 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Initialization Scheme for Meeting Separation with Spatial Mixture Models
Paper and Code
Apr 04, 2022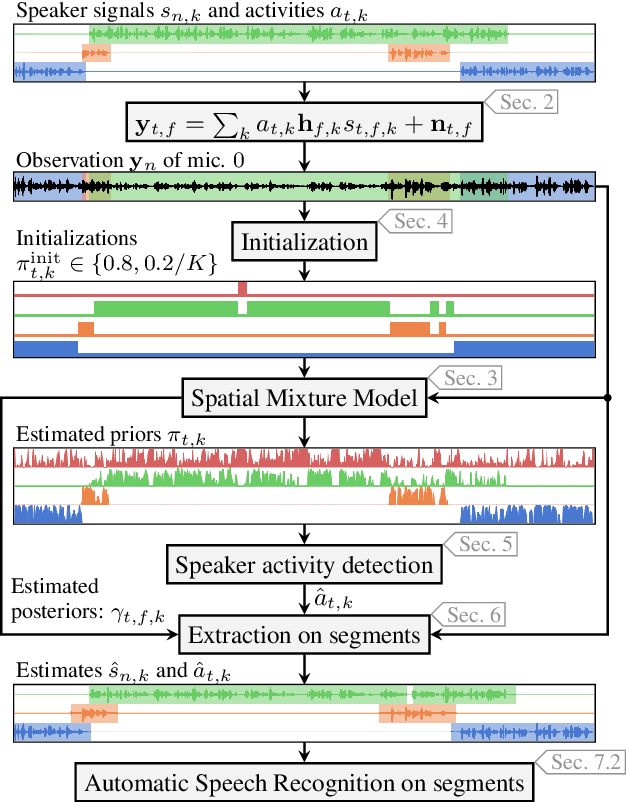
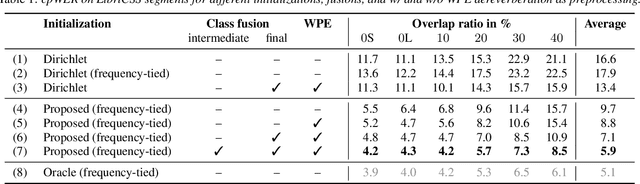
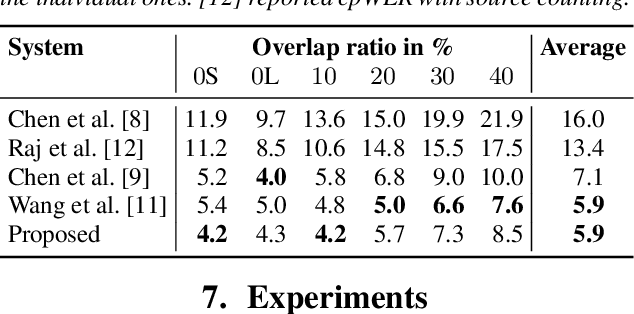
Spatial mixture model (SMM) supported acoustic beamforming has been extensively used for the separation of simultaneously active speakers. However, it has hardly been considered for the separation of meeting data, that are characterized by long recordings and only partially overlapping speech. In this contribution, we show that the fact that often only a single speaker is active can be utilized for a clever initialization of an SMM that employs time-varying class priors. In experiments on LibriCSS we show that the proposed initialization scheme achieves a significantly lower Word Error Rate (WER) on a downstream speech recognition task than a random initialization of the class probabilities by drawing from a Dirichlet distribution. With the only requirement that the number of speakers has to be known, we obtain a WER of 5.9 %, which is comparable to the best reported WER on this data set. Furthermore, the estimated speaker activity from the mixture model serves as a diarization based on spatial information.