 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Optimal Transport and Mapping Estimation
Feb 26, 2018

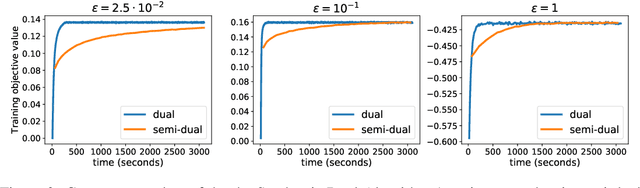
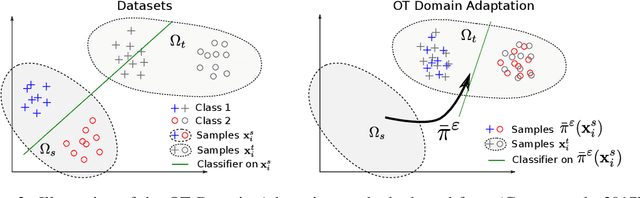
This paper presents a novel two-step approach for the fundamental problem of learning an optimal map from one distribution to another. First, we learn an optimal transport (OT) plan, which can be thought as a one-to-many map between the two distributions. To that end, we propose a stochastic dual approach of regularized OT, and show empirically that it scales better than a recent related approach when the amount of samples is very large. Second, we estimate a \textit{Monge map} as a deep neural network learned by approximating the barycentric projection of the previously-obtained OT plan. This parameterization allows generalization of the mapping outside the support of the input measure. We prove two theoretical stability results of regularized OT which show that our estimations converge to the OT plan and Monge map between the underlying continuous measures. We showcase our proposed approach on two applications: domain adaptation and generative modeling.
Smooth and Sparse Optimal Transport
Feb 20, 2018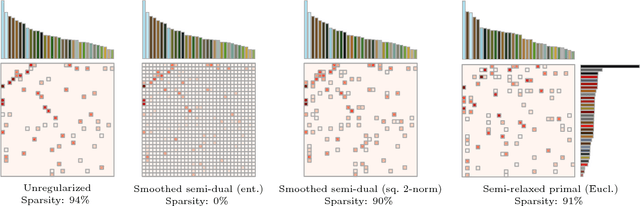
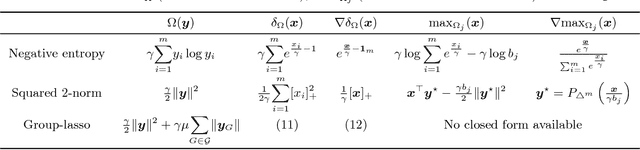

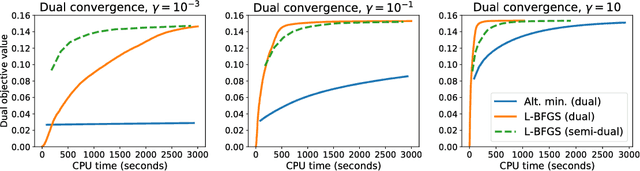
Entropic regularization is quickly emerging as a new standard in optimal transport (OT). It enables to cast the OT computation as a differentiable and unconstrained convex optimization problem, which can be efficiently solved using the Sinkhorn algorithm. However, entropy keeps the transportation plan strictly positive and therefore completely dense, unlike unregularized OT. This lack of sparsity can be problematic in applications where the transportation plan itself is of interest. In this paper, we explore regularizing the primal and dual OT formulations with a strongly convex term, which corresponds to relaxing the dual and primal constraints with smooth approximations. We show how to incorporate squared $2$-norm and group lasso regularizations within that framework, leading to sparse and group-sparse transportation plans. On the theoretical side, we bound the approximation error introduced by regularizing the primal and dual formulations. Our results suggest that, for the regularized primal, the approximation error can often be smaller with squared $2$-norm than with entropic regularization. We showcase our proposed framework on the task of color transfer.
Blind Source Separation with Optimal Transport Non-negative Matrix Factorization
Feb 15, 2018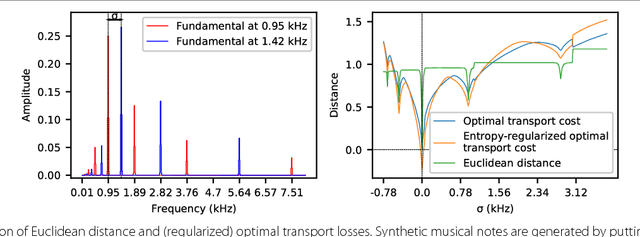
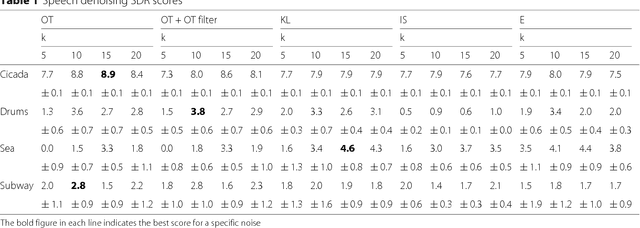
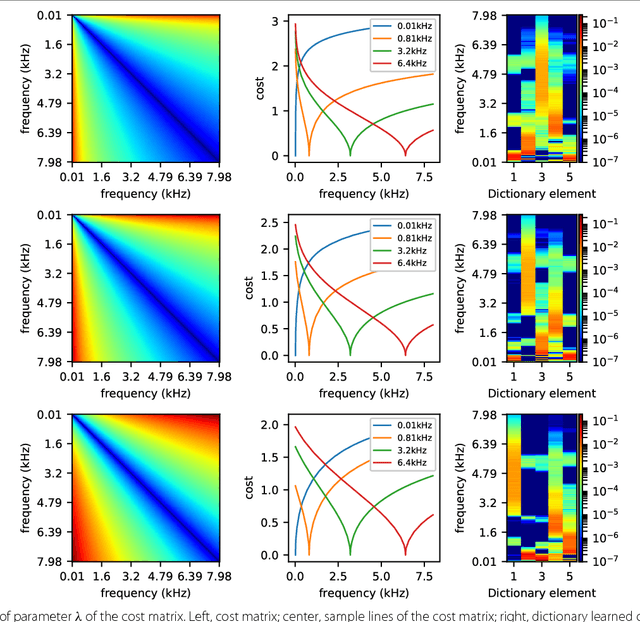
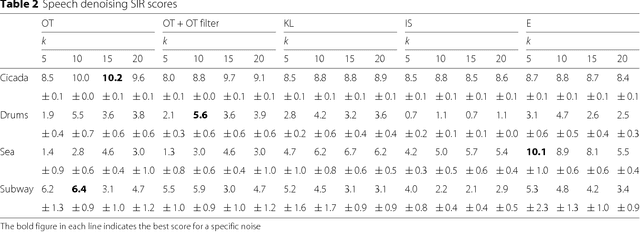
Optimal transport as a loss for machine learning optimization problems has recently gained a lot of attention. Building upon recent advances in computational optimal transport, we develop an optimal transport non-negative matrix factorization (NMF) algorithm for supervised speech blind source separation (BSS). Optimal transport allows us to design and leverage a cost between short-time Fourier transform (STFT) spectrogram frequencies, which takes into account how humans perceive sound. We give empirical evidence that using our proposed optimal transport NMF leads to perceptually better results than Euclidean NMF, for both isolated voice reconstruction and BSS tasks. Finally, we demonstrate how to use optimal transport for cross domain sound processing tasks, where frequencies represented in the input spectrograms may be different from one spectrogram to another.
Principal Geodesic Analysis for Probability Measures under the Optimal Transport Metric
Nov 22, 2015



Given a family of probability measures in P(X), the space of probability measures on a Hilbert space X, our goal in this paper is to highlight one ore more curves in P(X) that summarize efficiently that family. We propose to study this problem under the optimal transport (Wasserstein) geometry, using curves that are restricted to be geodesic segments under that metric. We show that concepts that play a key role in Euclidean PCA, such as data centering or orthogonality of principal directions, find a natural equivalent in the optimal transport geometry, using Wasserstein means and differential geometry. The implementation of these ideas is, however, computationally challenging. To achieve scalable algorithms that can handle thousands of measures, we propose to use a relaxed definition for geodesics and regularized optimal transport distances. The interest of our approach is demonstrated on images seen either as shapes or color histograms.