 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance Data Condensation for Image Super-Resolution
May 27, 2025
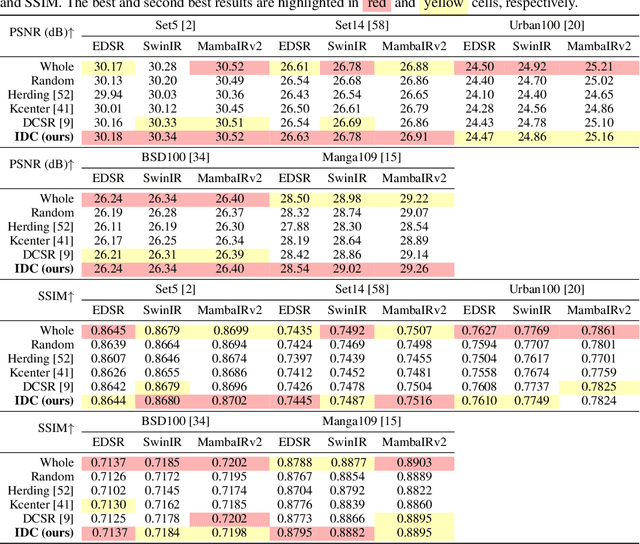
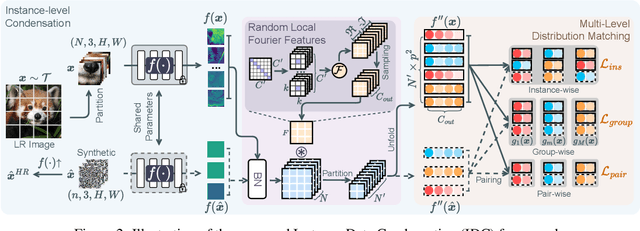
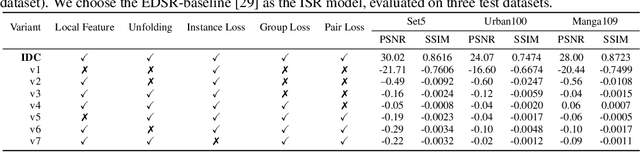
Deep learning based image Super-Resolution (ISR) relies on large training datasets to optimize model generalization; this requires substantial computational and storage resources during training. While dataset condensation has shown potential in improving data efficiency and privacy for high-level computer vision tasks, it has not yet been fully exploited for ISR. In this paper, we propose a novel Instance Data Condensation (IDC) framework specifically for ISR, which achieves instance-level data condensation through Random Local Fourier Feature Extraction and Multi-level Feature Distribution Matching. This aims to optimize feature distributions at both global and local levels and obtain high-quality synthesized training content with fine detail. This framework has been utilized to condense the most commonly used training dataset for ISR, DIV2K, with a 10% condensation rate. The resulting synthetic dataset offers comparable or (in certain cases) even better performance compared to the original full dataset and excellent training stability when used to train various popular ISR models. To the best of our knowledge, this is the first time that a condensed/synthetic dataset (with a 10% data volume) has demonstrated such performance. The source code and the synthetic dataset have been made available at https://github.com/.
HIIF: Hierarchical Encoding based Implicit Image Function for Continuous Super-resolution
Dec 04, 2024



Recent advances in implicit neural representations (INRs) have shown significant promise in modeling visual signals for various low-vision tasks including image super-resolution (ISR). INR-based ISR methods typically learn continuous representations, providing flexibility for generating high-resolution images at any desired scale from their low-resolution counterparts. However, existing INR-based ISR methods utilize multi-layer perceptrons for parameterization in the network; this does not take account of the hierarchical structure existing in local sampling points and hence constrains the representation capability. In this paper, we propose a new \textbf{H}ierarchical encoding based \textbf{I}mplicit \textbf{I}mage \textbf{F}unction for continuous image super-resolution, \textbf{HIIF}, which leverages a novel hierarchical positional encoding that enhances the local implicit representation, enabling it to capture fine details at multiple scales. Our approach also embeds a multi-head linear attention mechanism within the implicit attention network by taking additional non-local information into account. Our experiments show that, when integrated with different backbone encoders, HIIF outperforms the state-of-the-art continuous image super-resolution methods by up to 0.17dB in PSNR. The source code of HIIF will be made publicly available at \url{www.github.com}.
BVI-CR: A Multi-View Human Dataset for Volumetric Video Compression
Nov 17, 2024



The advances in immersive technologies and 3D reconstruction have enabled the creation of digital replicas of real-world objects and environments with fine details. These processes generate vast amounts of 3D data, requiring more efficient compression methods to satisfy the memory and bandwidth constraints associated with data storage and transmission. However, the development and validation of efficient 3D data compression methods are constrained by the lack of comprehensive and high-quality volumetric video datasets, which typically require much more effort to acquire and consume increased resources compared to 2D image and video databases. To bridge this gap, we present an open multi-view volumetric human dataset, denoted BVI-CR, which contains 18 multi-view RGB-D captures and their corresponding textured polygonal meshes, depicting a range of diverse human actions. Each video sequence contains 10 views in 1080p resolution with durations between 10-15 seconds at 30FPS. Using BVI-CR, we benchmarked three conventional and neural coordinate-based multi-view video compression methods, following the MPEG MIV Common Test Conditions, and reported their rate quality performance based on various quality metrics. The results show the great potential of neural representation based methods in volumetric video compression compared to conventional video coding methods (with an up to 38\% average coding gain in PSNR). This dataset provides a development and validation platform for a variety of tasks including volumetric reconstruction, compression, and quality assessment. The database will be shared publicly at \url{https://github.com/fan-aaron-zhang/bvi-cr}.
NVRC: Neural Video Representation Compression
Sep 11, 2024Recent advances in implicit neural representation (INR)-based video coding have demonstrated its potential to compete with both conventional and other learning-based approaches. With INR methods, a neural network is trained to overfit a video sequence, with its parameters compressed to obtain a compact representation of the video content. However, although promising results have been achieved, the best INR-based methods are still out-performed by the latest standard codecs, such as VVC VTM, partially due to the simple model compression techniques employed. In this paper, rather than focusing on representation architectures as in many existing works, we propose a novel INR-based video compression framework, Neural Video Representation Compression (NVRC), targeting compression of the representation. Based on the novel entropy coding and quantization models proposed, NVRC, for the first time, is able to optimize an INR-based video codec in a fully end-to-end manner. To further minimize the additional bitrate overhead introduced by the entropy models, we have also proposed a new model compression framework for coding all the network, quantization and entropy model parameters hierarchically. Our experiments show that NVRC outperforms many conventional and learning-based benchmark codecs, with a 24% average coding gain over VVC VTM (Random Access) on the UVG dataset, measured in PSNR. As far as we are aware, this is the first time an INR-based video codec achieving such performance. The implementation of NVRC will be released at www.github.com.
PNVC: Towards Practical INR-based Video Compression
Sep 02, 2024
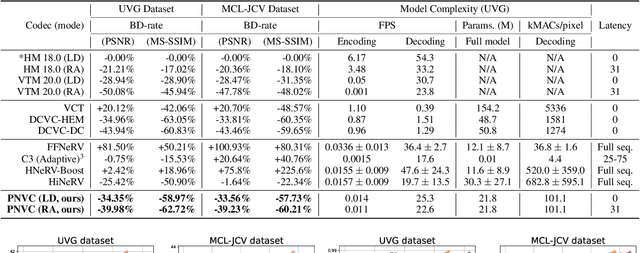

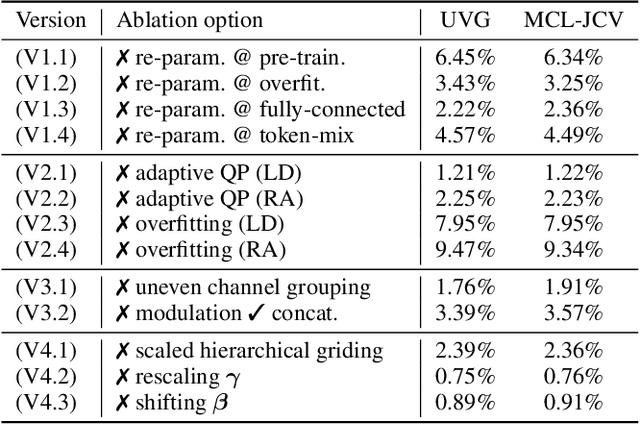
Neural video compression has recently demonstrated significant potential to compete with conventional video codecs in terms of rate-quality performance. These learned video codecs are however associated with various issues related to decoding complexity (for autoencoder-based methods) and/or system delays (for implicit neural representation (INR) based models), which currently prevent them from being deployed in practical applications. In this paper, targeting a practical neural video codec, we propose a novel INR-based coding framework, PNVC, which innovatively combines autoencoder-based and overfitted solutions. Our approach benefits from several design innovations, including a new structural reparameterization-based architecture, hierarchical quality control, modulation-based entropy modeling, and scale-aware positional embedding. Supporting both low delay (LD) and random access (RA) configurations, PNVC outperforms existing INR-based codecs, achieving nearly 35%+ BD-rate savings against HEVC HM 18.0 (LD) - almost 10% more compared to one of the state-of-the-art INR-based codecs, HiNeRV and 5% more over VTM 20.0 (LD), while maintaining 20+ FPS decoding speeds for 1080p content. This represents an important step forward for INR-based video coding, moving it towards practical deployment. The source code will be available for public evaluation.
Immersive Video Compression using Implicit Neural Representations
Feb 02, 2024Recent work on implicit neural representations (INRs) has evidenced their potential for efficiently representing and encoding conventional video content. In this paper we, for the first time, extend their application to immersive (multi-view) videos, by proposing MV-HiNeRV, a new INR-based immersive video codec. MV-HiNeRV is an enhanced version of a state-of-the-art INR-based video codec, HiNeRV, which was developed for single-view video compression. We have modified the model to learn a different group of feature grids for each view, and share the learnt network parameters among all views. This enables the model to effectively exploit the spatio-temporal and the inter-view redundancy that exists within multi-view videos. The proposed codec was used to compress multi-view texture and depth video sequences in the MPEG Immersive Video (MIV) Common Test Conditions, and tested against the MIV Test model (TMIV) that uses the VVenC video codec. The results demonstrate the superior performance of MV-HiNeRV, with significant coding gains (up to 72.33%) over TMIV. The implementation of MV-HiNeRV will be published for further development and evaluation.
FedSDD: Scalable and Diversity-enhanced Distillation for Model Aggregation in Federated Learning
Dec 28, 2023Recently, innovative model aggregation methods based on knowledge distillation (KD) have been proposed for federated learning (FL). These methods not only improved the robustness of model aggregation over heterogeneous learning environment, but also allowed training heterogeneous models on client devices. However, the scalability of existing methods is not satisfactory, because the training cost on the server increases with the number of clients, which limits their application in large scale systems. Furthermore, the ensemble of existing methods is built from a set of client models initialized from the same checkpoint, causing low diversity. In this paper, we propose a scalable and diversity-enhanced federated distillation scheme, FedSDD, which decouples the training complexity from the number of clients to enhance the scalability, and builds the ensemble from a set of aggregated models with enhanced diversity. In particular, the teacher model in FedSDD is an ensemble built by a small group of aggregated (global) models, instead of all client models, such that the computation cost will not scale with the number of clients. Furthermore, to enhance diversity, FedSDD only performs KD to enhance one of the global models, i.e., the \textit{main global model}, which improves the performance of both the ensemble and the main global model. While partitioning client model into more groups allow building an ensemble with more aggregated models, the convergence of individual aggregated models will be slow down. We introduce the temporal ensembling which leverage the issues, and provide significant improvement with the heterogeneous settings. Experiment results show that FedSDD outperforms other FL methods, including FedAvg and FedDF, on the benchmark datasets.
HiNeRV: Video Compression with Hierarchical Encoding based Neural Representation
Jun 16, 2023



Learning-based video compression is currently one of the most popular research topics, offering the potential to compete with conventional standard video codecs. In this context, Implicit Neural Representations (INRs) have previously been used to represent and compress image and video content, demonstrating relatively high decoding speed compared to other methods. However, existing INR-based methods have failed to deliver rate quality performance comparable with the state of the art in video compression. This is mainly due to the simplicity of the employed network architectures, which limit their representation capability. In this paper, we propose HiNeRV, an INR that combines bilinear interpolation with novel hierarchical positional encoding. This structure employs depth-wise convolutional and MLP layers to build a deep and wide network architecture with much higher capacity. We further build a video codec based on HiNeRV and a refined pipeline for training, pruning and quantization that can better preserve HiNeRV's performance during lossy model compression. The proposed method has been evaluated on both UVG and MCL-JCV datasets for video compression, demonstrating significant improvement over all existing INRs baselines and competitive performance when compared to learning-based codecs (72.3% overall bit rate saving over HNeRV and 43.4% over DCVC on the UVG dataset, measured in PSNR).
SSBNet: Improving Visual Recognition Efficiency by Adaptive Sampling
Jul 23, 2022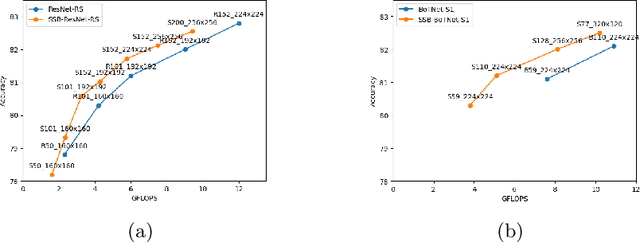
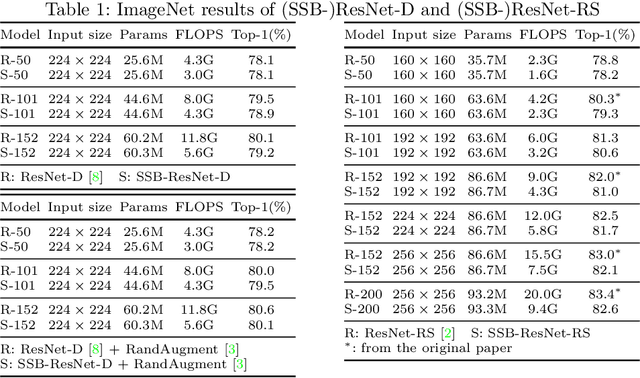
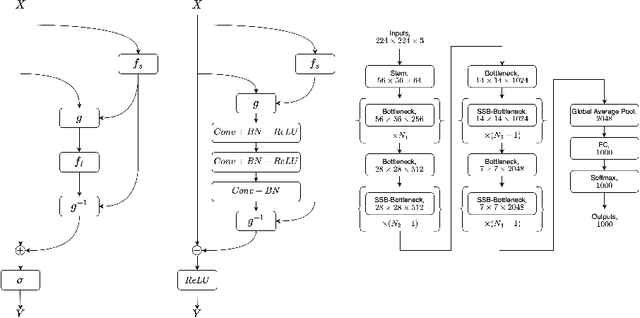
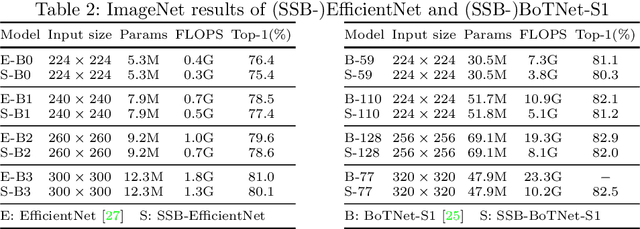
Downsampling is widely adopted to achieve a good trade-off between accuracy and latency for visual recognition. Unfortunately, the commonly used pooling layers are not learned, and thus cannot preserve important information. As another dimension reduction method, adaptive sampling weights and processes regions that are relevant to the task, and is thus able to better preserve useful information. However, the use of adaptive sampling has been limited to certain layers. In this paper, we show that using adaptive sampling in the building blocks of a deep neural network can improve its efficiency. In particular, we propose SSBNet which is built by inserting sampling layers repeatedly into existing networks like ResNet. Experiment results show that the proposed SSBNet can achieve competitive image classification and object detection performance on ImageNet and COCO datasets. For example, the SSB-ResNet-RS-200 achieved 82.6% accuracy on ImageNet dataset, which is 0.6% higher than the baseline ResNet-RS-152 with a similar complexity. Visualization shows the advantage of SSBNet in allowing different layers to focus on different positions, and ablation studies further validate the advantage of adaptive sampling over uniform methods.