 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Study of The Effects of Position Bias on Emotion CauseExtraction
Paper and Code


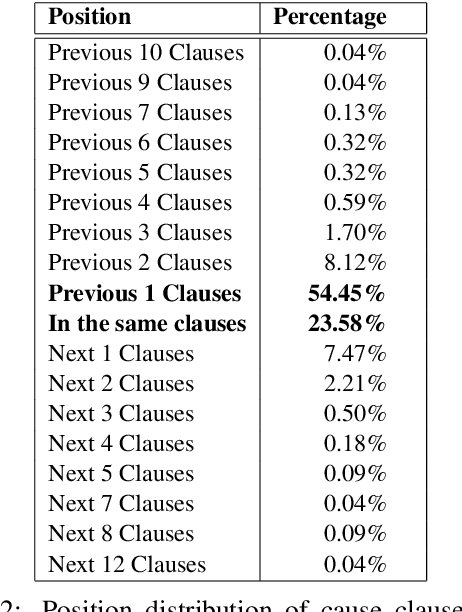
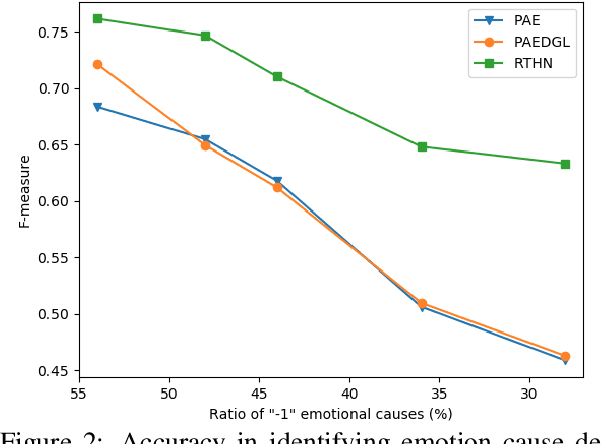
Emotion Cause Extraction (ECE) aims to identify emotion causes from a document after annotating the emotion keywords. Some baselines have been proposed to address this problem, such as rule-based, commonsense based and machine learning methods. We show, however, that a simple random selection approach toward ECE that does not require observing the text achieves similar performance compared to the baselines. We utilized only position information relative to the emotion cause to accomplish this goal. Since position information alone without observing the text resulted in higher F-measure, we therefore uncovered a bias in the ECE single genre Sina-news benchmark. Further analysis showed that an imbalance of emotional cause location exists in the benchmark, with a majority of cause clauses immediately preceding the central emotion clause. We examine the bias from a linguistic perspective, and show that high accuracy rate of current state-of-art deep learning models that utilize location information is only evident in datasets that contain such position biases. The accuracy drastically reduced when a dataset with balanced location distribution is introduced. We therefore conclude that it is the innate bias in this benchmark that caused high accuracy rate of these deep learning models in ECE. We hope that the case study in this paper presents both a cautionary lesson, as well as a template for further studies, in interpreting the superior fit of deep learning models without checking for bias.