 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Utterance Speech Separation and Association Trained on Short Segments
Jul 03, 2025Current deep neural network (DNN) based speech separation faces a fundamental challenge -- while the models need to be trained on short segments due to computational constraints, real-world applications typically require processing significantly longer recordings with multiple utterances per speaker than seen during training. In this paper, we investigate how existing approaches perform in this challenging scenario and propose a frequency-temporal recurrent neural network (FTRNN) that effectively bridges this gap. Our FTRNN employs a full-band module to model frequency dependencies within each time frame and a sub-band module that models temporal patterns in each frequency band. Despite being trained on short fixed-length segments of 10 s, our model demonstrates robust separation when processing signals significantly longer than training segments (21-121 s) and preserves speaker association across utterance gaps exceeding those seen during training. Unlike the conventional segment-separation-stitch paradigm, our lightweight approach (0.9 M parameters) performs inference on long audio without segmentation, eliminating segment boundary distortions while simplifying deployment. Experimental results demonstrate the generalization ability of FTRNN for multi-utterance speech separation and speaker association.
Attractor-Based Speech Separation of Multiple Utterances by Unknown Number of Speakers
May 22, 2025This paper addresses the problem of single-channel speech separation, where the number of speakers is unknown, and each speaker may speak multiple utterances. We propose a speech separation model that simultaneously performs separation, dynamically estimates the number of speakers, and detects individual speaker activities by integrating an attractor module. The proposed system outperforms existing methods by introducing an attractor-based architecture that effectively combines local and global temporal modeling for multi-utterance scenarios. To evaluate the method in reverberant and noisy conditions, a multi-speaker multi-utterance dataset was synthesized by combining Librispeech speech signals with WHAM! noise signals. The results demonstrate that the proposed system accurately estimates the number of sources. The system effectively detects source activities and separates the corresponding utterances into correct outputs in both known and unknown source count scenarios.
Revisiting the Power of Prompt for Visual Tuning
Feb 04, 2024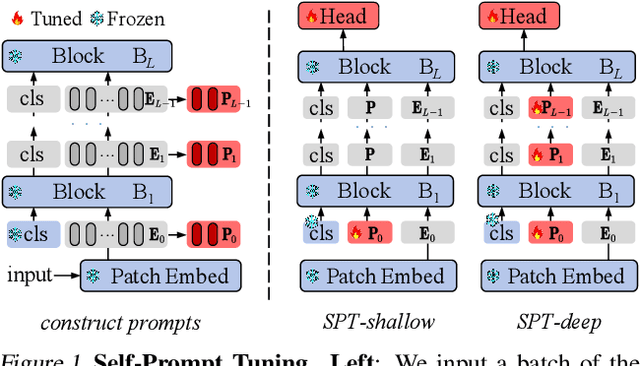
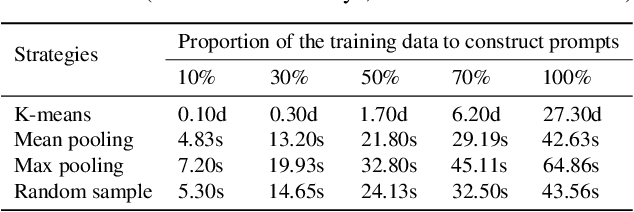
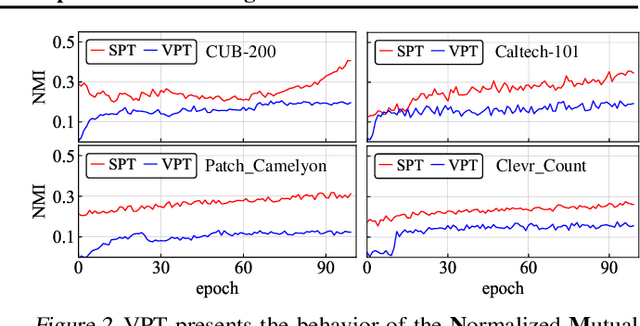
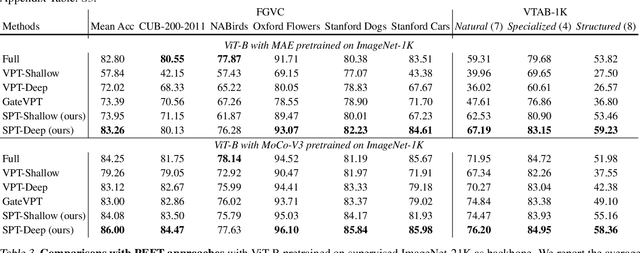
Visual prompt tuning (VPT) is a promising solution incorporating learnable prompt tokens to customize pre-trained models for downstream tasks. However, VPT and its variants often encounter challenges like prompt initialization, prompt length, and subpar performance in self-supervised pretraining, hindering successful contextual adaptation. This study commences by exploring the correlation evolvement between prompts and patch tokens during proficient training. Inspired by the observation that the prompt tokens tend to share high mutual information with patch tokens, we propose initializing prompts with downstream token prototypes. The strategic initialization, a stand-in for the previous initialization, substantially improves performance in fine-tuning. To refine further, we optimize token construction with a streamlined pipeline that maintains excellent performance with almost no increase in computational expenses compared to VPT. Exhaustive experiments show our proposed approach outperforms existing methods by a remarkable margin. For instance, it surpasses full fine-tuning in 19 out of 24 tasks, using less than 0.4% of learnable parameters on the FGVC and VTAB-1K benchmarks. Notably, our method significantly advances the adaptation for self-supervised pretraining, achieving impressive task performance gains of at least 10% to 30%. Besides, the experimental results demonstrate the proposed SPT is robust to prompt lengths and scales well with model capacity and training data size. We finally provide an insightful exploration into the amount of target data facilitating the adaptation of pre-trained models to downstream tasks.
Attention-Driven Multichannel Speech Enhancement in Moving Sound Source Scenarios
Dec 17, 2023Current multichannel speech enhancement algorithms typically assume a stationary sound source, a common mismatch with reality that limits their performance in real-world scenarios. This paper focuses on attention-driven spatial filtering techniques designed for dynamic settings. Specifically, we study the application of linear and nonlinear attention-based methods for estimating time-varying spatial covariance matrices used to design the filters. We also investigate the direct estimation of spatial filters by attention-based methods without explicitly estimating spatial statistics. The clean speech clips from WSJ0 are employed for simulating speech signals of moving speakers in a reverberant environment. The experimental dataset is built by mixing the simulated speech signals with multichannel real noise from CHiME-3. Evaluation results show that the attention-driven approaches are robust and consistently outperform conventional spatial filtering approaches in both static and dynamic sound environments.
Improving Knowledge Distillation via Regularizing Feature Norm and Direction
May 26, 2023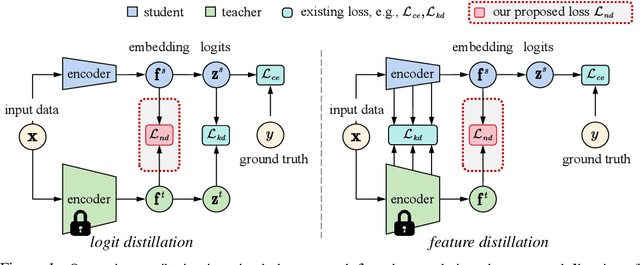
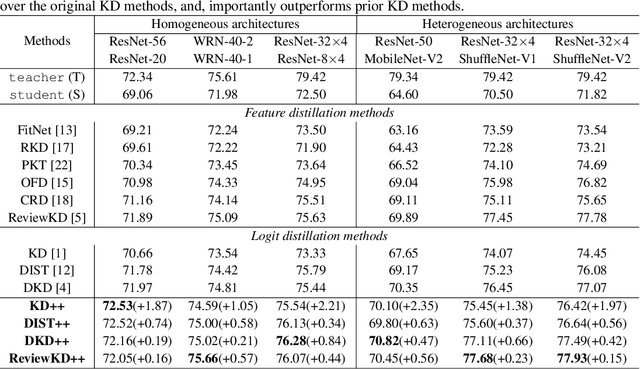
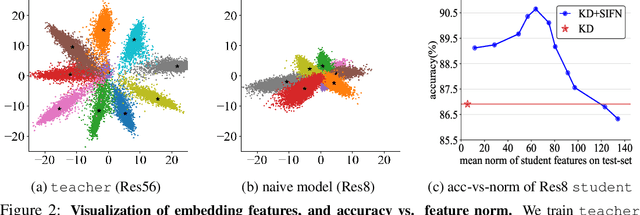

Knowledge distillation (KD) exploits a large well-trained model (i.e., teacher) to train a small student model on the same dataset for the same task. Treating teacher features as knowledge, prevailing methods of knowledge distillation train student by aligning its features with the teacher's, e.g., by minimizing the KL-divergence between their logits or L2 distance between their intermediate features. While it is natural to believe that better alignment of student features to the teacher better distills teacher knowledge, simply forcing this alignment does not directly contribute to the student's performance, e.g., classification accuracy. In this work, we propose to align student features with class-mean of teacher features, where class-mean naturally serves as a strong classifier. To this end, we explore baseline techniques such as adopting the cosine distance based loss to encourage the similarity between student features and their corresponding class-means of the teacher. Moreover, we train the student to produce large-norm features, inspired by other lines of work (e.g., model pruning and domain adaptation), which find the large-norm features to be more significant. Finally, we propose a rather simple loss term (dubbed ND loss) to simultaneously (1) encourage student to produce large-\emph{norm} features, and (2) align the \emph{direction} of student features and teacher class-means. Experiments on standard benchmarks demonstrate that our explored techniques help existing KD methods achieve better performance, i.e., higher classification accuracy on ImageNet and CIFAR100 datasets, and higher detection precision on COCO dataset. Importantly, our proposed ND loss helps the most, leading to the state-of-the-art performance on these benchmarks. The source code is available at \url{https://github.com/WangYZ1608/Knowledge-Distillation-via-ND}.