 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-informed Music Source Separation: Improving Synthetic-to-real Generalization in Classical Music
Mar 10, 2025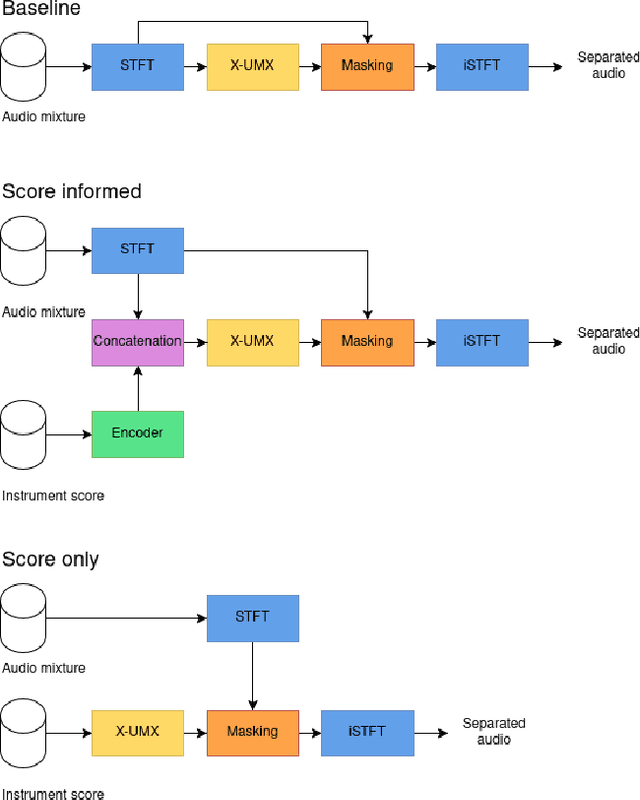
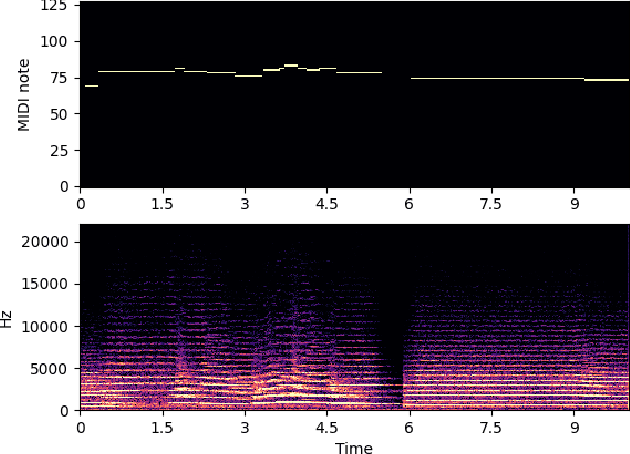
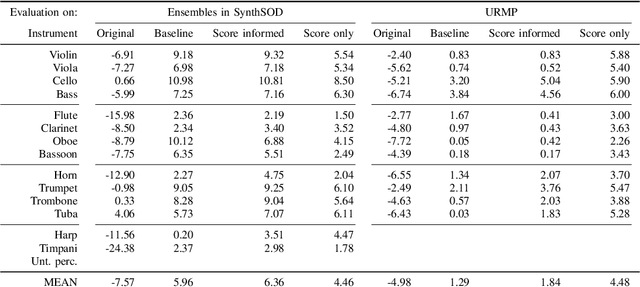
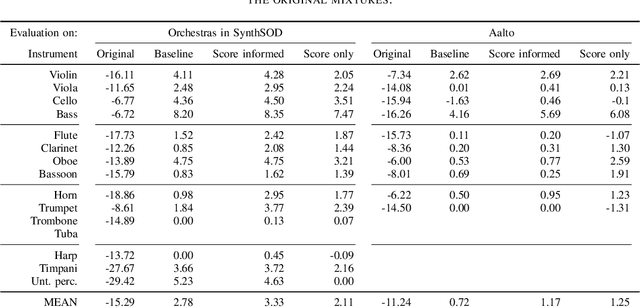
Music source separation is the task of separating a mixture of instruments into constituent tracks. Music source separation models are typically trained using only audio data, although additional information can be used to improve the model's separation capability. In this paper, we propose two ways of using musical scores to aid music source separation: a score-informed model where the score is concatenated with the magnitude spectrogram of the audio mixture as the input of the model, and a model where we use only the score to calculate the separation mask. We train our models on synthetic data in the SynthSOD dataset and evaluate our methods on the URMP and Aalto anechoic orchestra datasets, comprised of real recordings. The score-informed model improves separation results compared to a baseline approach, but struggles to generalize from synthetic to real data, whereas the score-only model shows a clear improvement in synthetic-to-real generalization.