 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-SDR: A novel loss function for separation of meeting style data
Paper and Code
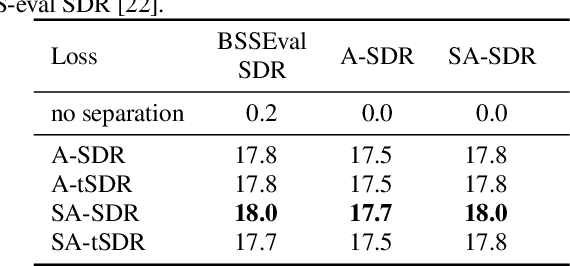
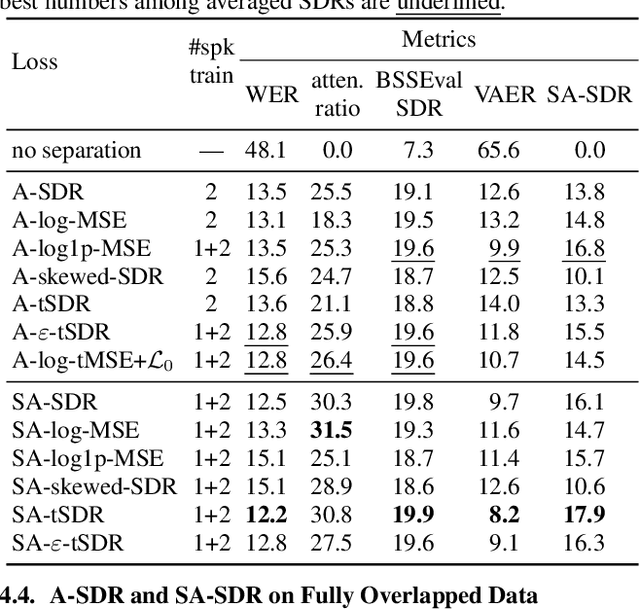
Many state-of-the-art neural network-based source separation systems use the averaged Signal-to-Distortion Ratio (SDR) as a training objective function. The basic SDR is, however, undefined if the network reconstructs the reference signal perfectly or if the reference signal contains silence, e.g., when a two-output separator processes a single-speaker recording. Many modifications to the plain SDR have been proposed that trade-off between making the loss more robust and distorting its value. We propose to switch from a mean over the SDRs of each individual output channel to a global SDR over all output channels at the same time, which we call source-aggregated SDR (SA-SDR). This makes the loss robust against silence and perfect reconstruction as long as at least one reference signal is not silent. We experimentally show that our proposed SA-SDR is more stable and preferable over other well-known modifications when processing meeting-style data that typically contains many silent or single-speaker regions.