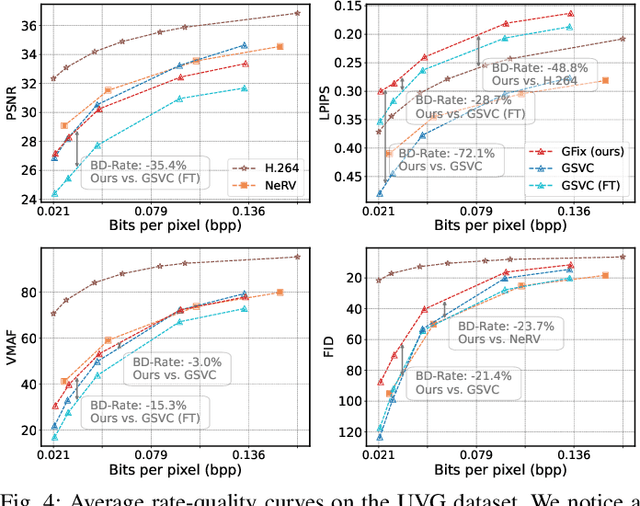
3D Gaussian Splatting (3DGS) enhances 3D scene reconstruction through explicit representation and fast rendering, demonstrating potential benefits for various low-level vision tasks, including video compression. However, existing 3DGS-based video codecs generally exhibit more noticeable visual artifacts and relatively low compression ratios. In this paper, we specifically target the perceptual enhancement of 3DGS-based video compression, based on the assumption that artifacts from 3DGS rendering and quantization resemble noisy latents sampled during diffusion training. Building on this premise, we propose a content-adaptive framework, GFix, comprising a streamlined, single-step diffusion model that serves as an off-the-shelf neural enhancer. Moreover, to increase compression efficiency, We propose a modulated LoRA scheme that freezes the low-rank decompositions and modulates the intermediate hidden states, thereby achieving efficient adaptation of the diffusion backbone with highly compressible updates. Experimental results show that GFix delivers strong perceptual quality enhancement, outperforming GSVC with up to 72.1% BD-rate savings in LPIPS and 21.4% in FID.
Compressed Video Super-Resolution based on Hierarchical Encoding
Jun 17, 2025



This paper presents a general-purpose video super-resolution (VSR) method, dubbed VSR-HE, specifically designed to enhance the perceptual quality of compressed content. Targeting scenarios characterized by heavy compression, the method upscales low-resolution videos by a ratio of four, from 180p to 720p or from 270p to 1080p. VSR-HE adopts hierarchical encoding transformer blocks and has been sophisticatedly optimized to eliminate a wide range of compression artifacts commonly introduced by H.265/HEVC encoding across various quantization parameter (QP) levels. To ensure robustness and generalization, the model is trained and evaluated under diverse compression settings, allowing it to effectively restore fine-grained details and preserve visual fidelity. The proposed VSR-HE has been officially submitted to the ICME 2025 Grand Challenge on VSR for Video Conferencing (Team BVI-VSR), under both the Track 1 (General-Purpose Real-World Video Content) and Track 2 (Talking Head Videos).
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
GIViC: Generative Implicit Video Compression
Mar 25, 2025While video compression based on implicit neural representations (INRs) has recently demonstrated great potential, existing INR-based video codecs still cannot achieve state-of-the-art (SOTA) performance compared to their conventional or autoencoder-based counterparts given the same coding configuration. In this context, we propose a Generative Implicit Video Compression framework, GIViC, aiming at advancing the performance limits of this type of coding methods. GIViC is inspired by the characteristics that INRs share with large language and diffusion models in exploiting long-term dependencies. Through the newly designed implicit diffusion process, GIViC performs diffusive sampling across coarse-to-fine spatiotemporal decompositions, gradually progressing from coarser-grained full-sequence diffusion to finer-grained per-token diffusion. A novel Hierarchical Gated Linear Attention-based transformer (HGLA), is also integrated into the framework, which dual-factorizes global dependency modeling along scale and sequential axes. The proposed GIViC model has been benchmarked against SOTA conventional and neural codecs using a Random Access (RA) configuration (YUV 4:2:0, GOPSize=32), and yields BD-rate savings of 15.94%, 22.46% and 8.52% over VVC VTM, DCVC-FM and NVRC, respectively. As far as we are aware, GIViC is the first INR-based video codec that outperforms VTM based on the RA coding configuration. The source code will be made available.
C2D-ISR: Optimizing Attention-based Image Super-resolution from Continuous to Discrete Scales
Mar 17, 2025In recent years, attention mechanisms have been exploited in single image super-resolution (SISR), achieving impressive reconstruction results. However, these advancements are still limited by the reliance on simple training strategies and network architectures designed for discrete up-sampling scales, which hinder the model's ability to effectively capture information across multiple scales. To address these limitations, we propose a novel framework, \textbf{C2D-ISR}, for optimizing attention-based image super-resolution models from both performance and complexity perspectives. Our approach is based on a two-stage training methodology and a hierarchical encoding mechanism. The new training methodology involves continuous-scale training for discrete scale models, enabling the learning of inter-scale correlations and multi-scale feature representation. In addition, we generalize the hierarchical encoding mechanism with existing attention-based network structures, which can achieve improved spatial feature fusion, cross-scale information aggregation, and more importantly, much faster inference. We have evaluated the C2D-ISR framework based on three efficient attention-based backbones, SwinIR-L, SRFormer-L and MambaIRv2-L, and demonstrated significant improvements over the other existing optimization framework, HiT, in terms of super-resolution performance (up to 0.2dB) and computational complexity reduction (up to 11%). The source code will be made publicly available at www.github.com.
Benchmarking Conventional and Learned Video Codecs with a Low-Delay Configuration
Aug 09, 2024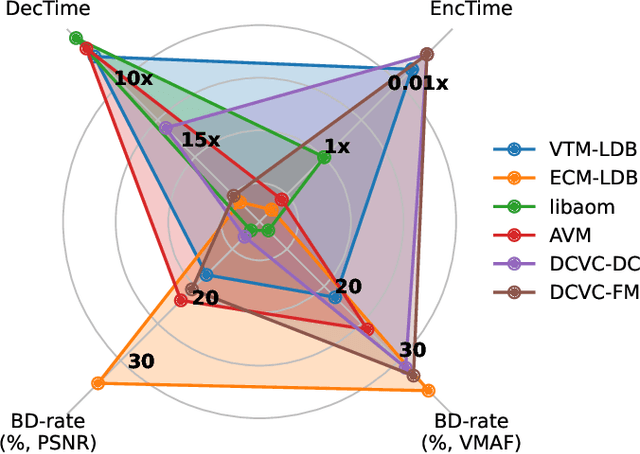
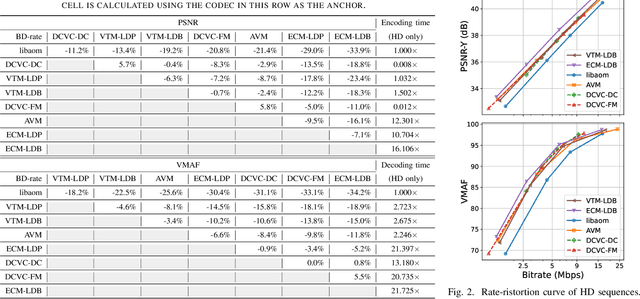
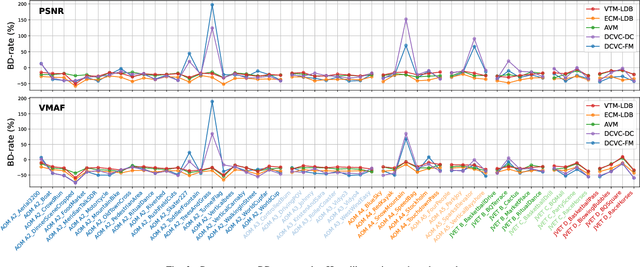

Recent advances in video compression have seen significant coding performance improvements with the development of new standards and learning-based video codecs. However, most of these works focus on application scenarios that allow a certain amount of system delay (e.g., Random Access mode in MPEG codecs), which is not always acceptable for live delivery. This paper conducts a comparative study of state-of-the-art conventional and learned video coding methods based on a low delay configuration. Specifically, this study includes two MPEG standard codecs (H.266/VVC VTM and JVET ECM), two AOM codecs (AV1 libaom and AVM), and two recent neural video coding models (DCVC-DC and DCVC-FM). To allow a fair and meaningful comparison, the evaluation was performed on test sequences defined in the AOM and MPEG common test conditions in the YCbCr 4:2:0 color space. The evaluation results show that the JVET ECM codecs offer the best overall coding performance among all codecs tested, with a 16.1% (based on PSNR) average BD-rate saving over AOM AVM, and 11.0% over DCVC-FM. We also observed inconsistent performance with the learned video codecs, DCVC-DC and DCVC-FM, for test content with large background motions.