 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnfolding Projection-free SDP Relaxation of Binary Graph Classifier via GDPA Linearization
Sep 10, 2021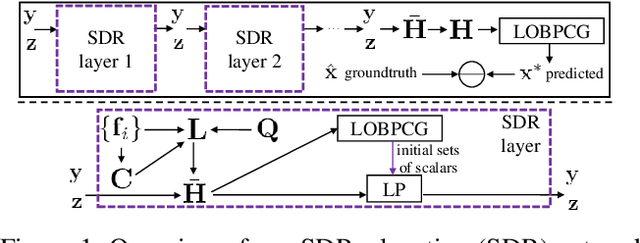
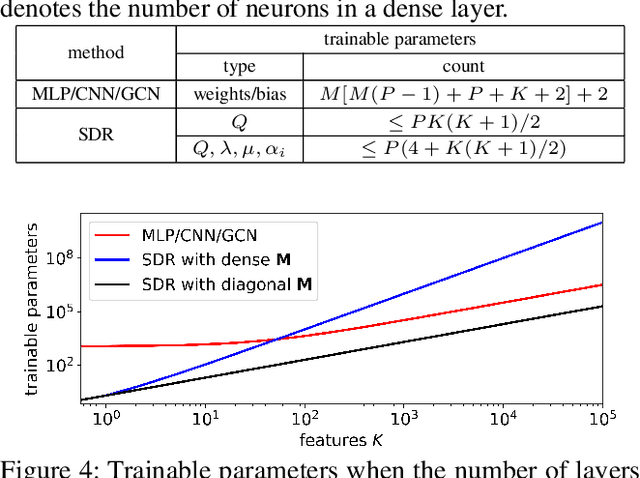
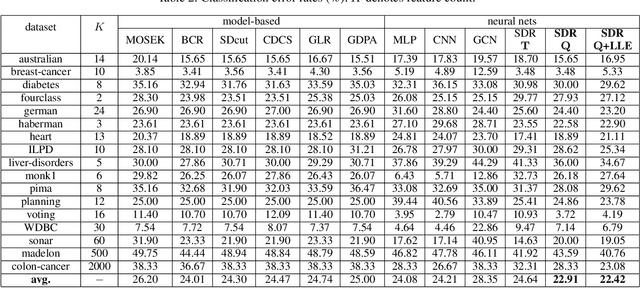
Algorithm unfolding creates an interpretable and parsimonious neural network architecture by implementing each iteration of a model-based algorithm as a neural layer. However, unfolding a proximal splitting algorithm with a positive semi-definite (PSD) cone projection operator per iteration is expensive, due to the required full matrix eigen-decomposition. In this paper, leveraging a recent linear algebraic theorem called Gershgorin disc perfect alignment (GDPA), we unroll a projection-free algorithm for semi-definite programming relaxation (SDR) of a binary graph classifier, where the PSD cone constraint is replaced by a set of "tightest possible" linear constraints per iteration. As a result, each iteration only requires computing a linear program (LP) and one extreme eigenvector. Inside the unrolled network, we optimize parameters via stochastic gradient descent (SGD) that determine graph edge weights in two ways: i) a metric matrix that computes feature distances, and ii) a sparse weight matrix computed via local linear embedding (LLE). Experimental results show that our unrolled network outperformed pure model-based graph classifiers, and achieved comparable performance to pure data-driven networks but using far fewer parameters.
Projection-free Graph-based Classifier Learning using Gershgorin Disc Perfect Alignment
Jun 03, 2021

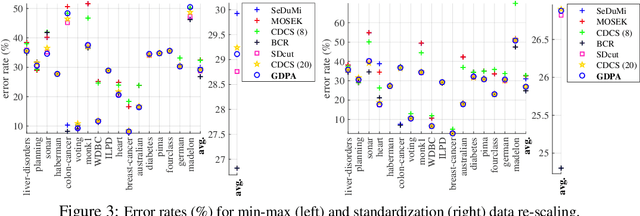
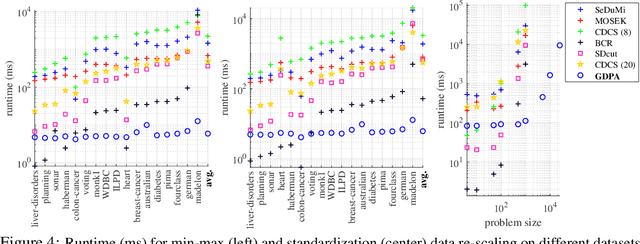
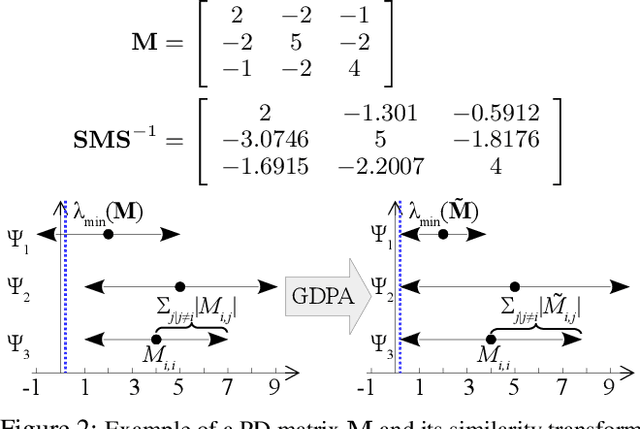
In semi-supervised graph-based binary classifier learning, a subset of known labels $\hat{x}_i$ are used to infer unknown labels, assuming that the label signal $x$ is smooth with respect to a similarity graph specified by a Laplacian matrix. When restricting labels $x_i$ to binary values, the problem is NP-hard. While a conventional semi-definite programming (SDP) relaxation can be solved in polynomial time using, for example, the alternating direction method of multipliers (ADMM), the complexity of iteratively projecting a candidate matrix $M$ onto the positive semi-definite (PSD) cone ($M \succeq 0$) remains high. In this paper, leveraging a recent linear algebraic theory called Gershgorin disc perfect alignment (GDPA), we propose a fast projection-free method by solving a sequence of linear programs (LP) instead. Specifically, we first recast the SDP relaxation to its SDP dual, where a feasible solution $H \succeq 0$ can be interpreted as a Laplacian matrix corresponding to a balanced signed graph sans the last node. To achieve graph balance, we split the last node into two that respectively contain the original positive and negative edges, resulting in a new Laplacian $\bar{H}$. We repose the SDP dual for solution $\bar{H}$, then replace the PSD cone constraint $\bar{H} \succeq 0$ with linear constraints derived from GDPA -- sufficient conditions to ensure $\bar{H}$ is PSD -- so that the optimization becomes an LP per iteration. Finally, we extract predicted labels from our converged LP solution $\bar{H}$. Experiments show that our algorithm enjoyed a $40\times$ speedup on average over the next fastest scheme while retaining comparable label prediction performance.
DeepWiPHY: Deep Learning-based Receiver Design and Dataset for IEEE 802.11ax Systems
Oct 19, 2020
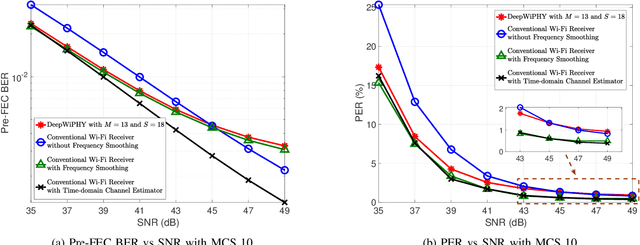
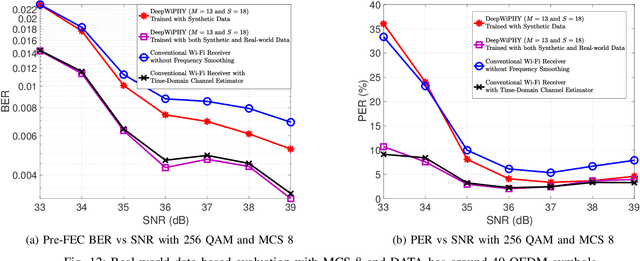
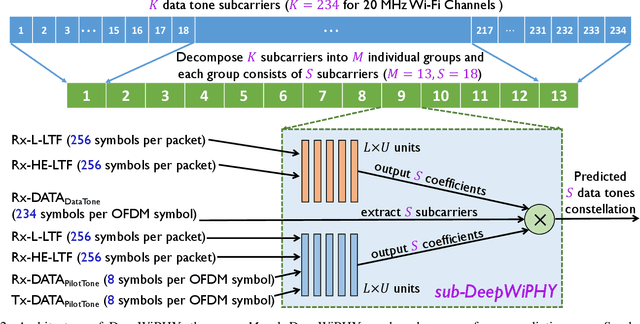
In this work, we develop DeepWiPHY, a deep learning-based architecture to replace the channel estimation, common phase error (CPE) correction, sampling rate offset (SRO) correction, and equalization modules of IEEE 802.11ax based orthogonal frequency division multiplexing (OFDM) receivers. We first train DeepWiPHY with a synthetic dataset, which is generated using representative indoor channel models and includes typical radio frequency (RF) impairments that are the source of nonlinearity in wireless systems. To further train and evaluate DeepWiPHY with real-world data, we develop a passive sniffing-based data collection testbed composed of Universal Software Radio Peripherals (USRPs) and commercially available IEEE 802.11ax products. The comprehensive evaluation of DeepWiPHY with synthetic and real-world datasets (110 million synthetic OFDM symbols and 14 million real-world OFDM symbols) confirms that, even without fine-tuning the neural network's architecture parameters, DeepWiPHY achieves comparable performance to or outperforms the conventional WLAN receivers, in terms of both bit error rate (BER) and packet error rate (PER), under a wide range of channel models, signal-to-noise (SNR) levels, and modulation schemes.