 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBVI-CR: A Multi-View Human Dataset for Volumetric Video Compression
Nov 17, 2024



The advances in immersive technologies and 3D reconstruction have enabled the creation of digital replicas of real-world objects and environments with fine details. These processes generate vast amounts of 3D data, requiring more efficient compression methods to satisfy the memory and bandwidth constraints associated with data storage and transmission. However, the development and validation of efficient 3D data compression methods are constrained by the lack of comprehensive and high-quality volumetric video datasets, which typically require much more effort to acquire and consume increased resources compared to 2D image and video databases. To bridge this gap, we present an open multi-view volumetric human dataset, denoted BVI-CR, which contains 18 multi-view RGB-D captures and their corresponding textured polygonal meshes, depicting a range of diverse human actions. Each video sequence contains 10 views in 1080p resolution with durations between 10-15 seconds at 30FPS. Using BVI-CR, we benchmarked three conventional and neural coordinate-based multi-view video compression methods, following the MPEG MIV Common Test Conditions, and reported their rate quality performance based on various quality metrics. The results show the great potential of neural representation based methods in volumetric video compression compared to conventional video coding methods (with an up to 38\% average coding gain in PSNR). This dataset provides a development and validation platform for a variety of tasks including volumetric reconstruction, compression, and quality assessment. The database will be shared publicly at \url{https://github.com/fan-aaron-zhang/bvi-cr}.
Simultaneous drone localisation and wind turbine model fitting during autonomous surface inspection
Apr 09, 2019
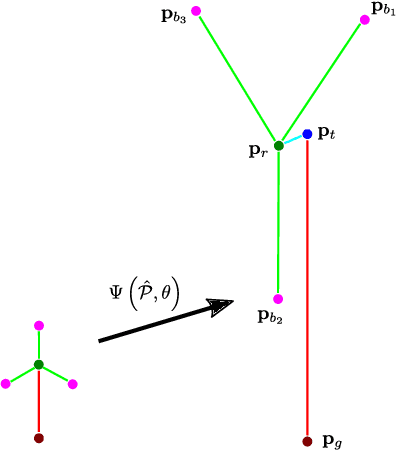

We present a method for simultaneous localisation and wind turbine model fitting for a drone performing an automated surface inspection. We use a skeletal parameterisation of the turbine that can be easily integrated into a non-linear least squares optimiser, combined with a pose graph representation of the drone's 3-D trajectory, allowing us to optimise both sets of parameters simultaneously. Given images from an onboard camera, we use a CNN to infer projections of the skeletal model, enabling correspondence constraints to be established through a cost function. This is then coupled with GPS/IMU measurements taken at key frames in the graph to allow successive optimisation as the drone navigates around the turbine. We present two variants of the cost function, one based on traditional 2D point correspondences and the other on direct image interpolation within the inferred projections. Results from experiments on simulated and real-world data show that simultaneous optimisation provides improvements to localisation over only optimising the pose and that combined use of both cost functions proves most effective.
Improving drone localisation around wind turbines using monocular model-based tracking
Feb 27, 2019
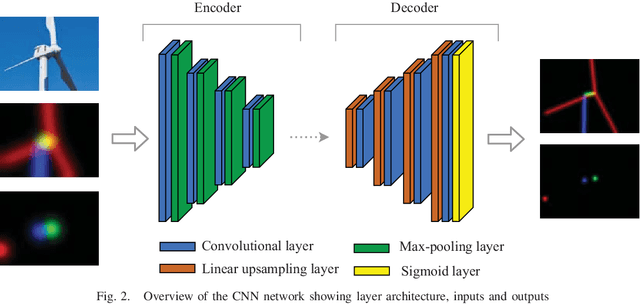
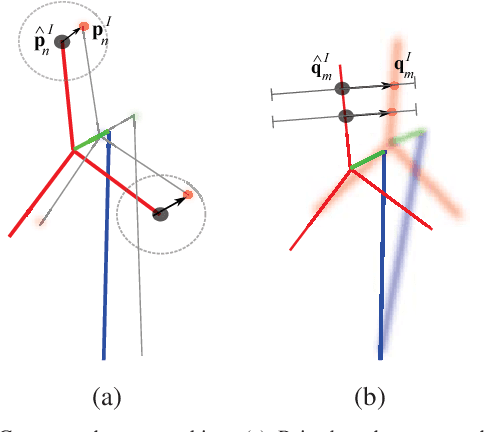

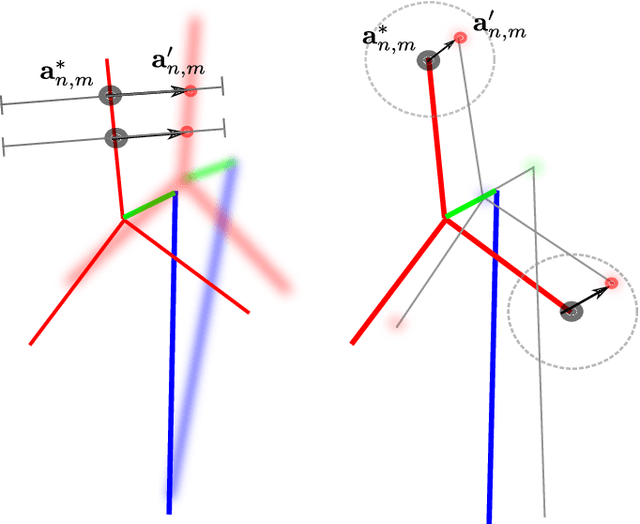
We present a novel method of integrating image-based measurements into a drone navigation system for the automated inspection of wind turbines. We take a model-based tracking approach, where a 3D skeleton representation of the turbine is matched to the image data. Matching is based on comparing the projection of the representation to that inferred from images using a convolutional neural network. This enables us to find image correspondences using a generic turbine model that can be applied to a wide range of turbine shapes and sizes. To estimate 3D pose of the drone, we fuse the network output with GPS and IMU measurements using a pose graph optimiser. Results illustrate that the use of the image measurements significantly improves the accuracy of the localisation over that obtained using GPS and IMU alone.
Predicting Out-of-View Feature Points for Model-Based Camera Pose Estimation
Mar 05, 2018
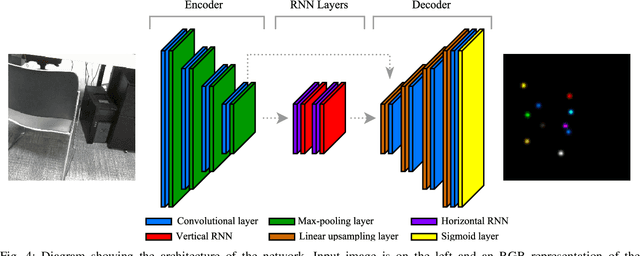
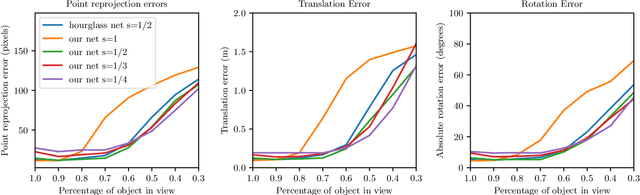

In this work we present a novel framework that uses deep learning to predict object feature points that are out-of-view in the input image. This system was developed with the application of model-based tracking in mind, particularly in the case of autonomous inspection robots, where only partial views of the object are available. Out-of-view prediction is enabled by applying scaling to the feature point labels during network training. This is combined with a recurrent neural network architecture designed to provide the final prediction layers with rich feature information from across the spatial extent of the input image. To show the versatility of these out-of-view predictions, we describe how to integrate them in both a particle filter tracker and an optimisation based tracker. To evaluate our work we compared our framework with one that predicts only points inside the image. We show that as the amount of the object in view decreases, being able to predict outside the image bounds adds robustness to the final pose estimation.