 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Synthesis along Perceptual Voice Quality Dimensions
Paper and Code
Jan 15, 2025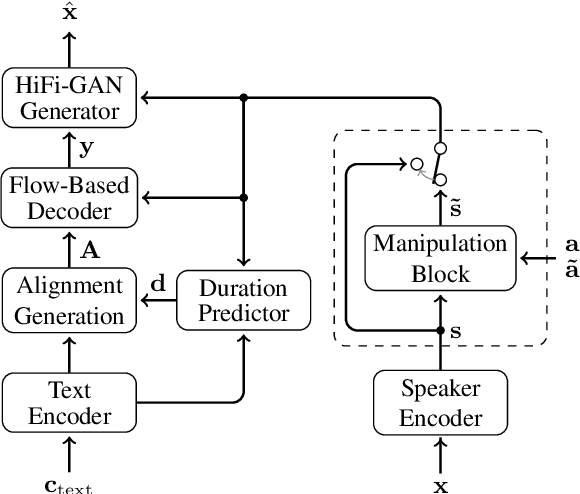
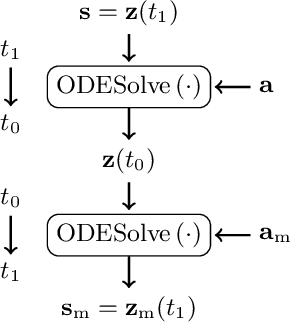
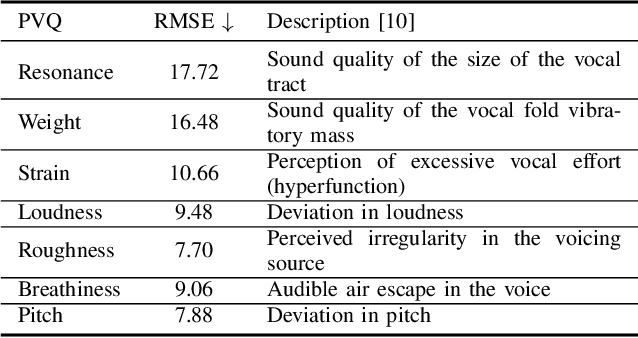

While expressive speech synthesis or voice conversion systems mainly focus on controlling or manipulating abstract prosodic characteristics of speech, such as emotion or accent, we here address the control of perceptual voice qualities (PVQs) recognized by phonetic experts, which are speech properties at a lower level of abstraction. The ability to manipulate PVQs can be a valuable tool for teaching speech pathologists in training or voice actors. In this paper, we integrate a Conditional Continuous-Normalizing-Flow-based method into a Text-to-Speech system to modify perceptual voice attributes on a continuous scale. Unlike previous approaches, our system avoids direct manipulation of acoustic correlates and instead learns from examples. We demonstrate the system's capability by manipulating four voice qualities: Roughness, breathiness, resonance and weight. Phonetic experts evaluated these modifications, both for seen and unseen speaker conditions. The results highlight both the system's strengths and areas for improvement.