 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Neural Surrogate for Link-Level Path Loss Prediction from Variable-Sized Maps
Oct 10, 2023Estimating path loss for a transmitter-receiver location is key to many use-cases including network planning and handover. Machine learning has become a popular tool to predict wireless channel properties based on map data. In this work, we present a transformer-based neural network architecture that enables predicting link-level properties from maps of various dimensions and from sparse measurements. The map contains information about buildings and foliage. The transformer model attends to the regions that are relevant for path loss prediction and, therefore, scales efficiently to maps of different size. Further, our approach works with continuous transmitter and receiver coordinates without relying on discretization. In experiments, we show that the proposed model is able to efficiently learn dominant path losses from sparse training data and generalizes well when tested on novel maps.
One-bit mmWave MIMO Channel Estimation using Deep Generative Networks
Nov 16, 2022


As future wireless systems trend towards higher carrier frequencies and large antenna arrays, receivers with one-bit analog-to-digital converters (ADCs) are being explored owing to their reduced power consumption. However, the combination of large antenna arrays and one-bit ADCs makes channel estimation challenging. In this paper, we formulate channel estimation from a limited number of one-bit quantized pilot measurements as an inverse problem and reconstruct the channel by optimizing the input vector of a pre-trained deep generative model with the objective of maximizing a novel correlation-based loss function. We observe that deep generative priors adapted to the underlying channel model significantly outperform Bernoulli-Gaussian Approximate Message Passing (BG-GAMP), while a single generative model that uses a conditional input to distinguish between Line-of-Sight (LOS) and Non-Line-of-Sight (NLOS) channel realizations outperforms BG-GAMP on LOS channels and achieves comparable performance on NLOS channels in terms of the normalized channel reconstruction error.
Over-the-Air Design of GAN Training for mmWave MIMO Channel Estimation
May 25, 2022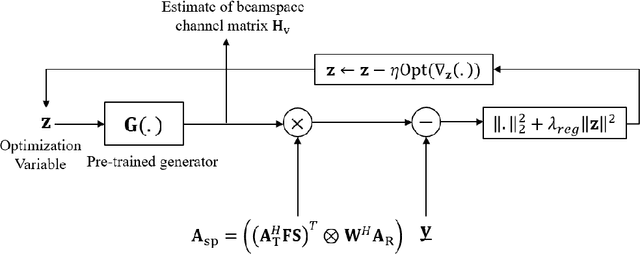
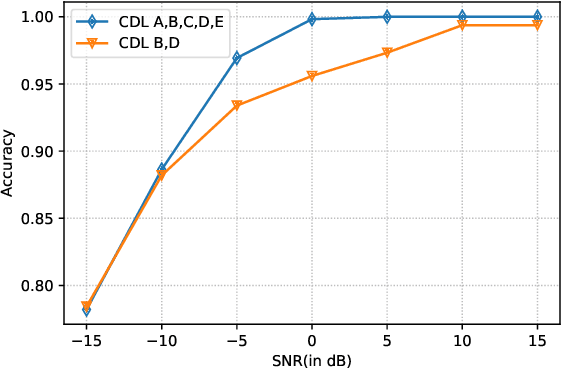
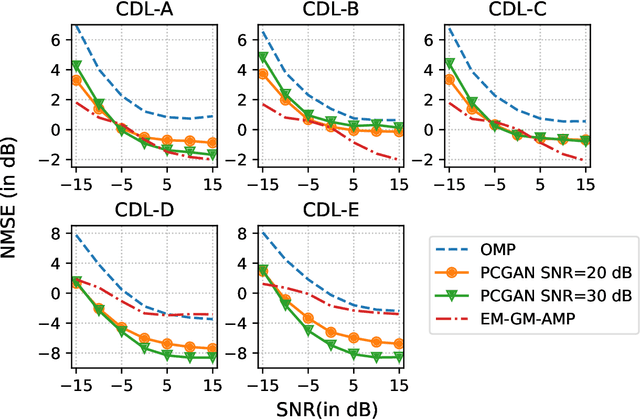
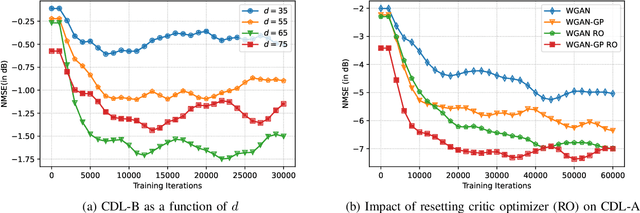
Future wireless systems are trending towards higher carrier frequencies that offer larger communication bandwidth but necessitate the use of large antenna arrays. Existing signal processing techniques for channel estimation do not scale well to this "high-dimensional" regime in terms of performance and pilot overhead. Meanwhile, training deep learning based approaches for channel estimation requires large labeled datasets mapping pilot measurements to clean channel realizations, which can only be generated offline using simulated channels. In this paper, we develop a novel unsupervised over-the-air (OTA) algorithm that utilizes noisy received pilot measurements to train a deep generative model to output beamspace MIMO channel realizations. Our approach leverages Generative Adversarial Networks (GAN), while using a conditional input to distinguish between Line-of-Sight (LOS) and Non-Line-of-Sight (NLOS) channel realizations. We also present a federated implementation of the OTA algorithm that distributes the GAN training over multiple users and greatly reduces the user side computation. We then formulate channel estimation from a limited number of pilot measurements as an inverse problem and reconstruct the channel by optimizing the input vector of the trained generative model. Our proposed approach significantly outperforms Orthogonal Matching Pursuit on both LOS and NLOS channel models, and EM-GM-AMP -- an Approximate Message Passing algorithm -- on LOS channel models, while achieving comparable performance on NLOS channel models in terms of the normalized channel reconstruction error. More importantly, our proposed framework has the potential to be trained online using real noisy pilot measurements, is not restricted to a specific channel model and can even be utilized for a federated OTA design of a dataset generator from noisy data.
A Deep Reinforcement Learning Framework for Contention-Based Spectrum Sharing
Oct 05, 2021
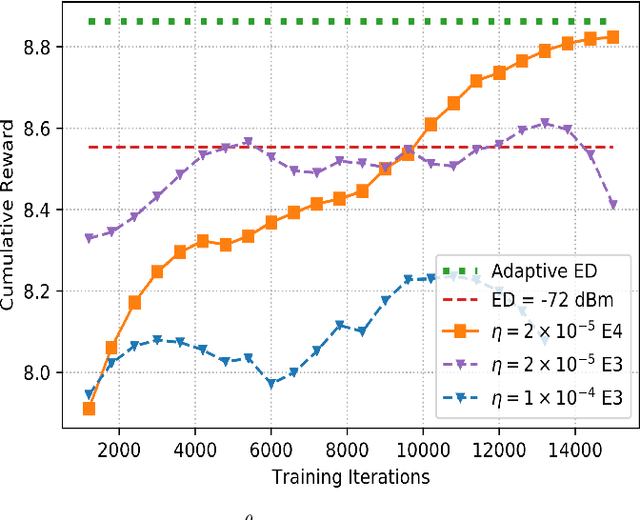
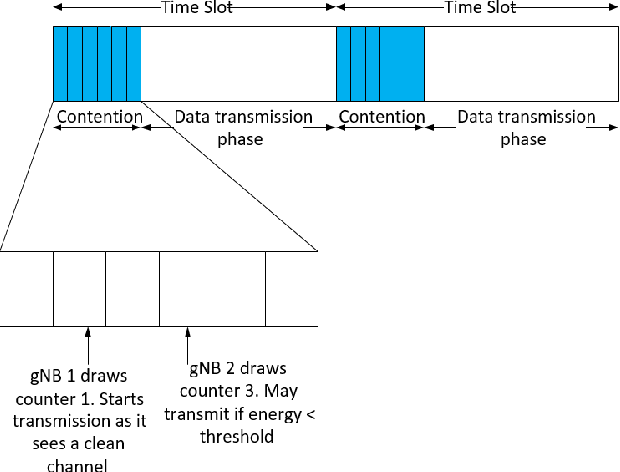
The increasing number of wireless devices operating in unlicensed spectrum motivates the development of intelligent adaptive approaches to spectrum access. We consider decentralized contention-based medium access for base stations (BSs) operating on unlicensed shared spectrum, where each BS autonomously decides whether or not to transmit on a given resource. The contention decision attempts to maximize not its own downlink throughput, but rather a network-wide objective. We formulate this problem as a decentralized partially observable Markov decision process with a novel reward structure that provides long term proportional fairness in terms of throughput. We then introduce a two-stage Markov decision process in each time slot that uses information from spectrum sensing and reception quality to make a medium access decision. Finally, we incorporate these features into a distributed reinforcement learning framework for contention-based spectrum access. Our formulation provides decentralized inference, online adaptability and also caters to partial observability of the environment through recurrent Q-learning. Empirically, we find its maximization of the proportional fairness metric to be competitive with a genie-aided adaptive energy detection threshold, while being robust to channel fading and small contention windows.
* 14 pages, 11 figures, 4 tables
Distributed Deep Reinforcement Learning for Adaptive Medium Access and Modulation in Shared Spectrum
Sep 24, 2021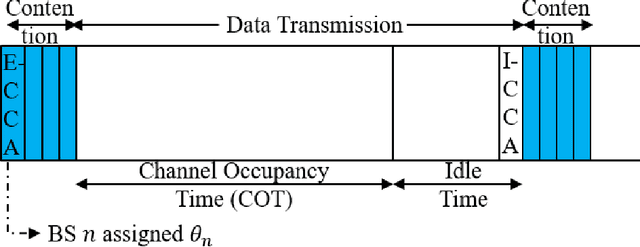
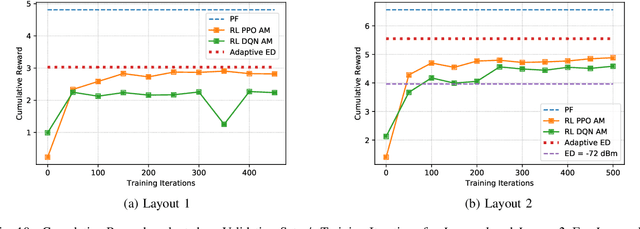
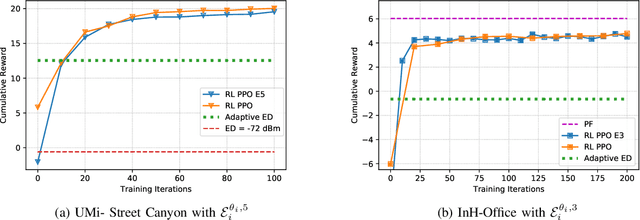

Spectrum scarcity has led to growth in the use of unlicensed spectrum for cellular systems. This motivates intelligent adaptive approaches to spectrum access for both WiFi and 5G that improve upon traditional carrier sensing and listen-before-talk methods. We study decentralized contention-based medium access for base stations (BSs) of a single Radio Access Technology (RAT) operating on unlicensed shared spectrum. We devise a learning-based algorithm for both contention and adaptive modulation that attempts to maximize a network-wide downlink throughput objective. We formulate and develop novel distributed implementations of two deep reinforcement learning approaches - Deep Q Networks and Proximal Policy Optimization - modelled on a two stage Markov decision process. Empirically, we find the (proportional fairness) reward accumulated by the policy gradient approach to be significantly higher than even a genie-aided adaptive energy detection threshold. Our approaches are further validated by improved sum and peak throughput. The scalability of our approach to large networks is demonstrated via an improved cumulative reward earned on both indoor and outdoor layouts with a large number of BSs.
DeepWiPHY: Deep Learning-based Receiver Design and Dataset for IEEE 802.11ax Systems
Oct 19, 2020
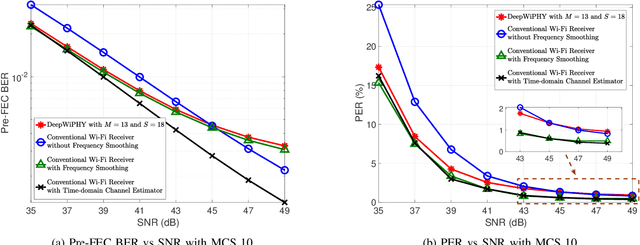
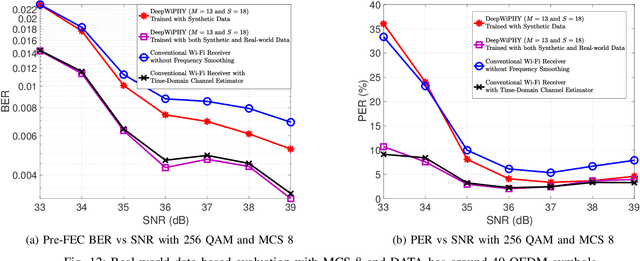
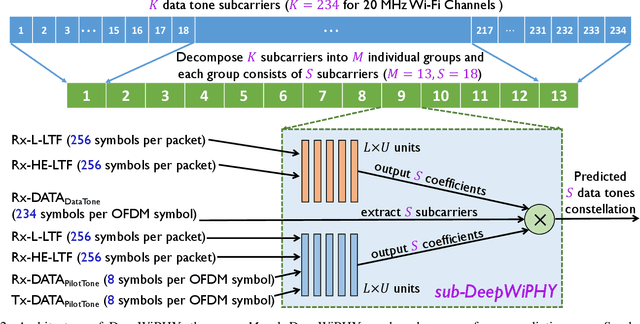
In this work, we develop DeepWiPHY, a deep learning-based architecture to replace the channel estimation, common phase error (CPE) correction, sampling rate offset (SRO) correction, and equalization modules of IEEE 802.11ax based orthogonal frequency division multiplexing (OFDM) receivers. We first train DeepWiPHY with a synthetic dataset, which is generated using representative indoor channel models and includes typical radio frequency (RF) impairments that are the source of nonlinearity in wireless systems. To further train and evaluate DeepWiPHY with real-world data, we develop a passive sniffing-based data collection testbed composed of Universal Software Radio Peripherals (USRPs) and commercially available IEEE 802.11ax products. The comprehensive evaluation of DeepWiPHY with synthetic and real-world datasets (110 million synthetic OFDM symbols and 14 million real-world OFDM symbols) confirms that, even without fine-tuning the neural network's architecture parameters, DeepWiPHY achieves comparable performance to or outperforms the conventional WLAN receivers, in terms of both bit error rate (BER) and packet error rate (PER), under a wide range of channel models, signal-to-noise (SNR) levels, and modulation schemes.
Deep Stock Predictions
Jun 08, 2020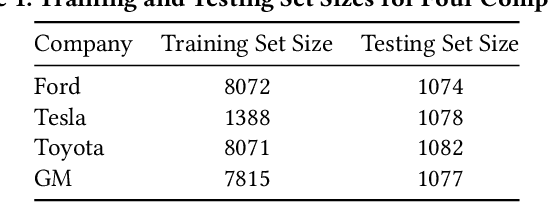
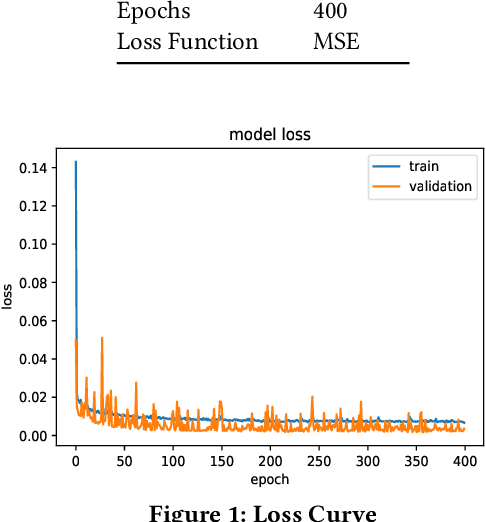


Forecasting stock prices can be interpreted as a time series prediction problem, for which Long Short Term Memory (LSTM) neural networks are often used due to their architecture specifically built to solve such problems. In this paper, we consider the design of a trading strategy that performs portfolio optimization using the LSTM stock price prediction for four different companies. We then customize the loss function used to train the LSTM to increase the profit earned. Moreover, we propose a data driven approach for optimal selection of window length and multi-step prediction length, and consider the addition of analyst calls as technical indicators to a multi-stack Bidirectional LSTM strengthened by the addition of Attention units. We find the LSTM model with the customized loss function to have an improved performance in the training bot over a regressive baseline such as ARIMA, while the addition of analyst call does improve the performance for certain datasets.