 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Speaker Embedding Disentanglement on Natural Read Speech
Paper and Code
Aug 08, 2023
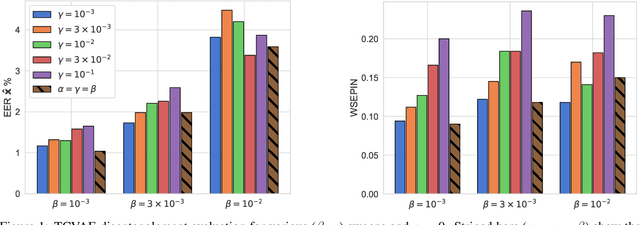
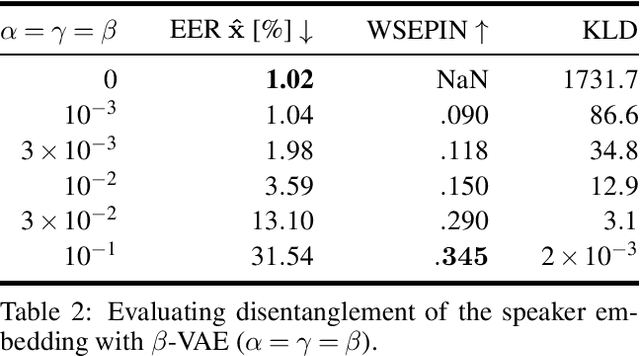
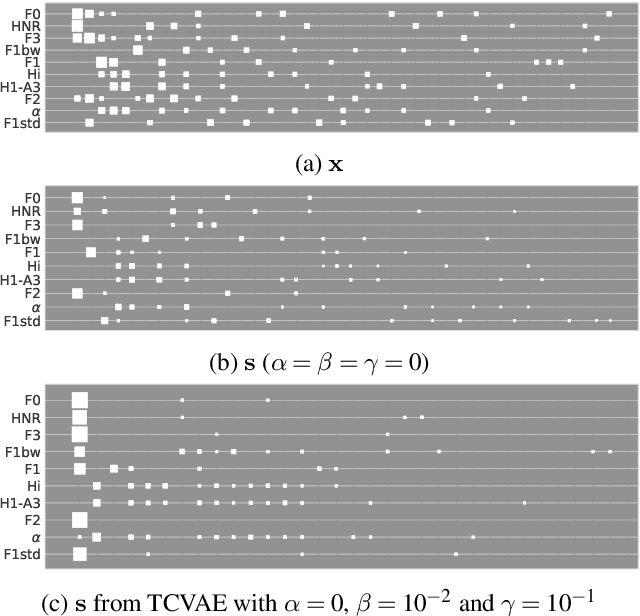
Disentanglement is the task of learning representations that identify and separate factors that explain the variation observed in data. Disentangled representations are useful to increase the generalizability, explainability, and fairness of data-driven models. Only little is known about how well such disentanglement works for speech representations. A major challenge when tackling disentanglement for speech representations are the unknown generative factors underlying the speech signal. In this work, we investigate to what degree speech representations encoding speaker identity can be disentangled. To quantify disentanglement, we identify acoustic features that are highly speaker-variant and can serve as proxies for the factors of variation underlying speech. We find that disentanglement of the speaker embedding is limited when trained with standard objectives promoting disentanglement but can be improved over vanilla representation learning to some extent.