 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Signal Enhancement with Learning from Positive and Unlabelled Data
Paper and Code
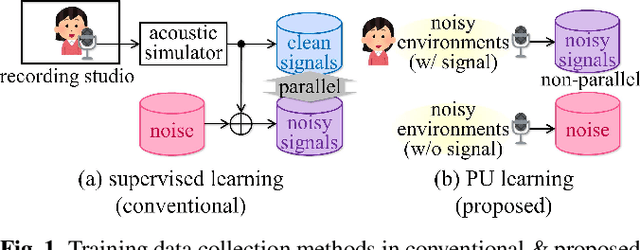
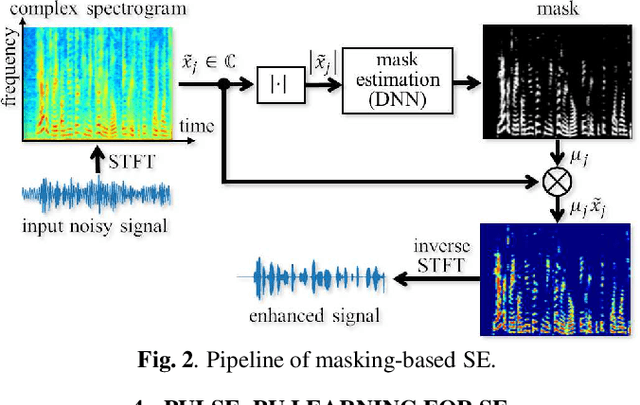
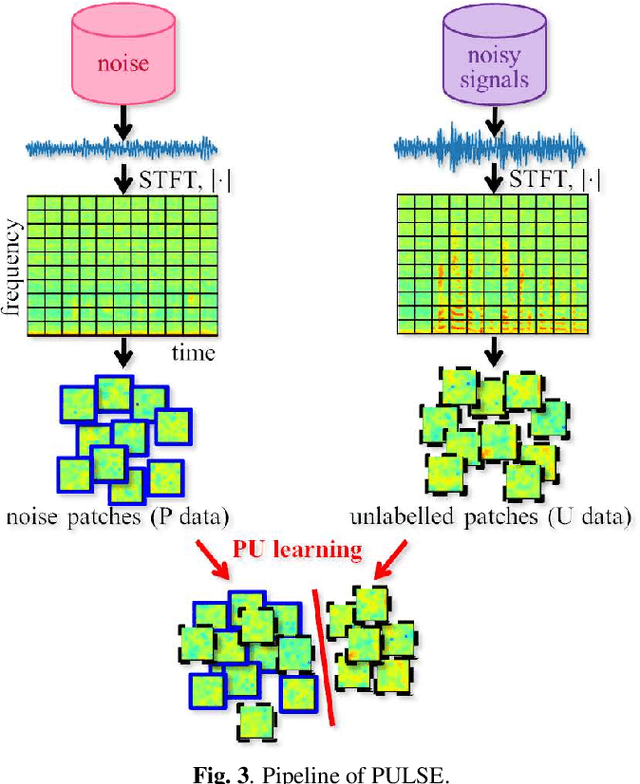
Supervised learning is a mainstream approach to audio signal enhancement (SE) and requires parallel training data consisting of both noisy signals and the corresponding clean signals. Such data can only be synthesised and are thus mismatched with real data, which can result in poor performance. Moreover, it is often difficult/impossible to obtain clean signals, making it difficult/impossible to apply the approach in this case. Here we explore SE using non-parallel training data consisting of noisy signals and noise, which can be easily recorded. We define the positive (P) and the negative (N) classes as signal absence and presence, respectively. We observe that the spectrogram patches of noise clips can be used as P data and those of noisy signal clips as unlabelled data. Thus, learning from positive and unlabelled data enables a convolutional neural network to learn to classify each spectrogram patch as P or N for SE.