 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPM: Federated Learning Using Second-order Optimization with Preconditioned Mixing of Local Parameters
Nov 12, 2025We propose Federated Preconditioned Mixing (FedPM), a novel Federated Learning (FL) method that leverages second-order optimization. Prior methods--such as LocalNewton, LTDA, and FedSophia--have incorporated second-order optimization in FL by performing iterative local updates on clients and applying simple mixing of local parameters on the server. However, these methods often suffer from drift in local preconditioners, which significantly disrupts the convergence of parameter training, particularly in heterogeneous data settings. To overcome this issue, we refine the update rules by decomposing the ideal second-order update--computed using globally preconditioned global gradients--into parameter mixing on the server and local parameter updates on clients. As a result, our FedPM introduces preconditioned mixing of local parameters on the server, effectively mitigating drift in local preconditioners. We provide a theoretical convergence analysis demonstrating a superlinear rate for strongly convex objectives in scenarios involving a single local update. To demonstrate the practical benefits of FedPM, we conducted extensive experiments. The results showed significant improvements with FedPM in the test accuracy compared to conventional methods incorporating simple mixing, fully leveraging the potential of second-order optimization.
Evacuation Shelter Scheduling Problem
Nov 26, 2021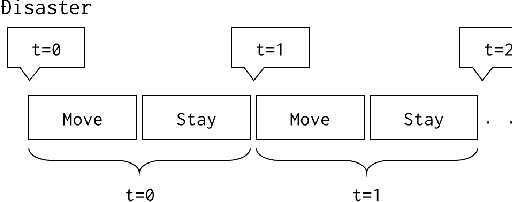

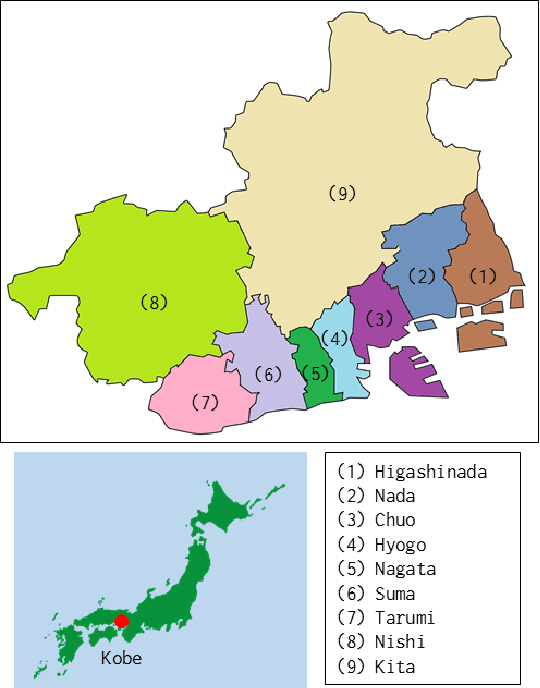
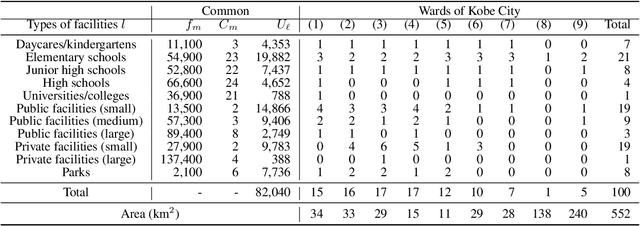
Evacuation shelters, which are urgently required during natural disasters, are designed to minimize the burden of evacuation on human survivors. However, the larger the scale of the disaster, the more costly it becomes to operate shelters. When the number of evacuees decreases, the operation costs can be reduced by moving the remaining evacuees to other shelters and closing shelters as quickly as possible. On the other hand, relocation between shelters imposes a huge emotional burden on evacuees. In this study, we formulate the "Evacuation Shelter Scheduling Problem," which allocates evacuees to shelters in such a way to minimize the movement costs of the evacuees and the operation costs of the shelters. Since it is difficult to solve this quadratic programming problem directly, we show its transformation into a 0-1 integer programming problem. In addition, such a formulation struggles to calculate the burden of relocating them from historical data because no payments are actually made. To solve this issue, we propose a method that estimates movement costs based on the numbers of evacuees and shelters during an actual disaster. Simulation experiments with records from the Kobe earthquake (Great Hanshin-Awaji Earthquake) showed that our proposed method reduced operation costs by 33.7 million dollars: 32%.
Switching Independent Vector Analysis and Its Extension to Blind and Spatially Guided Convolutional Beamforming Algorithm
Nov 20, 2021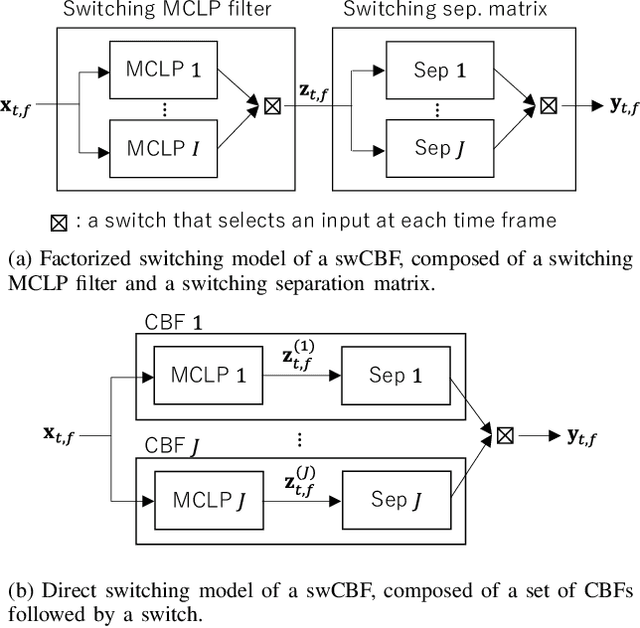
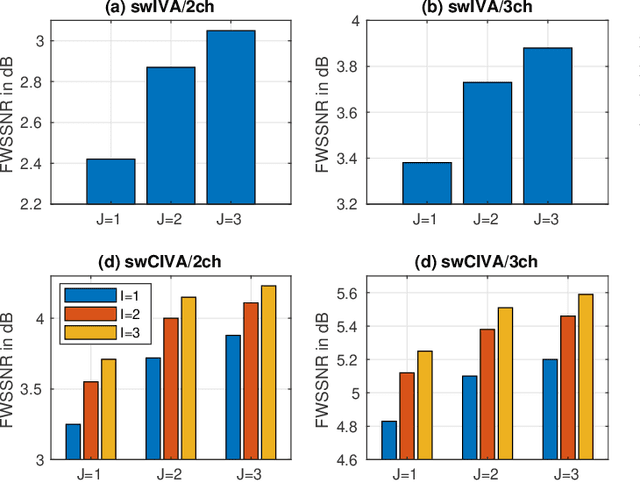
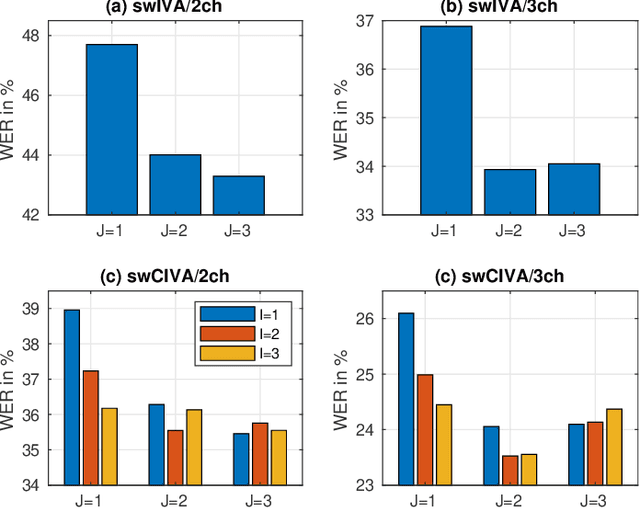
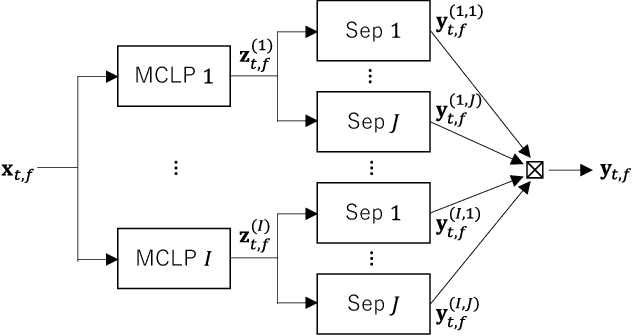
This paper develops a framework that can perform denoising, dereverberation, and source separation accurately by using a relatively small number of microphones. It has been empirically confirmed that Independent Vector Analysis (IVA) can blindly separate $N$ sources from their sound mixture even with diffuse noise when a sufficiently large number ($=M$) of microphones are available (i.e., $M\gg N)$. However, the estimation accuracy seriously degrades as the number of microphones, or more specifically $M-N$ $(\ge 0)$, decreases. To overcome this limitation of IVA, we propose switching IVA (swIVA) in this paper. With swIVA, time frames of an observed signal with time-varying characteristics are clustered into several groups, each of which can be well handled by IVA using a small number of microphones, and thus accurate estimation can be achieved by applying {\IVA} individually to each of the groups. Conventionally, a switching mechanism was introduced into a beamformer; however, no blind source separation algorithms with a switching mechanism have been successfully developed until this paper. In order to incorporate dereverberation capability, this paper further extends swIVA to blind Convolutional beamforming algorithm (swCIVA). It integrates swIVA and switching Weighted Prediction Error-based dereverberation (swWPE) in a jointly optimal way. We show that both swIVA and swIVAconv can be optimized effectively based on blind signal processing, and that their performance can be further improved using a spatial guide for the initialization. Experiments show that the both proposed methods largely outperform conventional IVA and its Convolutional beamforming extension (CIVA) in terms of objective signal quality and automatic speech recognition scores when using a relatively small number of microphones.
Acceleration Method for Learning Fine-Layered Optical Neural Networks
Sep 01, 2021
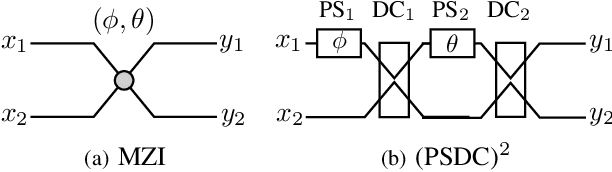


An optical neural network (ONN) is a promising system due to its high-speed and low-power operation. Its linear unit performs a multiplication of an input vector and a weight matrix in optical analog circuits. Among them, a circuit with a multiple-layered structure of programmable Mach-Zehnder interferometers (MZIs) can realize a specific class of unitary matrices with a limited number of MZIs as its weight matrix. The circuit is effective for balancing the number of programmable MZIs and ONN performance. However, it takes a lot of time to learn MZI parameters of the circuit with a conventional automatic differentiation (AD), which machine learning platforms are equipped with. To solve the time-consuming problem, we propose an acceleration method for learning MZI parameters. We create customized complex-valued derivatives for an MZI, exploiting Wirtinger derivatives and a chain rule. They are incorporated into our newly developed function module implemented in C++ to collectively calculate their values in a multi-layered structure. Our method is simple, fast, and versatile as well as compatible with the conventional AD. We demonstrate that our method works 20 times faster than the conventional AD when a pixel-by-pixel MNIST task is performed in a complex-valued recurrent neural network with an MZI-based hidden unit.
Blind and neural network-guided convolutional beamformer for joint denoising, dereverberation, and source separation
Aug 04, 2021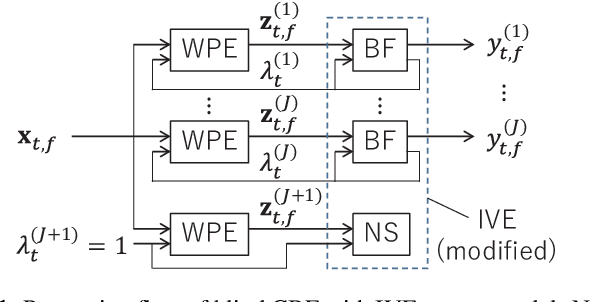

This paper proposes an approach for optimizing a Convolutional BeamFormer (CBF) that can jointly perform denoising (DN), dereverberation (DR), and source separation (SS). First, we develop a blind CBF optimization algorithm that requires no prior information on the sources or the room acoustics, by extending a conventional joint DR and SS method. For making the optimization computationally tractable, we incorporate two techniques into the approach: the Source-Wise Factorization (SW-Fact) of a CBF and the Independent Vector Extraction (IVE). To further improve the performance, we develop a method that integrates a neural network(NN) based source power spectra estimation with CBF optimization by an inverse-Gamma prior. Experiments using noisy reverberant mixtures reveal that our proposed method with both blind and NN-guided scenarios greatly outperforms the conventional state-of-the-art NN-supported mask-based CBF in terms of the improvement in automatic speech recognition and signal distortion reduction performance.
A Joint Diagonalization Based Efficient Approach to Underdetermined Blind Audio Source Separation Using the Multichannel Wiener Filter
Jan 21, 2021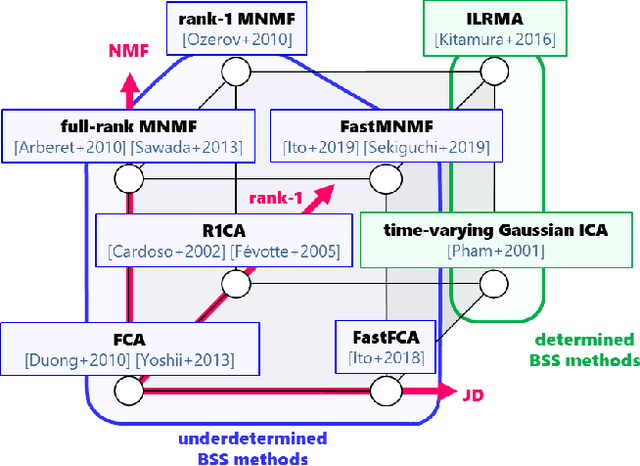
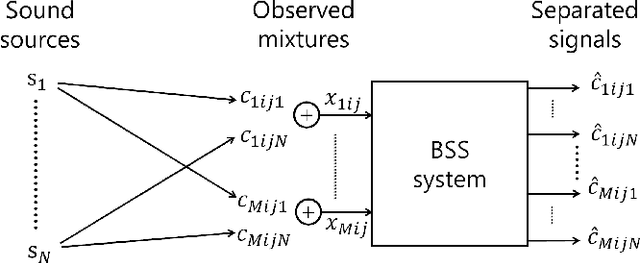

This paper presents a computationally efficient approach to blind source separation (BSS) of audio signals, applicable even when there are more sources than microphones (i.e., the underdetermined case). When there are as many sources as microphones (i.e., the determined case), BSS can be performed computationally efficiently by independent component analysis (ICA). Unfortunately, however, ICA is basically inapplicable to the underdetermined case. Another BSS approach using the multichannel Wiener filter (MWF) is applicable even to this case, and encompasses full-rank spatial covariance analysis (FCA) and multichannel non-negative matrix factorization (MNMF). However, these methods require massive numbers of matrix inversions to design the MWF, and are thus computationally inefficient. To overcome this drawback, we exploit the well-known property of diagonal matrices that matrix inversion amounts to mere inversion of the diagonal elements and can thus be performed computationally efficiently. This makes it possible to drastically reduce the computational cost of the above matrix inversions based on a joint diagonalization (JD) idea, leading to computationally efficient BSS. Specifically, we restrict the N spatial covariance matrices (SCMs) of all N sources to a class of (exactly) jointly diagonalizable matrices. Based on this approach, we present FastFCA, a computationally efficient extension of FCA. We also present a unified framework for underdetermined and determined audio BSS, which highlights a theoretical connection between FastFCA and other methods. Moreover, we reveal that FastFCA can be regarded as a regularized version of approximate joint diagonalization (AJD).
Finding Appropriate Traffic Regulations via Graph Convolutional Networks
Oct 23, 2018

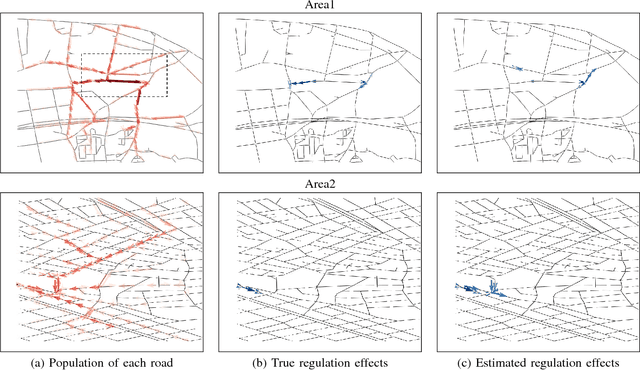
Appropriate traffic regulations, e.g. planned road closure, are important in congested events. Crowd simulators have been used to find appropriate regulations by simulating multiple scenarios with different regulations. However, this approach requires multiple simulation runs, which are time-consuming. In this paper, we propose a method to learn a function that outputs regulation effects given the current traffic situation as inputs. If the function is learned using the training data of many simulation runs in advance, we can obtain an appropriate regulation efficiently by bypassing simulations for the current situation. We use the graph convolutional networks for modeling the function, which enable us to find regulations even for unseen areas. With the proposed method, we construct a graph for each area, where a node represents a road, and an edge represents the road connection. By running crowd simulations with various regulations on various areas, we generate traffic situations and regulation effects. The graph convolutional networks are trained to output the regulation effects given the graph with the traffic situation information as inputs. With experiments using real-world road networks and a crowd simulator, we demonstrate that the proposed method can find a road to close that reduces the average time needed to reach the destination.
Blind Source Separation with Optimal Transport Non-negative Matrix Factorization
Feb 15, 2018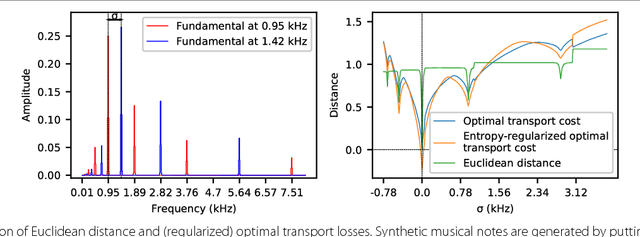
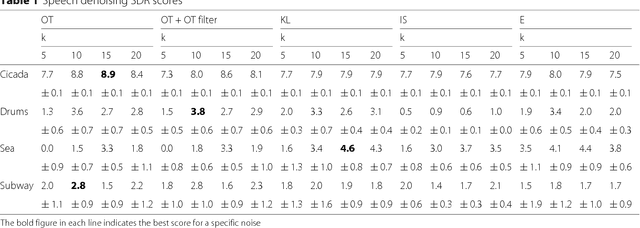
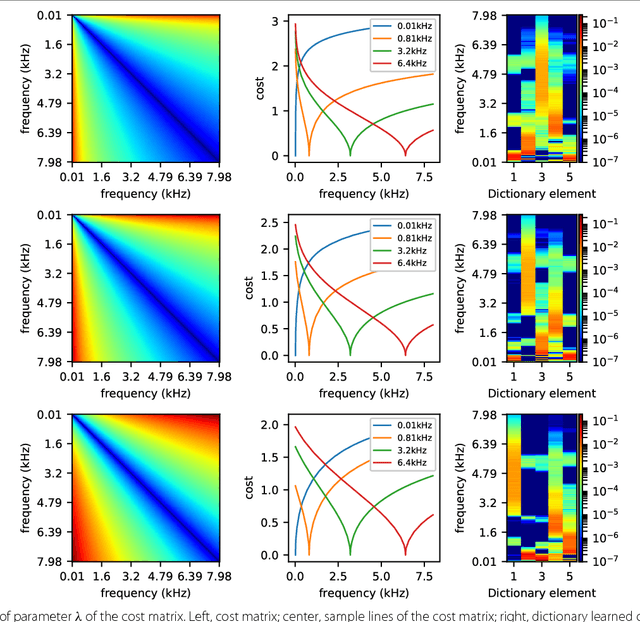
Optimal transport as a loss for machine learning optimization problems has recently gained a lot of attention. Building upon recent advances in computational optimal transport, we develop an optimal transport non-negative matrix factorization (NMF) algorithm for supervised speech blind source separation (BSS). Optimal transport allows us to design and leverage a cost between short-time Fourier transform (STFT) spectrogram frequencies, which takes into account how humans perceive sound. We give empirical evidence that using our proposed optimal transport NMF leads to perceptually better results than Euclidean NMF, for both isolated voice reconstruction and BSS tasks. Finally, we demonstrate how to use optimal transport for cross domain sound processing tasks, where frequencies represented in the input spectrograms may be different from one spectrogram to another.
Histogram Meets Topic Model: Density Estimation by Mixture of Histograms
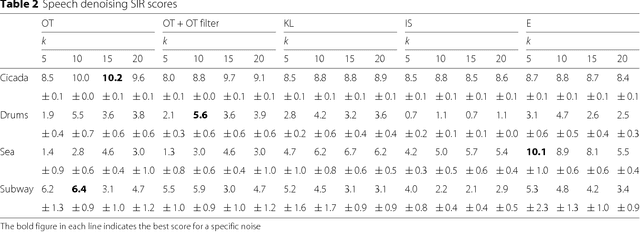
Dec 25, 2015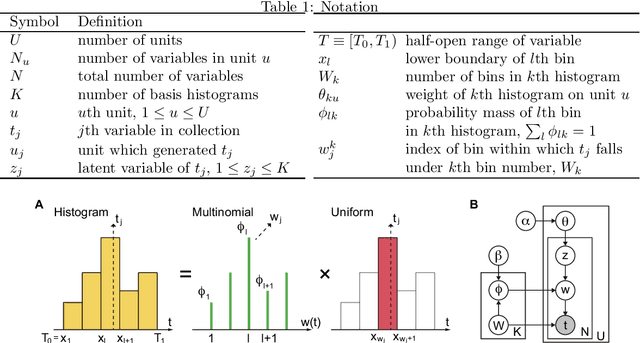
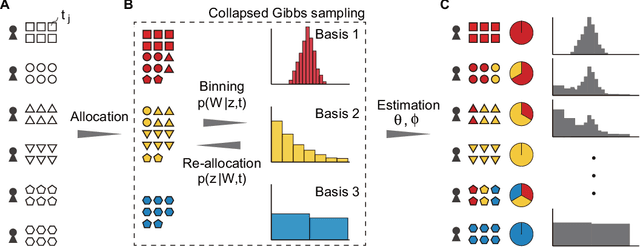
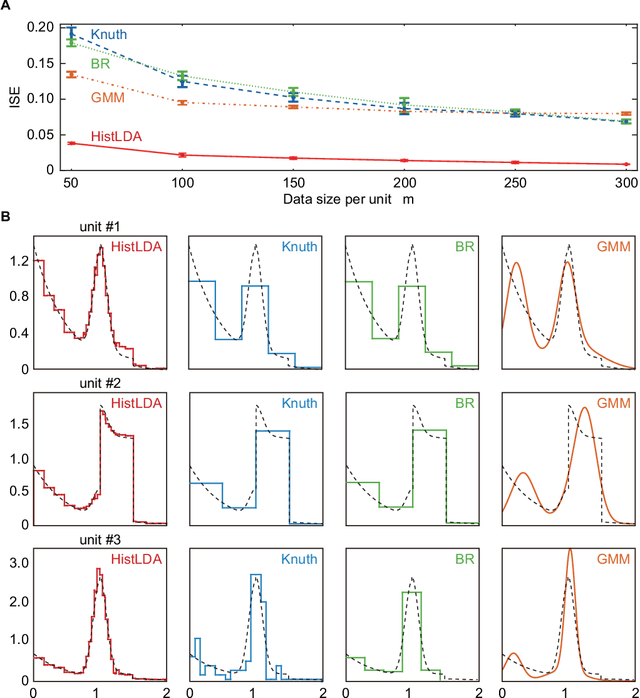
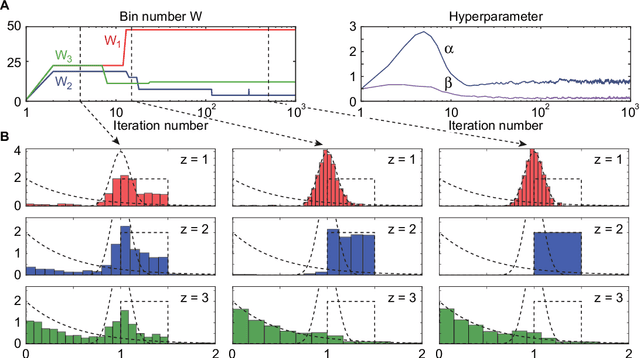
The histogram method is a powerful non-parametric approach for estimating the probability density function of a continuous variable. But the construction of a histogram, compared to the parametric approaches, demands a large number of observations to capture the underlying density function. Thus it is not suitable for analyzing a sparse data set, a collection of units with a small size of data. In this paper, by employing the probabilistic topic model, we develop a novel Bayesian approach to alleviating the sparsity problem in the conventional histogram estimation. Our method estimates a unit's density function as a mixture of basis histograms, in which the number of bins for each basis, as well as their heights, is determined automatically. The estimation procedure is performed by using the fast and easy-to-implement collapsed Gibbs sampling. We apply the proposed method to synthetic data, showing that it performs well.