 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge30+ Years of Source Separation Research: Achievements and Future Challenges
Jan 21, 2025Source separation (SS) of acoustic signals is a research field that emerged in the mid-1990s and has flourished ever since. On the occasion of ICASSP's 50th anniversary, we review the major contributions and advancements in the past three decades in the speech, audio, and music SS research field. We will cover both single- and multi-channel SS approaches. We will also look back on key efforts to foster a culture of scientific evaluation in the research field, including challenges, performance metrics, and datasets. We will conclude by discussing current trends and future research directions.
Audio Signal Enhancement with Learning from Positive and Unlabelled Data
Oct 30, 2022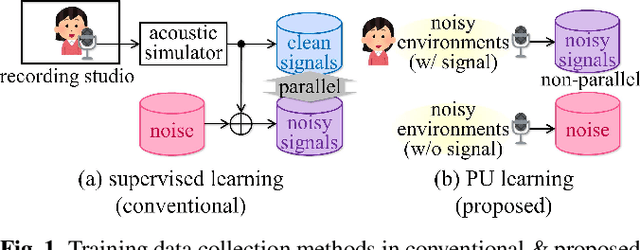
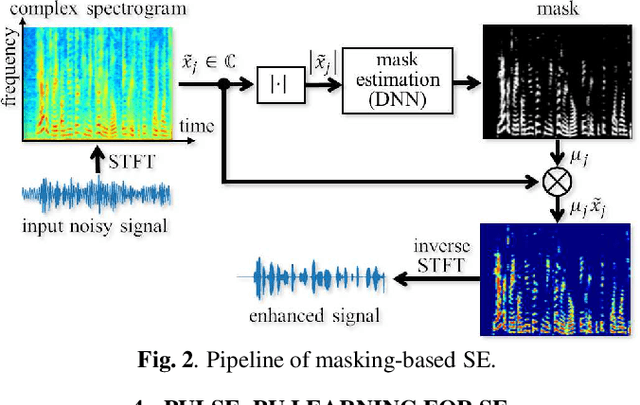
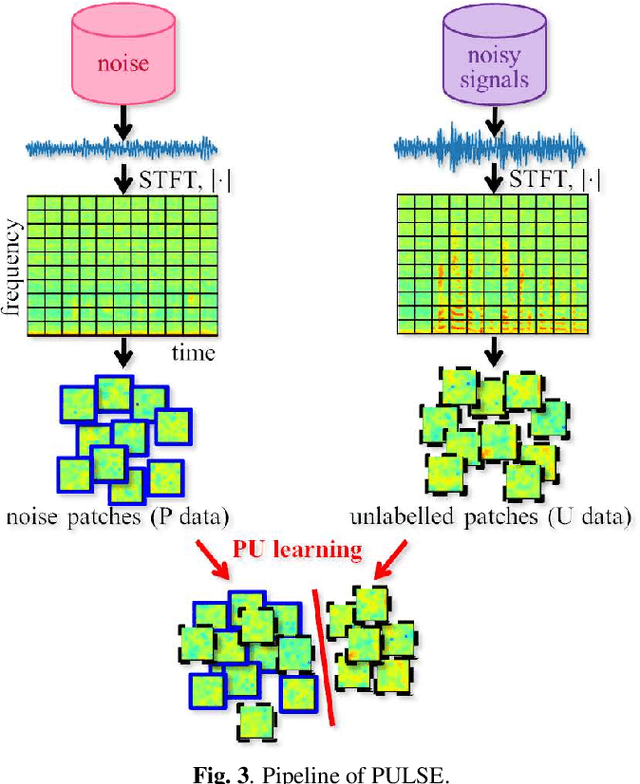
Supervised learning is a mainstream approach to audio signal enhancement (SE) and requires parallel training data consisting of both noisy signals and the corresponding clean signals. Such data can only be synthesised and are thus mismatched with real data, which can result in poor performance. Moreover, it is often difficult/impossible to obtain clean signals, making it difficult/impossible to apply the approach in this case. Here we explore SE using non-parallel training data consisting of noisy signals and noise, which can be easily recorded. We define the positive (P) and the negative (N) classes as signal absence and presence, respectively. We observe that the spectrogram patches of noise clips can be used as P data and those of noisy signal clips as unlabelled data. Thus, learning from positive and unlabelled data enables a convolutional neural network to learn to classify each spectrogram patch as P or N for SE.
A Joint Diagonalization Based Efficient Approach to Underdetermined Blind Audio Source Separation Using the Multichannel Wiener Filter
Jan 21, 2021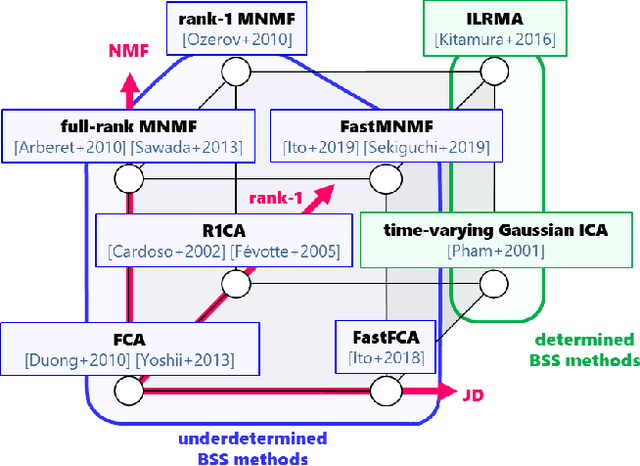
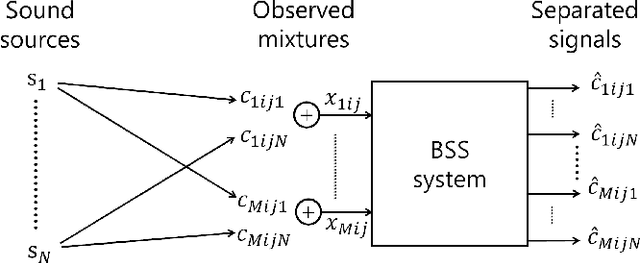

This paper presents a computationally efficient approach to blind source separation (BSS) of audio signals, applicable even when there are more sources than microphones (i.e., the underdetermined case). When there are as many sources as microphones (i.e., the determined case), BSS can be performed computationally efficiently by independent component analysis (ICA). Unfortunately, however, ICA is basically inapplicable to the underdetermined case. Another BSS approach using the multichannel Wiener filter (MWF) is applicable even to this case, and encompasses full-rank spatial covariance analysis (FCA) and multichannel non-negative matrix factorization (MNMF). However, these methods require massive numbers of matrix inversions to design the MWF, and are thus computationally inefficient. To overcome this drawback, we exploit the well-known property of diagonal matrices that matrix inversion amounts to mere inversion of the diagonal elements and can thus be performed computationally efficiently. This makes it possible to drastically reduce the computational cost of the above matrix inversions based on a joint diagonalization (JD) idea, leading to computationally efficient BSS. Specifically, we restrict the N spatial covariance matrices (SCMs) of all N sources to a class of (exactly) jointly diagonalizable matrices. Based on this approach, we present FastFCA, a computationally efficient extension of FCA. We also present a unified framework for underdetermined and determined audio BSS, which highlights a theoretical connection between FastFCA and other methods. Moreover, we reveal that FastFCA can be regarded as a regularized version of approximate joint diagonalization (AJD).