 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-based Geolocalization by Ground-to-2.5D Map Matching
Aug 11, 2023



We study the image-based geolocalization problem that aims to locate ground-view query images on cartographic maps. Previous methods often utilize cross-view localization techniques to match ground-view query images with 2D maps. However, the performance of these methods is frequently unsatisfactory due to the significant cross-view appearance differences. In this paper, we extend cross-view matching to 2.5D spaces, where the heights of the structures - such as trees, buildings, and other objects - can provide additional information to guide the cross-view matching. We present a new approach to learning representative embeddings from multi-model data. Specifically, we first align 2D maps to ground-view panoramic images with polar transform to reduce the gap between panoramic images and maps. Then we leverage global fusion to fuse the multi-modal features from 2D and 2.5D maps to increase the distinctiveness of location embeddings. We construct the first large-scale ground-to-2.5D map geolocalization dataset to validate our method and facilitate the research. We test our learned embeddings on two popular localization approaches, i.e., single-image based localization, and route based localization. Extensive experiments demonstrate that our proposed method achieves significantly higher localization accuracy and faster convergence than previous 2D map-based approaches.
You Are Here: Geolocation by Embedding Maps and Images
Nov 20, 2019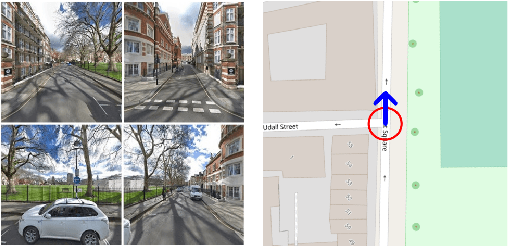
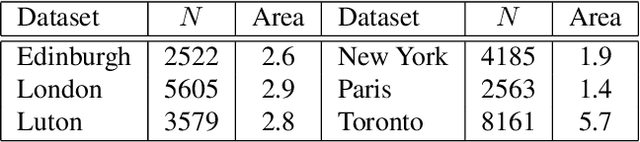
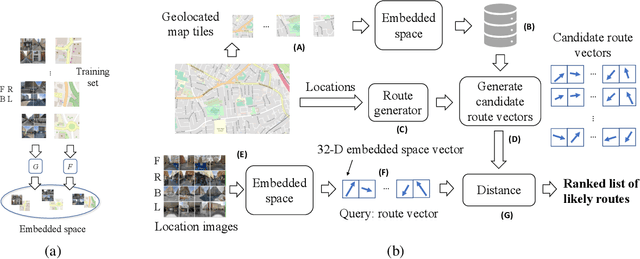
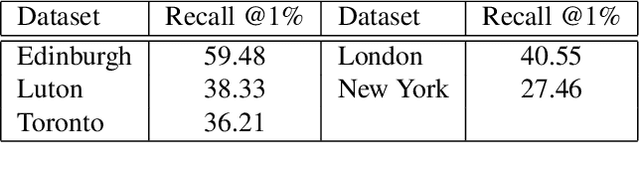
We present a novel approach to geolocating images on a 2-D map based on learning a low dimensional embedded space, which allows a comparison between an image captured at a location and local neighbourhoods of the map. The representation is not sufficiently discriminatory to allow localisation from a single image but when concatenated along a route, localisation converges quickly, with over 90% accuracy being achieved for routes up to 200m in length when using Google Street View and Open Street Map data. The approach generalises a previous fixed semantic feature based approach and achieves faster convergence and higher accuracy without the need for including turn information.