 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Domain Image Synthesis using Segmentation-Guided GAN
Paper and Code
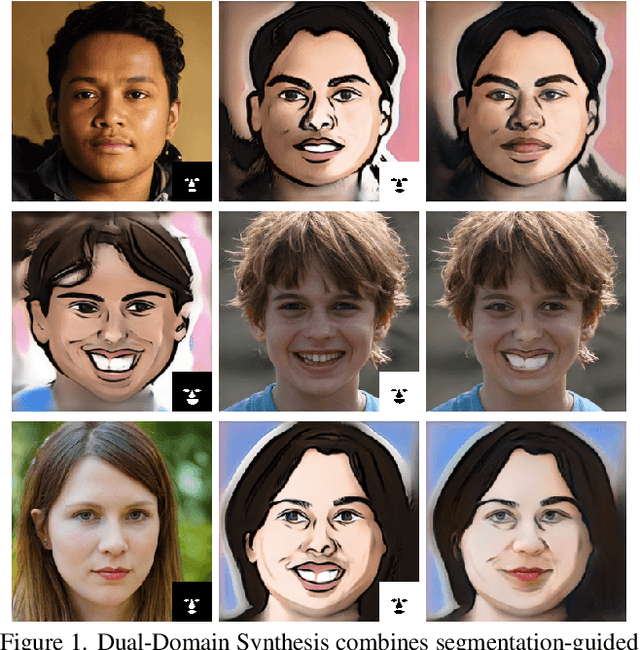
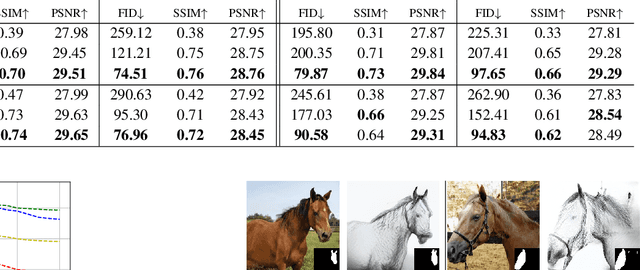
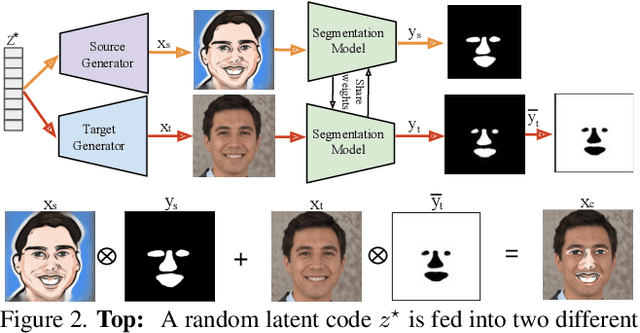
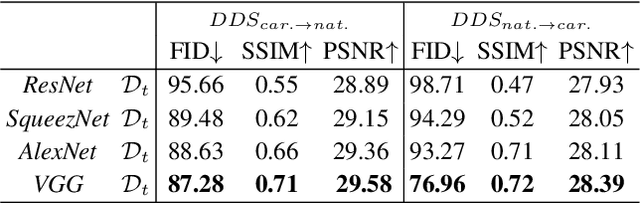
We introduce a segmentation-guided approach to synthesise images that integrate features from two distinct domains. Images synthesised by our dual-domain model belong to one domain within the semantic mask, and to another in the rest of the image - smoothly integrated. We build on the successes of few-shot StyleGAN and single-shot semantic segmentation to minimise the amount of training required in utilising two domains. The method combines a few-shot cross-domain StyleGAN with a latent optimiser to achieve images containing features of two distinct domains. We use a segmentation-guided perceptual loss, which compares both pixel-level and activations between domain-specific and dual-domain synthetic images. Results demonstrate qualitatively and quantitatively that our model is capable of synthesising dual-domain images on a variety of objects (faces, horses, cats, cars), domains (natural, caricature, sketches) and part-based masks (eyes, nose, mouth, hair, car bonnet). The code is publicly available at: https://github.com/denabazazian/Dual-Domain-Synthesis.