Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Feature Importance and Interpretability of Speaker Representations
Paper and Code
Oct 19, 2023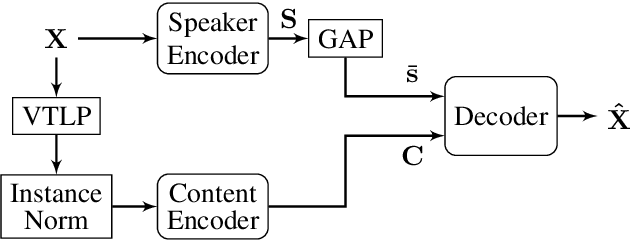
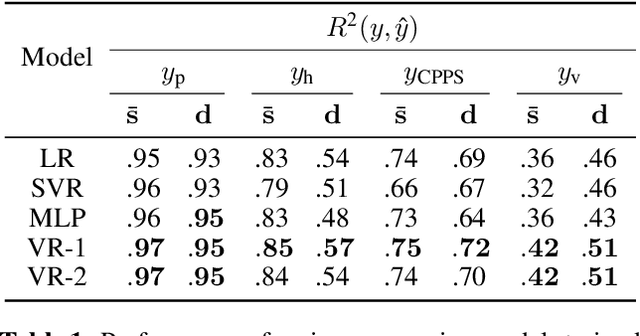
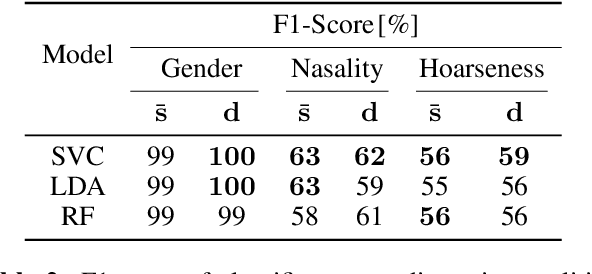

Unsupervised speech disentanglement aims at separating fast varying from slowly varying components of a speech signal. In this contribution, we take a closer look at the embedding vector representing the slowly varying signal components, commonly named the speaker embedding vector. We ask, which properties of a speaker's voice are captured and investigate to which extent do individual embedding vector components sign responsible for them, using the concept of Shapley values. Our findings show that certain speaker-specific acoustic-phonetic properties can be fairly well predicted from the speaker embedding, while the investigated more abstract voice quality features cannot.
* Presented at the ITG conference on Speech Communication 2023
View paper on