 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2D-ISR: Optimizing Attention-based Image Super-resolution from Continuous to Discrete Scales
Mar 17, 2025In recent years, attention mechanisms have been exploited in single image super-resolution (SISR), achieving impressive reconstruction results. However, these advancements are still limited by the reliance on simple training strategies and network architectures designed for discrete up-sampling scales, which hinder the model's ability to effectively capture information across multiple scales. To address these limitations, we propose a novel framework, \textbf{C2D-ISR}, for optimizing attention-based image super-resolution models from both performance and complexity perspectives. Our approach is based on a two-stage training methodology and a hierarchical encoding mechanism. The new training methodology involves continuous-scale training for discrete scale models, enabling the learning of inter-scale correlations and multi-scale feature representation. In addition, we generalize the hierarchical encoding mechanism with existing attention-based network structures, which can achieve improved spatial feature fusion, cross-scale information aggregation, and more importantly, much faster inference. We have evaluated the C2D-ISR framework based on three efficient attention-based backbones, SwinIR-L, SRFormer-L and MambaIRv2-L, and demonstrated significant improvements over the other existing optimization framework, HiT, in terms of super-resolution performance (up to 0.2dB) and computational complexity reduction (up to 11%). The source code will be made publicly available at www.github.com.
HIIF: Hierarchical Encoding based Implicit Image Function for Continuous Super-resolution
Dec 04, 2024



Recent advances in implicit neural representations (INRs) have shown significant promise in modeling visual signals for various low-vision tasks including image super-resolution (ISR). INR-based ISR methods typically learn continuous representations, providing flexibility for generating high-resolution images at any desired scale from their low-resolution counterparts. However, existing INR-based ISR methods utilize multi-layer perceptrons for parameterization in the network; this does not take account of the hierarchical structure existing in local sampling points and hence constrains the representation capability. In this paper, we propose a new \textbf{H}ierarchical encoding based \textbf{I}mplicit \textbf{I}mage \textbf{F}unction for continuous image super-resolution, \textbf{HIIF}, which leverages a novel hierarchical positional encoding that enhances the local implicit representation, enabling it to capture fine details at multiple scales. Our approach also embeds a multi-head linear attention mechanism within the implicit attention network by taking additional non-local information into account. Our experiments show that, when integrated with different backbone encoders, HIIF outperforms the state-of-the-art continuous image super-resolution methods by up to 0.17dB in PSNR. The source code of HIIF will be made publicly available at \url{www.github.com}.
RTSR: A Real-Time Super-Resolution Model for AV1 Compressed Content
Nov 20, 2024



Super-resolution (SR) is a key technique for improving the visual quality of video content by increasing its spatial resolution while reconstructing fine details. SR has been employed in many applications including video streaming, where compressed low-resolution content is typically transmitted to end users and then reconstructed with a higher resolution and enhanced quality. To support real-time playback, it is important to implement fast SR models while preserving reconstruction quality; however most existing solutions, in particular those based on complex deep neural networks, fail to do so. To address this issue, this paper proposes a low-complexity SR method, RTSR, designed to enhance the visual quality of compressed video content, focusing on resolution up-scaling from a) 360p to 1080p and from b) 540p to 4K. The proposed approach utilizes a CNN-based network architecture, which was optimized for AV1 (SVT)-encoded content at various quantization levels based on a dual-teacher knowledge distillation method. This method was submitted to the AIM 2024 Video Super-Resolution Challenge, specifically targeting the Efficient/Mobile Real-Time Video Super-Resolution competition. It achieved the best trade-off between complexity and coding performance (measured in PSNR, SSIM and VMAF) among all six submissions. The code will be available soon.
BVI-AOM: A New Training Dataset for Deep Video Compression Optimization
Aug 07, 2024Deep learning is now playing an important role in enhancing the performance of conventional hybrid video codecs. These learning-based methods typically require diverse and representative training material for optimization in order to achieve model generalization and optimal coding performance. However, existing datasets either offer limited content variability or come with restricted licensing terms constraining their use to research purposes only. To address these issues, we propose a new training dataset, named BVI-AOM, which contains 956 uncompressed sequences at various resolutions from 270p to 2160p, covering a wide range of content and texture types. The dataset comes with more flexible licensing terms and offers competitive performance when used as a training set for optimizing deep video coding tools. The experimental results demonstrate that when used as a training set to optimize two popular network architectures for two different coding tools, the proposed dataset leads to additional bitrate savings of up to 0.29 and 2.98 percentage points in terms of PSNR-Y and VMAF, respectively, compared to an existing training dataset, BVI-DVC, which has been widely used for deep video coding. The BVI-AOM dataset is available for download under this link: (TBD).
Improving Maximum Likelihood Difference Scaling method to measure inter content scale
Feb 25, 2022

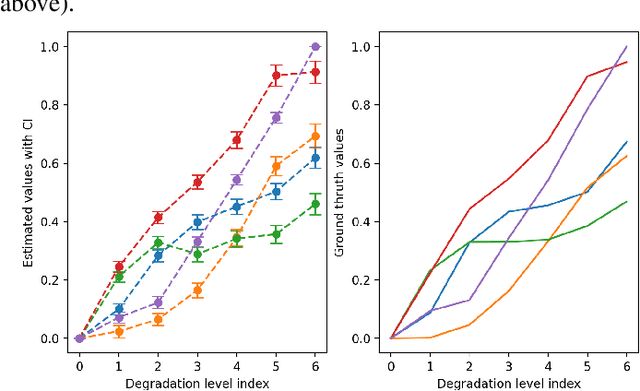
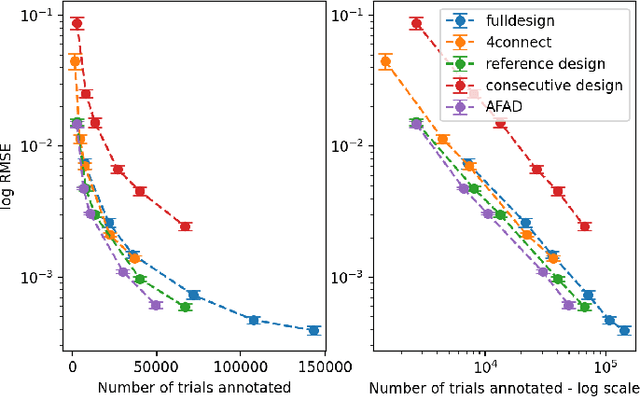
The goal of most subjective studies is to place a set of stimuli on a perceptual scale. This is mostly done directly by rating, e.g. using single or double stimulus methodologies, or indirectly by ranking or pairwise comparison. All these methods estimate the perceptual magnitudes of the stimuli on a scale. However, procedures such as Maximum Likelihood Difference Scaling (MLDS) have shown that considering perceptual distances can bring benefits in terms of discriminatory power, observers' cognitive load, and the number of trials required. One of the disadvantages of the MLDS method is that the perceptual scales obtained for stimuli created from different source content are generally not comparable. In this paper, we propose an extension of the MLDS method that ensures inter-content comparability of the results and shows its usefulness especially in the presence of observer errors.
Deep Learning for Radio-based Human Sensing: Recent Advances and Future Directions
Oct 23, 2020
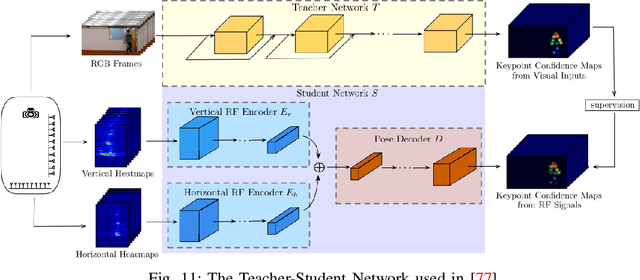
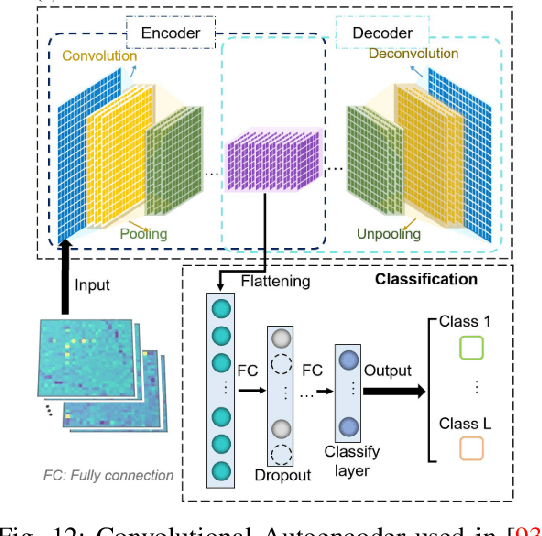
While decade-long research has clearly demonstrated the vast potential of radio frequency (RF) for many human sensing tasks, scaling this technology to large scenarios remained problematic with conventional approaches. Recently, researchers have successfully applied deep learning to take radio-based sensing to a new level. Many different types of deep learning models have been proposed to achieve high sensing accuracy over a large population and activity set, as well as in unseen environments. Deep learning has also enabled detection of novel human sensing phenomena that were previously not possible. In this survey, we provide a comprehensive review and taxonomy of recent research efforts on deep learning based RF sensing. We also identify and compare several publicly released labeled RF sensing datasets that can facilitate such deep learning research. Finally, we summarize the lessons learned and discuss the current limitations and future directions of deep learning based RF sensing.
DeepWiPHY: Deep Learning-based Receiver Design and Dataset for IEEE 802.11ax Systems
Oct 19, 2020
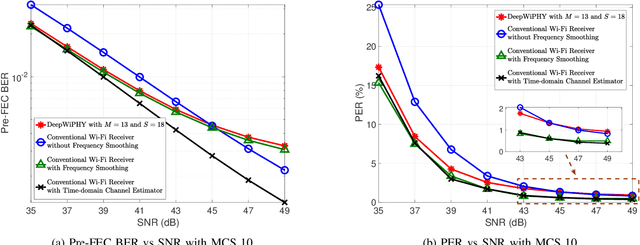
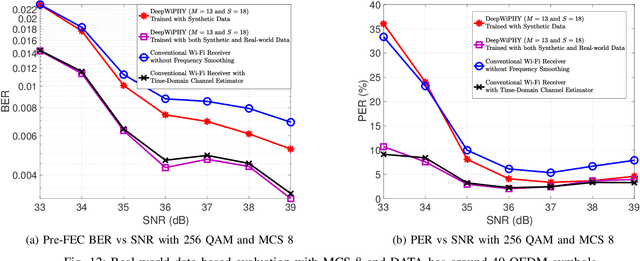
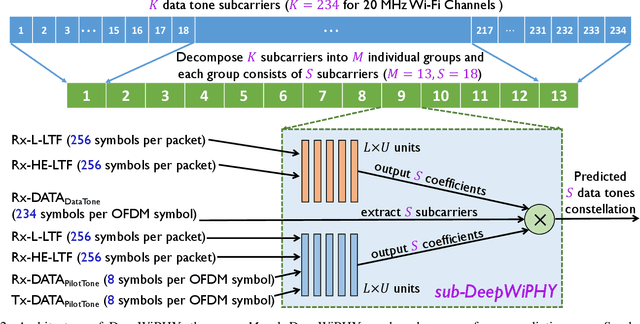
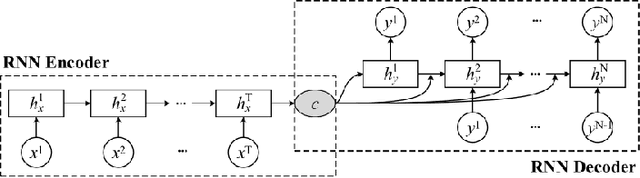
In this work, we develop DeepWiPHY, a deep learning-based architecture to replace the channel estimation, common phase error (CPE) correction, sampling rate offset (SRO) correction, and equalization modules of IEEE 802.11ax based orthogonal frequency division multiplexing (OFDM) receivers. We first train DeepWiPHY with a synthetic dataset, which is generated using representative indoor channel models and includes typical radio frequency (RF) impairments that are the source of nonlinearity in wireless systems. To further train and evaluate DeepWiPHY with real-world data, we develop a passive sniffing-based data collection testbed composed of Universal Software Radio Peripherals (USRPs) and commercially available IEEE 802.11ax products. The comprehensive evaluation of DeepWiPHY with synthetic and real-world datasets (110 million synthetic OFDM symbols and 14 million real-world OFDM symbols) confirms that, even without fine-tuning the neural network's architecture parameters, DeepWiPHY achieves comparable performance to or outperforms the conventional WLAN receivers, in terms of both bit error rate (BER) and packet error rate (PER), under a wide range of channel models, signal-to-noise (SNR) levels, and modulation schemes.