 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural network-based virtual microphone estimation with virtual microphone and beamformer-level multi-task loss
Nov 20, 2023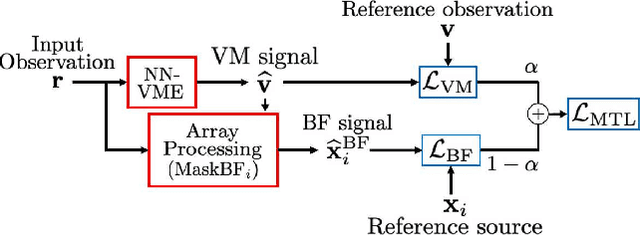
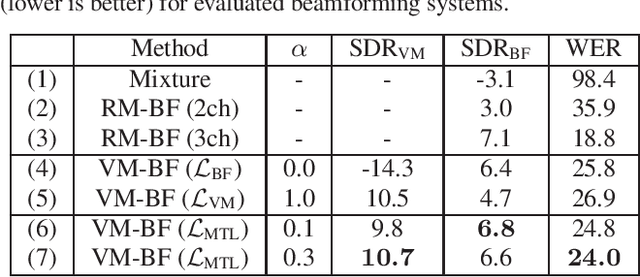
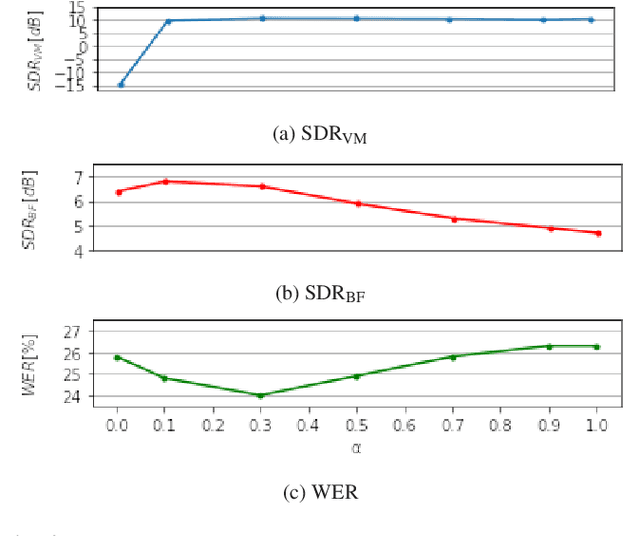
Array processing performance depends on the number of microphones available. Virtual microphone estimation (VME) has been proposed to increase the number of microphone signals artificially. Neural network-based VME (NN-VME) trains an NN with a VM-level loss to predict a signal at a microphone location that is available during training but not at inference. However, this training objective may not be optimal for a specific array processing back-end, such as beamforming. An alternative approach is to use a training objective considering the array-processing back-end, such as a loss on the beamformer output. This approach may generate signals optimal for beamforming but not physically grounded. To combine the advantages of both approaches, this paper proposes a multi-task loss for NN-VME that combines both VM-level and beamformer-level losses. We evaluate the proposed multi-task NN-VME on multi-talker underdetermined conditions and show that it achieves a 33.1 % relative WER improvement compared to using only real microphones and 10.8 % compared to using a prior NN-VME approach.