 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiDF-SLAM: End-to-End RGB-D SLAM with Neural Implicit Mapping and Deep Feature Tracking
Sep 16, 2022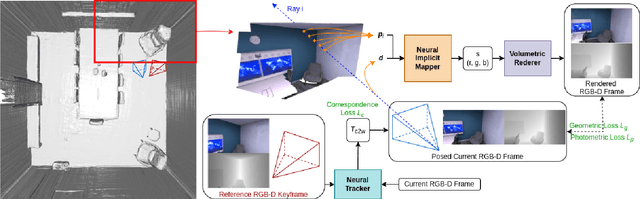
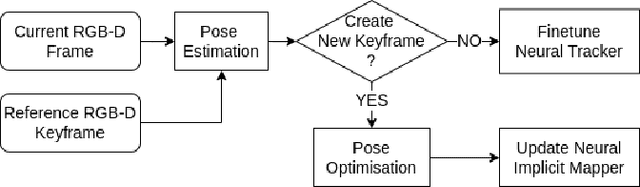
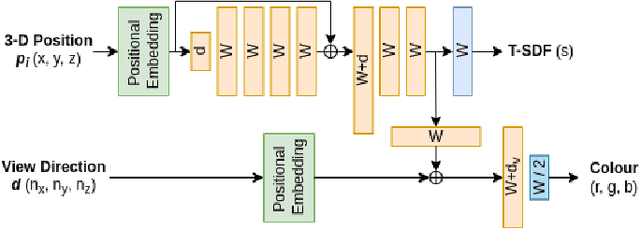
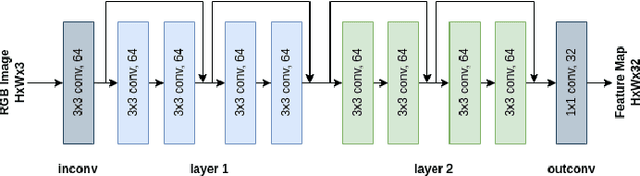
We propose a novel end-to-end RGB-D SLAM, iDF-SLAM, which adopts a feature-based deep neural tracker as the front-end and a NeRF-style neural implicit mapper as the back-end. The neural implicit mapper is trained on-the-fly, while though the neural tracker is pretrained on the ScanNet dataset, it is also finetuned along with the training of the neural implicit mapper. Under such a design, our iDF-SLAM is capable of learning to use scene-specific features for camera tracking, thus enabling lifelong learning of the SLAM system. Both the training for the tracker and the mapper are self-supervised without introducing ground truth poses. We test the performance of our iDF-SLAM on the Replica and ScanNet datasets and compare the results to the two recent NeRF-based neural SLAM systems. The proposed iDF-SLAM demonstrates state-of-the-art results in terms of scene reconstruction and competitive performance in camera tracking.
Dual-Domain Image Synthesis using Segmentation-Guided GAN
Apr 19, 2022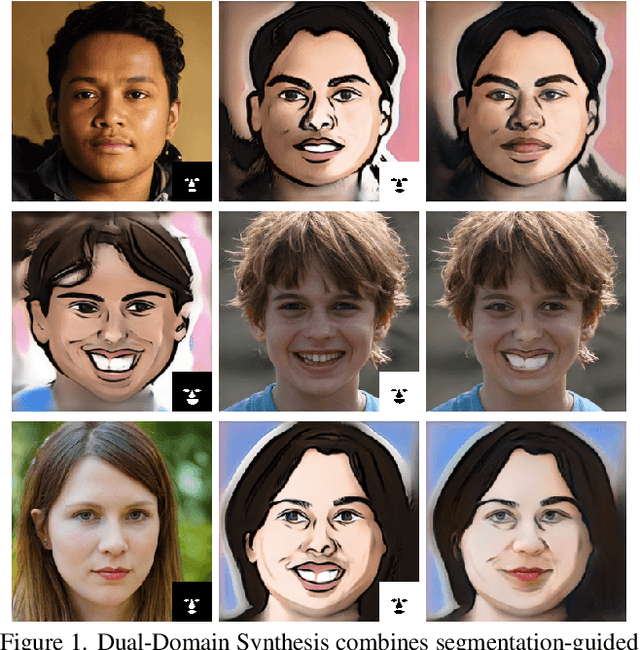
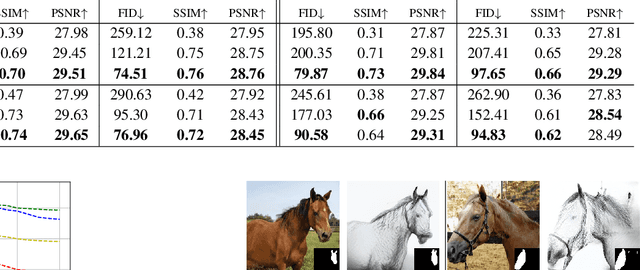
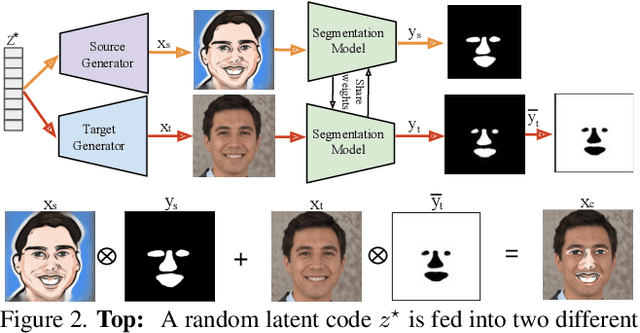
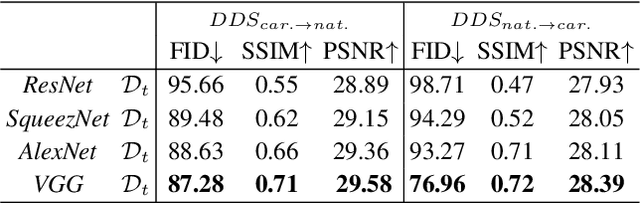
We introduce a segmentation-guided approach to synthesise images that integrate features from two distinct domains. Images synthesised by our dual-domain model belong to one domain within the semantic mask, and to another in the rest of the image - smoothly integrated. We build on the successes of few-shot StyleGAN and single-shot semantic segmentation to minimise the amount of training required in utilising two domains. The method combines a few-shot cross-domain StyleGAN with a latent optimiser to achieve images containing features of two distinct domains. We use a segmentation-guided perceptual loss, which compares both pixel-level and activations between domain-specific and dual-domain synthetic images. Results demonstrate qualitatively and quantitatively that our model is capable of synthesising dual-domain images on a variety of objects (faces, horses, cats, cars), domains (natural, caricature, sketches) and part-based masks (eyes, nose, mouth, hair, car bonnet). The code is publicly available at: https://github.com/denabazazian/Dual-Domain-Synthesis.
FD-SLAM: 3-D Reconstruction Using Features and Dense Matching
Mar 25, 2022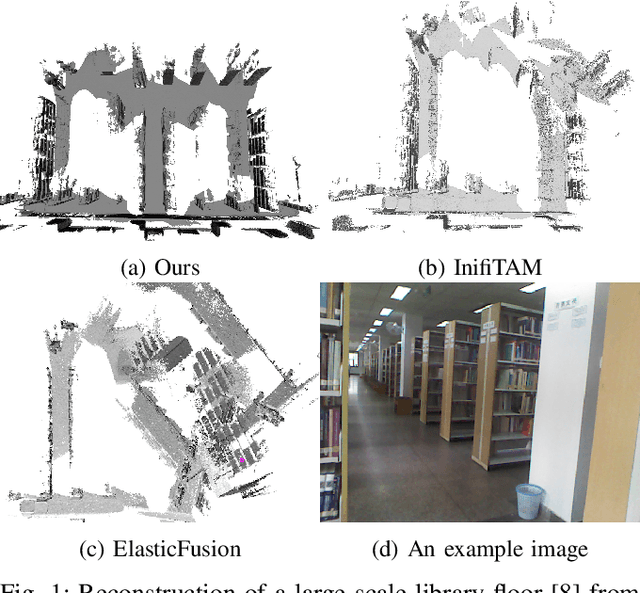
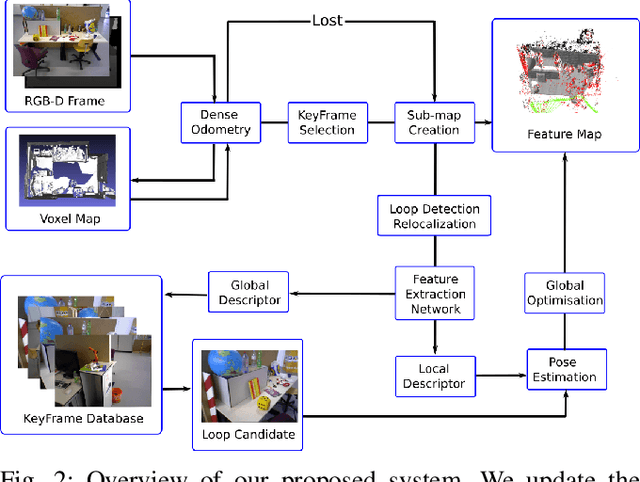

It is well known that visual SLAM systems based on dense matching are locally accurate but are also susceptible to long-term drift and map corruption. In contrast, feature matching methods can achieve greater long-term consistency but can suffer from inaccurate local pose estimation when feature information is sparse. Based on these observations, we propose an RGB-D SLAM system that leverages the advantages of both approaches: using dense frame-to-model odometry to build accurate sub-maps and on-the-fly feature-based matching across sub-maps for global map optimisation. In addition, we incorporate a learning-based loop closure component based on 3-D features which further stabilises map building. We have evaluated the approach on indoor sequences from public datasets, and the results show that it performs on par or better than state-of-the-art systems in terms of map reconstruction quality and pose estimation. The approach can also scale to large scenes where other systems often fail.
CGS-Net: Aggregating Colour, Geometry and Semantic Features for Large-Scale Indoor Place Recognition
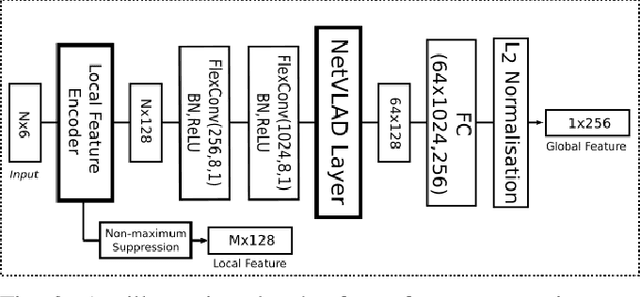
Feb 04, 2022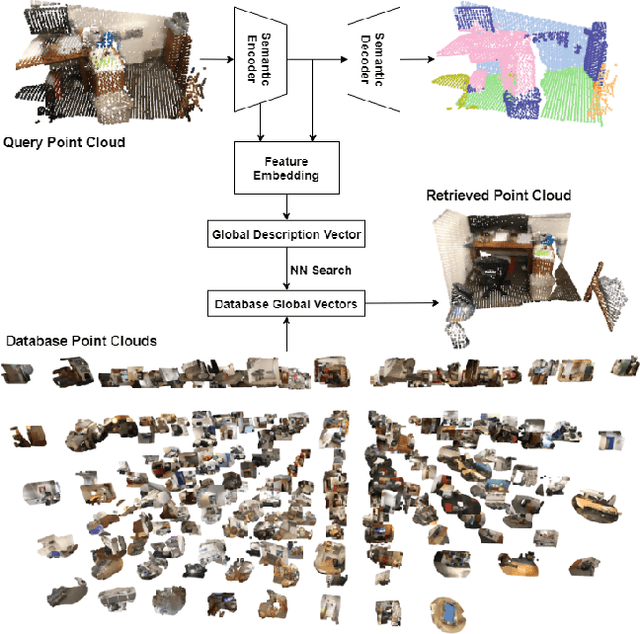
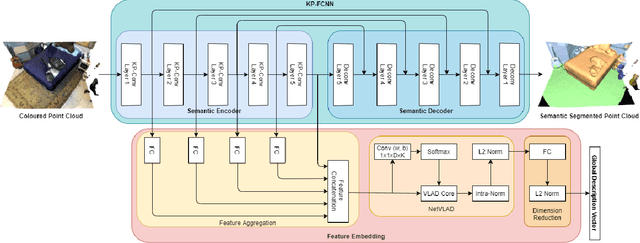


We describe an approach to large-scale indoor place recognition that aggregates low-level colour and geometric features with high-level semantic features. We use a deep learning network that takes in RGB point clouds and extracts local features with five 3-D kernel point convolutional (KPConv) layers. We specifically train the KPConv layers on the semantic segmentation task to ensure that the extracted local features are semantically meaningful. Then, feature maps from all the five KPConv layers are concatenated together and fed into the NetVLAD layer to generate the global descriptors. The approach is trained and evaluated using a large-scale indoor place recognition dataset derived from the ScanNet dataset, with a test set comprising 3,608 point clouds generated from 100 different rooms. Comparison with a traditional feature based method and three state-of-the-art deep learning methods demonstrate that the approach significantly outperforms all four methods, achieving, for example, a top-3 average recall rate of 75% compared with 41% for the closest rival method.
Object-Augmented RGB-D SLAM for Wide-Disparity Relocalisation
Aug 05, 2021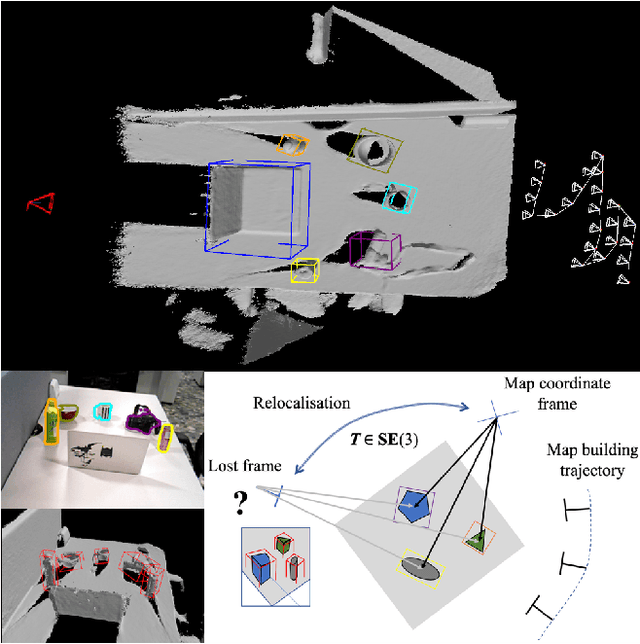
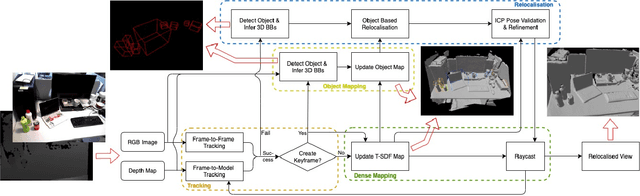
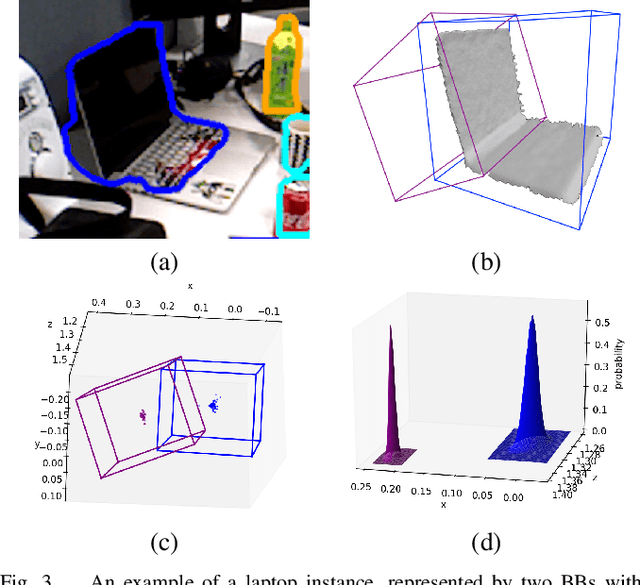

We propose a novel object-augmented RGB-D SLAM system that is capable of constructing a consistent object map and performing relocalisation based on centroids of objects in the map. The approach aims to overcome the view dependence of appearance-based relocalisation methods using point features or images. During the map construction, we use a pre-trained neural network to detect objects and estimate 6D poses from RGB-D data. An incremental probabilistic model is used to aggregate estimates over time to create the object map. Then in relocalisation, we use the same network to extract objects-of-interest in the `lost' frames. Pairwise geometric matching finds correspondences between map and frame objects, and probabilistic absolute orientation followed by application of iterative closest point to dense depth maps and object centroids gives relocalisation. Results of experiments in desktop environments demonstrate very high success rates even for frames with widely different viewpoints from those used to construct the map, significantly outperforming two appearance-based methods.
You Are Here: Geolocation by Embedding Maps and Images
Nov 20, 2019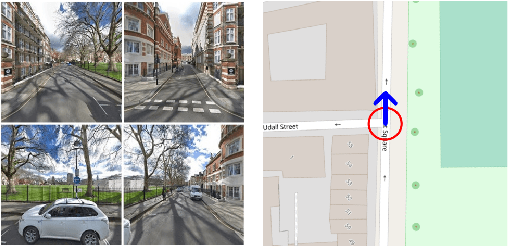
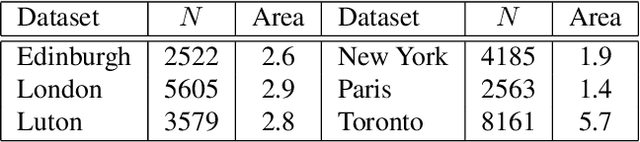
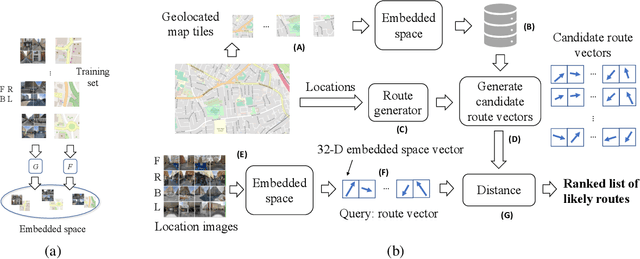
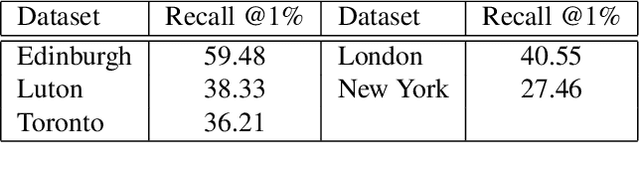
We present a novel approach to geolocating images on a 2-D map based on learning a low dimensional embedded space, which allows a comparison between an image captured at a location and local neighbourhoods of the map. The representation is not sufficiently discriminatory to allow localisation from a single image but when concatenated along a route, localisation converges quickly, with over 90% accuracy being achieved for routes up to 200m in length when using Google Street View and Open Street Map data. The approach generalises a previous fixed semantic feature based approach and achieves faster convergence and higher accuracy without the need for including turn information.
Simultaneous drone localisation and wind turbine model fitting during autonomous surface inspection
Apr 09, 2019
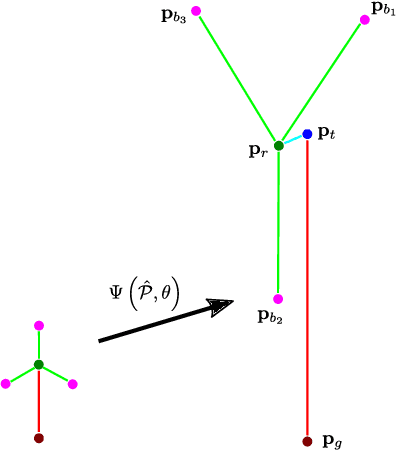

We present a method for simultaneous localisation and wind turbine model fitting for a drone performing an automated surface inspection. We use a skeletal parameterisation of the turbine that can be easily integrated into a non-linear least squares optimiser, combined with a pose graph representation of the drone's 3-D trajectory, allowing us to optimise both sets of parameters simultaneously. Given images from an onboard camera, we use a CNN to infer projections of the skeletal model, enabling correspondence constraints to be established through a cost function. This is then coupled with GPS/IMU measurements taken at key frames in the graph to allow successive optimisation as the drone navigates around the turbine. We present two variants of the cost function, one based on traditional 2D point correspondences and the other on direct image interpolation within the inferred projections. Results from experiments on simulated and real-world data show that simultaneous optimisation provides improvements to localisation over only optimising the pose and that combined use of both cost functions proves most effective.
Improving drone localisation around wind turbines using monocular model-based tracking
Feb 27, 2019
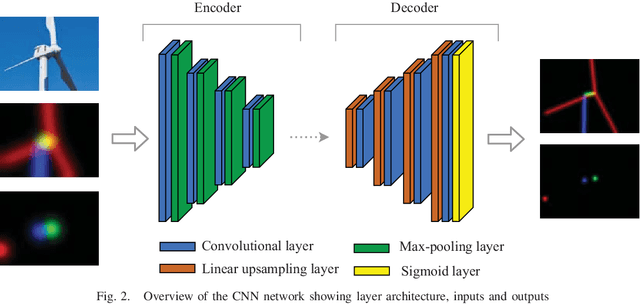
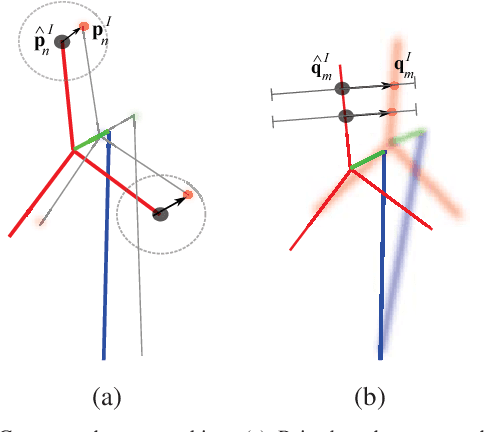

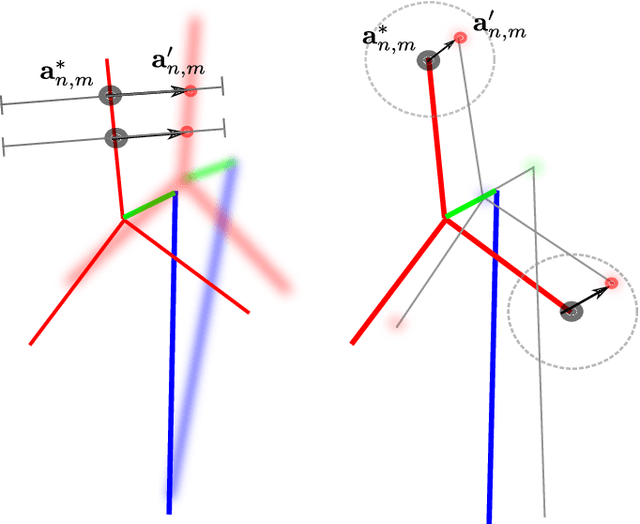
We present a novel method of integrating image-based measurements into a drone navigation system for the automated inspection of wind turbines. We take a model-based tracking approach, where a 3D skeleton representation of the turbine is matched to the image data. Matching is based on comparing the projection of the representation to that inferred from images using a convolutional neural network. This enables us to find image correspondences using a generic turbine model that can be applied to a wide range of turbine shapes and sizes. To estimate 3D pose of the drone, we fuse the network output with GPS and IMU measurements using a pose graph optimiser. Results illustrate that the use of the image measurements significantly improves the accuracy of the localisation over that obtained using GPS and IMU alone.
Predicting Out-of-View Feature Points for Model-Based Camera Pose Estimation
Mar 05, 2018
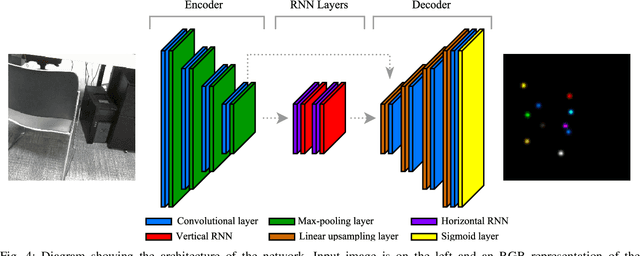
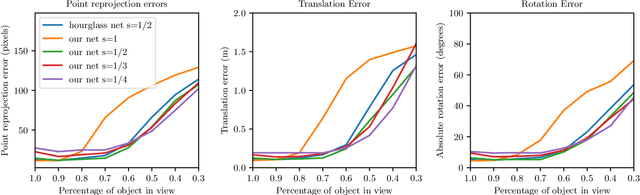

In this work we present a novel framework that uses deep learning to predict object feature points that are out-of-view in the input image. This system was developed with the application of model-based tracking in mind, particularly in the case of autonomous inspection robots, where only partial views of the object are available. Out-of-view prediction is enabled by applying scaling to the feature point labels during network training. This is combined with a recurrent neural network architecture designed to provide the final prediction layers with rich feature information from across the spatial extent of the input image. To show the versatility of these out-of-view predictions, we describe how to integrate them in both a particle filter tracker and an optimisation based tracker. To evaluate our work we compared our framework with one that predicts only points inside the image. We show that as the amount of the object in view decreases, being able to predict outside the image bounds adds robustness to the final pose estimation.
Automated Map Reading: Image Based Localisation in 2-D Maps Using Binary Semantic Descriptors
Mar 02, 2018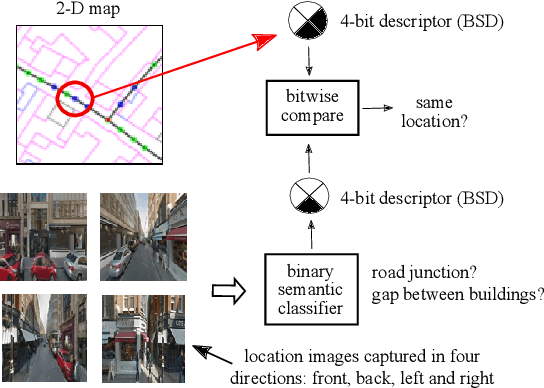
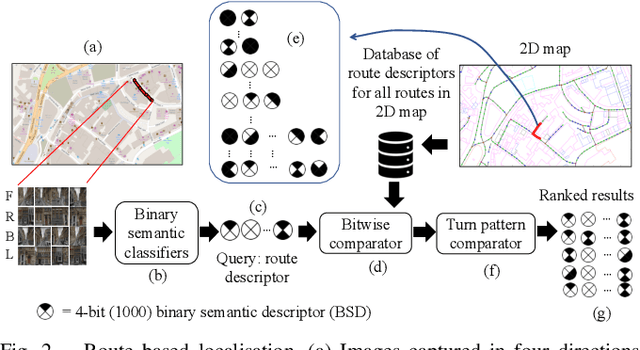
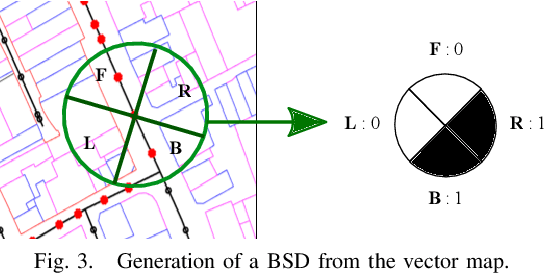

We describe a novel approach to image based localisation in urban environments using semantic matching between images and a 2-D map. It contrasts with the vast majority of existing approaches which use image to image database matching. We use highly compact binary descriptors to represent semantic features at locations, significantly increasing scalability compared with existing methods and having the potential for greater invariance to variable imaging conditions. The approach is also more akin to human map reading, making it more suited to human-system interaction. The binary descriptors indicate the presence or not of semantic features relating to buildings and road junctions in discrete viewing directions. We use CNN classifiers to detect the features in images and match descriptor estimates with a database of location tagged descriptors derived from the 2-D map. In isolation, the descriptors are not sufficiently discriminative, but when concatenated sequentially along a route, their combination becomes highly distinctive and allows localisation even when using non-perfect classifiers. Performance is further improved by taking into account left or right turns over a route. Experimental results obtained using Google StreetView and OpenStreetMap data show that the approach has considerable potential, achieving localisation accuracy of around 85% using routes corresponding to approximately 200 meters.